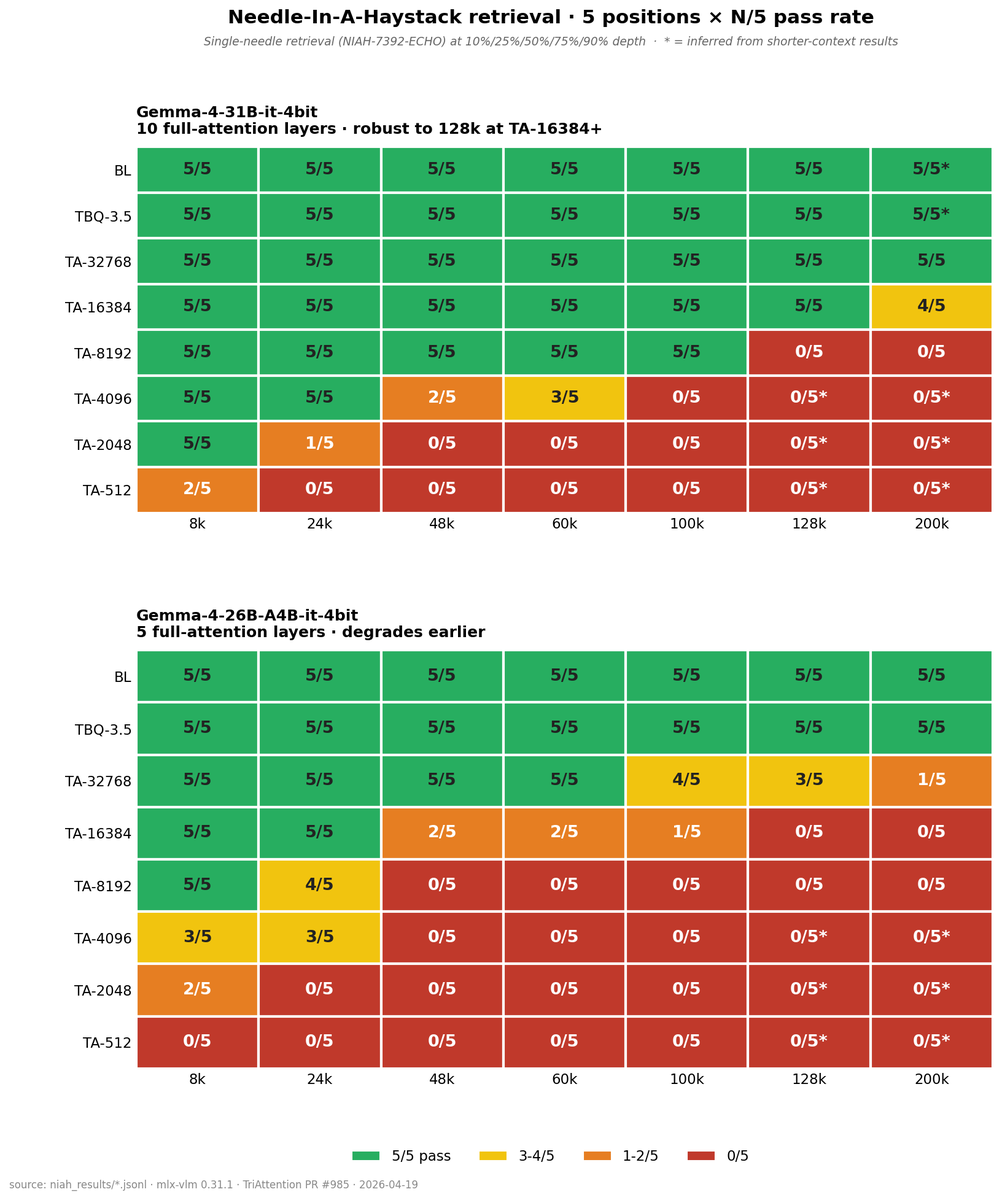
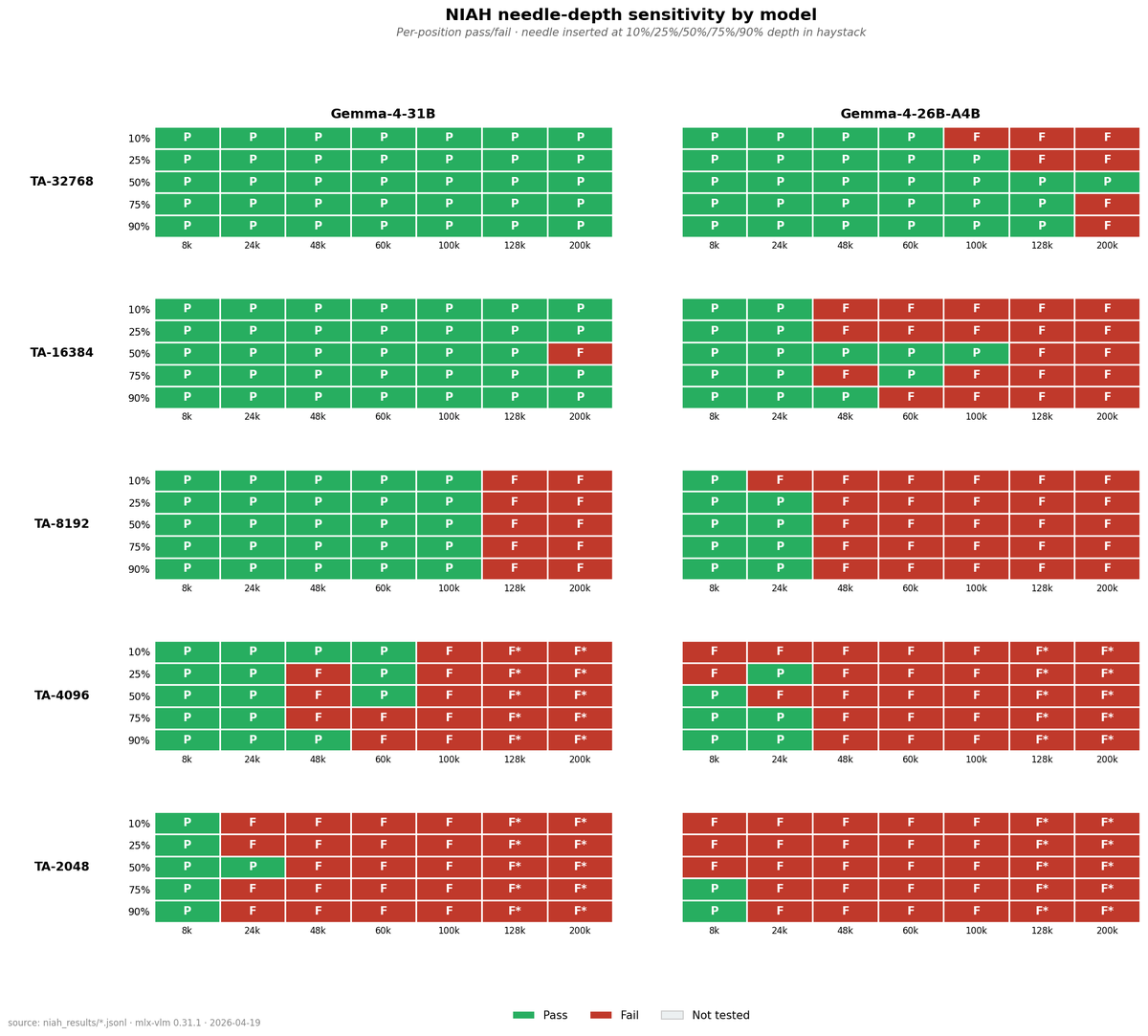
Update
- Added models: Marvis-TTS 100M/250M
- Streaming for: CSM-1B, Qwen3-TTS 0.6B, Chatterbox Turbo.
- Reduced streaming interval to 0.08s (single frame). Dropped TTFA dramatically.
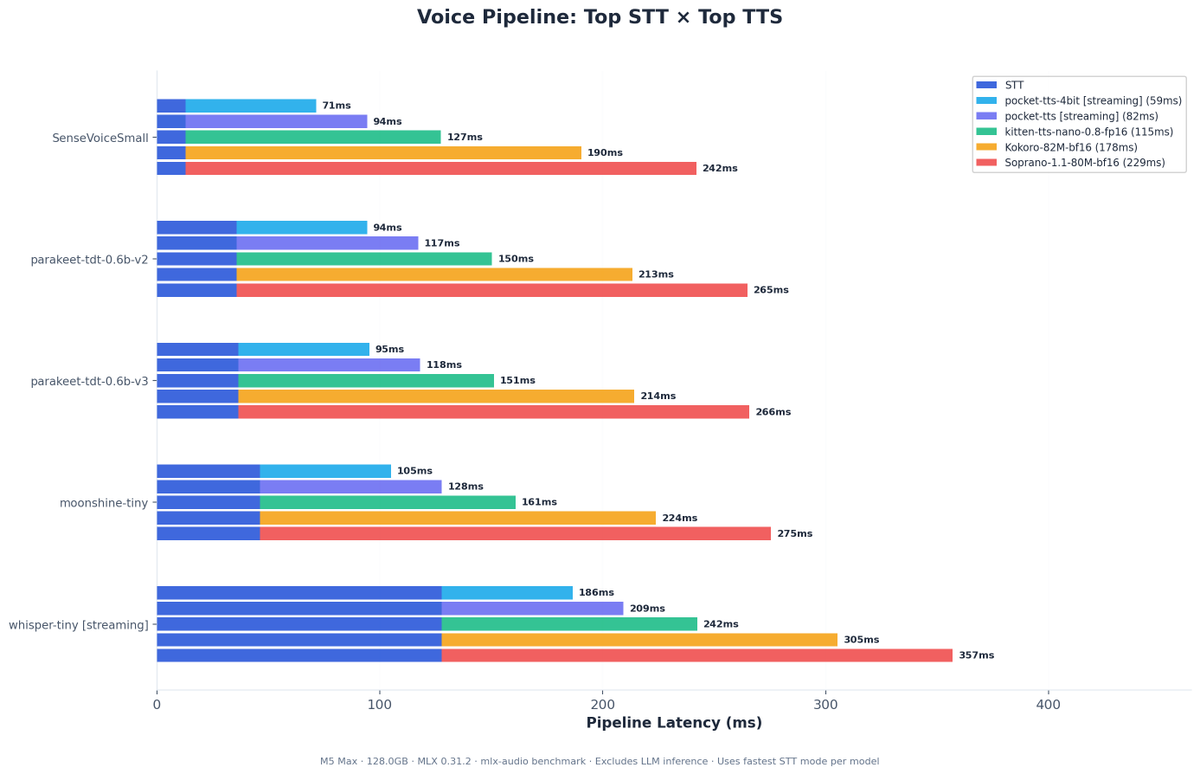
Fastest local voice pipeline: 71ms → 20ms (13ms STT + 7ms TTS).
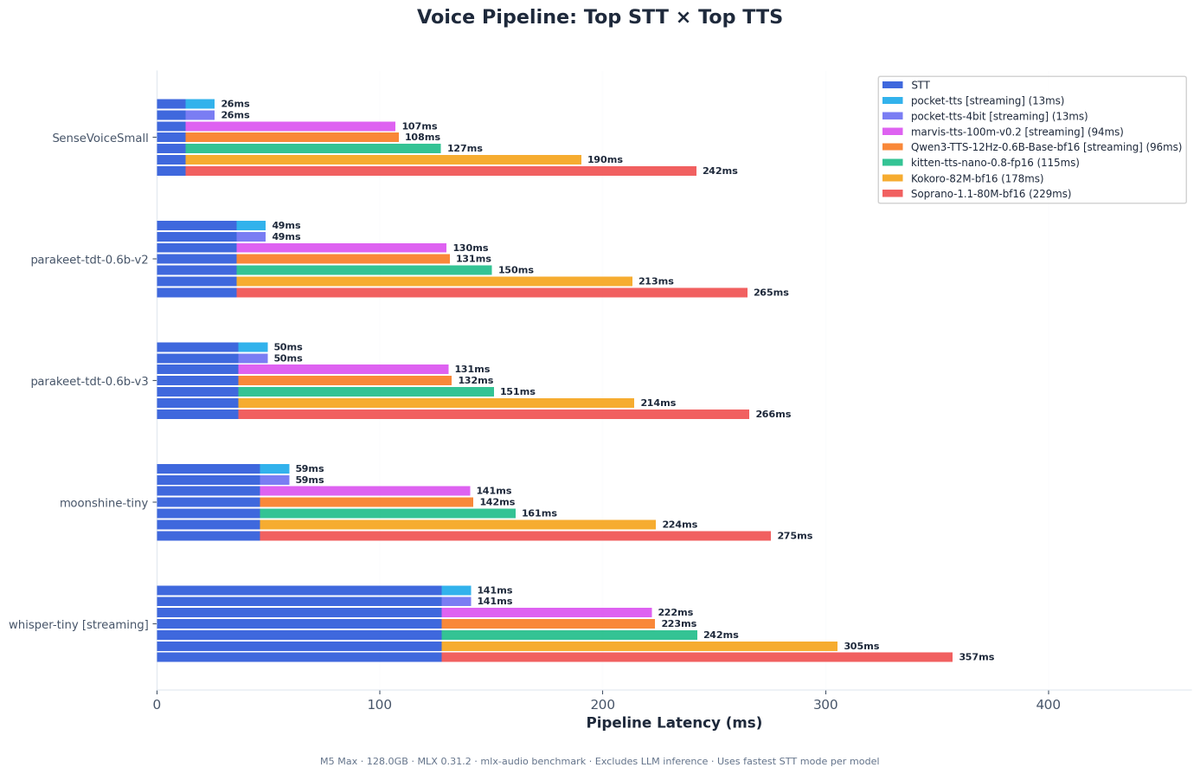



korale@korale77
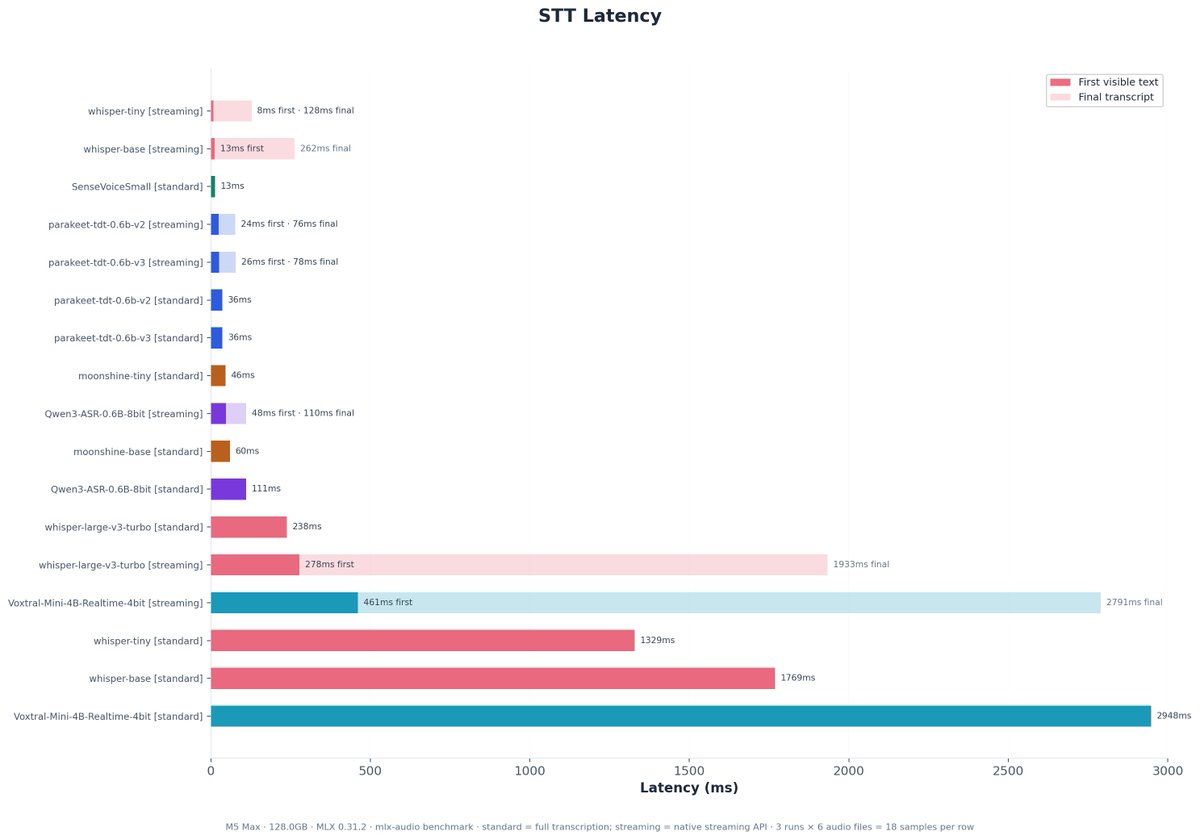
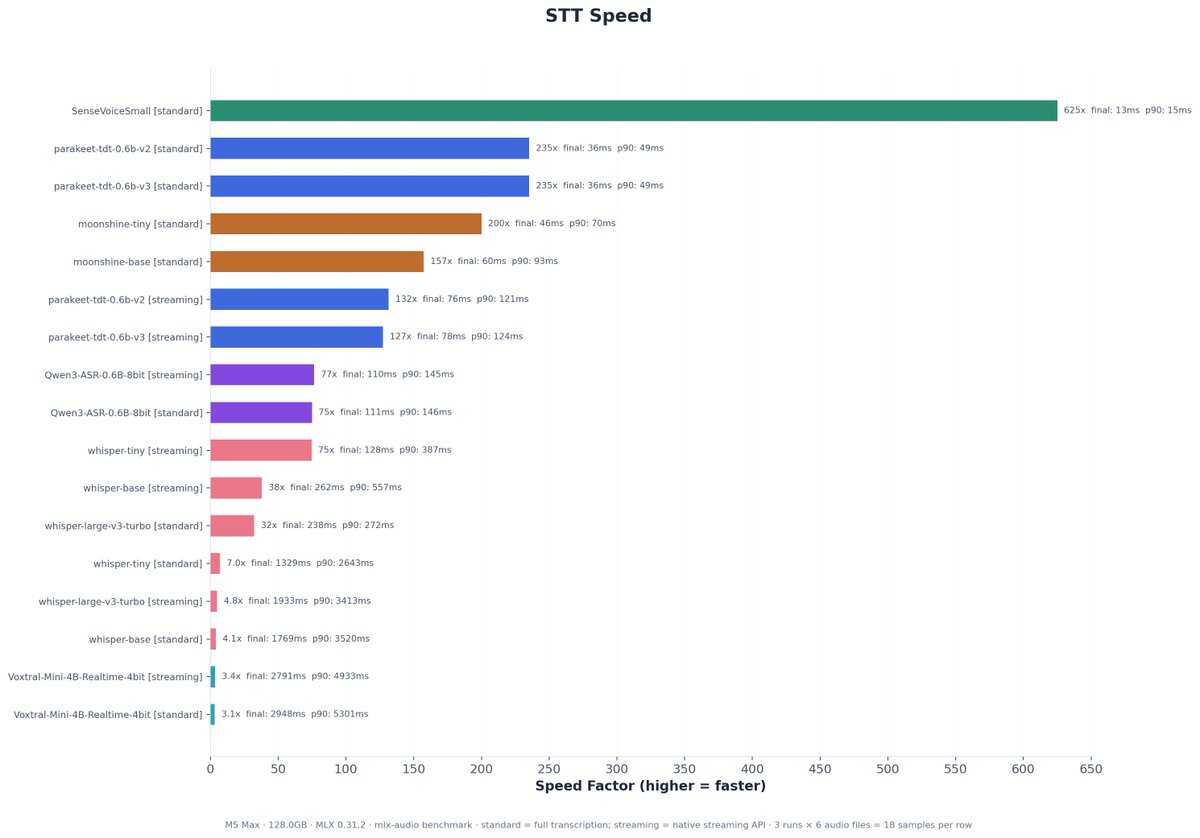
MLX-Audio benchmarks on M5 Max 128GB @Prince_Canuma @lllucas 10 STT and 19 TTS models (3 runs each) Lowest latency: SenseVoiceSmall (13ms) + pocket-tts-4bit stream(59ms) = 71ms Fastest: SenseVoiceSmall (625×) + kitten-tts-nano (112×) vs real-time Repo with details in replies
English