Utkarsh
306 posts


Utkarsh
@kumarukutkarsh
SDE-1 @ PeopleStrong | Java | Spring Boot | Python | Agentic AI | RAG | Flutter
Katılım Temmuz 2023
43 Takip Edilen33 Takipçiler
Utkarsh retweetledi

I have seen more systems struggling because of wrong code than slower ones. The fact remains, most engineers optimise too early.
About 8 years ago, my principal engineer once told me: Performance is almost always the last thing you should be thinking about. As an SDE-2, this did not make sense :) After a few follow-ups, I understood why he meant that.
The order that actually matters is this. First, is the code correct? Does it do what it is supposed to do? Second, can someone maintain it six months from now without wanting to quit? Third, is it fast to read and write? Only after all three does performance even enter the conversation.
The reason this order exists is simple. A fast, unmaintainable codebase is a liability. A performant-but-wrong system is worse than a slow, correct one. You cannot optimise your way out of a bug.
Now, this is not universally true. Databases, high-frequency trading systems, and real-time embedded software are domains where performance is a first-class concern from day one. But those are the exceptions, not the default assumption you should bring to every PR.
What is certainly true is that for most codebases, premature optimisation adds complexity, reduces readability, and solves a problem that does not exist yet.
So, write correct code first. Then clean it. Then, only if the profiler gives you a reason, make it fast.
English
Utkarsh retweetledi

As conversations get longer, you need guardrails around the core agent loop to manage long context without losing key information.
Agent middleware makes this easy for model and tool calls!
Sydney Runkle@sydneyrunkle
harness eng day 3: using middleware for context management for long running agents, you need periodic conversation history compaction so you don't overflow the context window @LangChain's SummarizationMiddleware compresses history automatically before it hits the model!
English

Now available in research preview on Pro and Max on macOS.
Enable it with /mcp. Docs: code.claude.com/docs/en/comput…
English

Utkarsh retweetledi

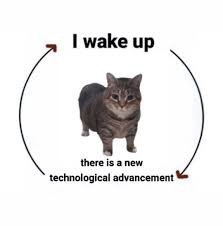
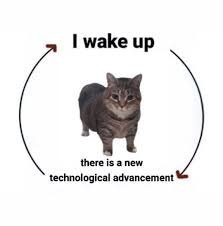
Will RAM become so expensive that we’ll be forced to actually write efficient software?
just like the early days of computing
English
Utkarsh retweetledi
Fun Fact: Stripe does logging differently. They take a super interesting approach to log processing, something that helps them debug production issues faster, cheaper, and with far less complexity.
Logging data belonging to one request is typically dumped across multiple lines. Stitching together these fragmented logs became a pain as they scaled. So what they do is emit a single, comprehensive log line at the end of every request, and they call it the Canonical Log Line.
I just published a video dissecting their entire process and the exact steps they took to implement canonical log lines without breaking their existing log processing systems.
Give it a watch.
It is a pretty short video, but interesting and fun. Something you can implement at your workplace right away.
English
Utkarsh retweetledi
Let me talk about something obvious but with a bit of quantification...
Theoretically, both arrays and linked lists take O(n) time to traverse, but here's what actually happens when you benchmark by summing 100k integers
- Array: 68,312 ns
- Linked List: 181,567 ns
Summing an array is ~3x faster than LinkedList. Same algorithm, same complexity, but wildly different performance.
The reason is cache behavior. When you access array[0], the CPU fetches an entire cache line (64 bytes), which includes array[0] through array[15]. The next 15 accesses are essentially free. Arrays hit the cache about 94% of the time.
Linked lists suffer from pointer chasing. Each node is allocated separately by malloc(), scattered randomly in memory. Each access likely requires a new cache line fetch, resulting in a 70% cache miss rate.
This is a good example of why Big O notation tells only part of the story. Spatial locality and cache-friendliness can make a 2-3x difference even when the theoretical complexity is identical.
I am sure you would have known this, but this crude benchmark quantifies just how fast cache-friendly algorithms can be.
Hope this helps.
English
Utkarsh retweetledi

You are hiring frontend engineer and you see this.
What do you do?
English
Utkarsh retweetledi

Today @GoogleMaps is getting its biggest upgrade in over a decade. By combining our Gemini models with a deep understanding of the world, Maps now unlocks entirely new possibilities for how you navigate and explore. Here’s what you need to know 🧵
English
Explored the world of game development with Flame, a game engine built on top of @FlutterDev. Built a basic 'Flappy Bird' game to understand the concepts of the library.
English
Utkarsh retweetledi
update: took me literally 5 mins to find the root cause and fix it.
Human 1 - AI 0
Arpit Bhayani@arpit_bhayani
debounce in dicedb not working, asked Claude to debug it, I agree database codebases are convoluted, but it has been 36 minutes, and bro is still thinking... time to debug it myself - let's see if I still have it in me.
English

@kumarukutkarsh @Filmora_Editor @screenstudio Hmm I see,
Checkout @cursorclip if it can work as per your needs?
English
If @Filmora_Editor comes with a @screenstudio like screen recording, I would get Filmora's lifetime license then.
English