
A
17 posts


@GNCLiveWell your PayPal checkout process needs an overhaul. I’ve never seen a login with PayPal that just checks you out without showing you final pricing before asking you to confirm. So now I have an order I didn’t authorize and I don’t want it.
English
@apoorvdarshan @mweinbach Probably not much. M silicon processors are very efficient.
English


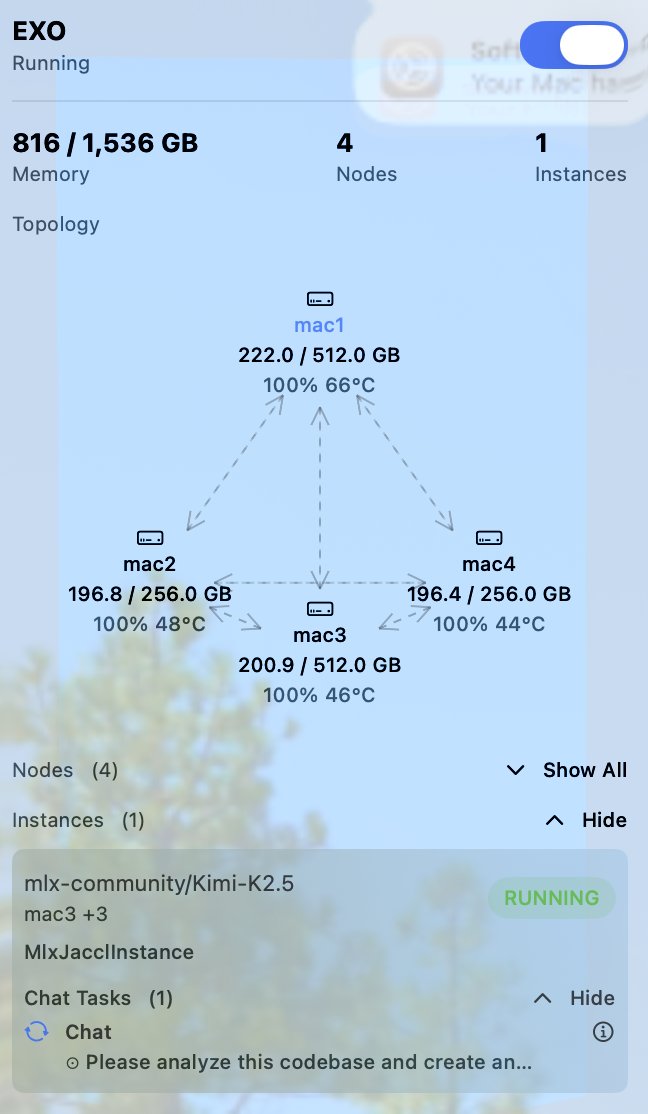
@ryanvogel 683GB but the problem is it saturated my entire network bandwidth so every other device was practically unusable
so this becomes a multi day attempt at finding when i can bottleneck everything else
English

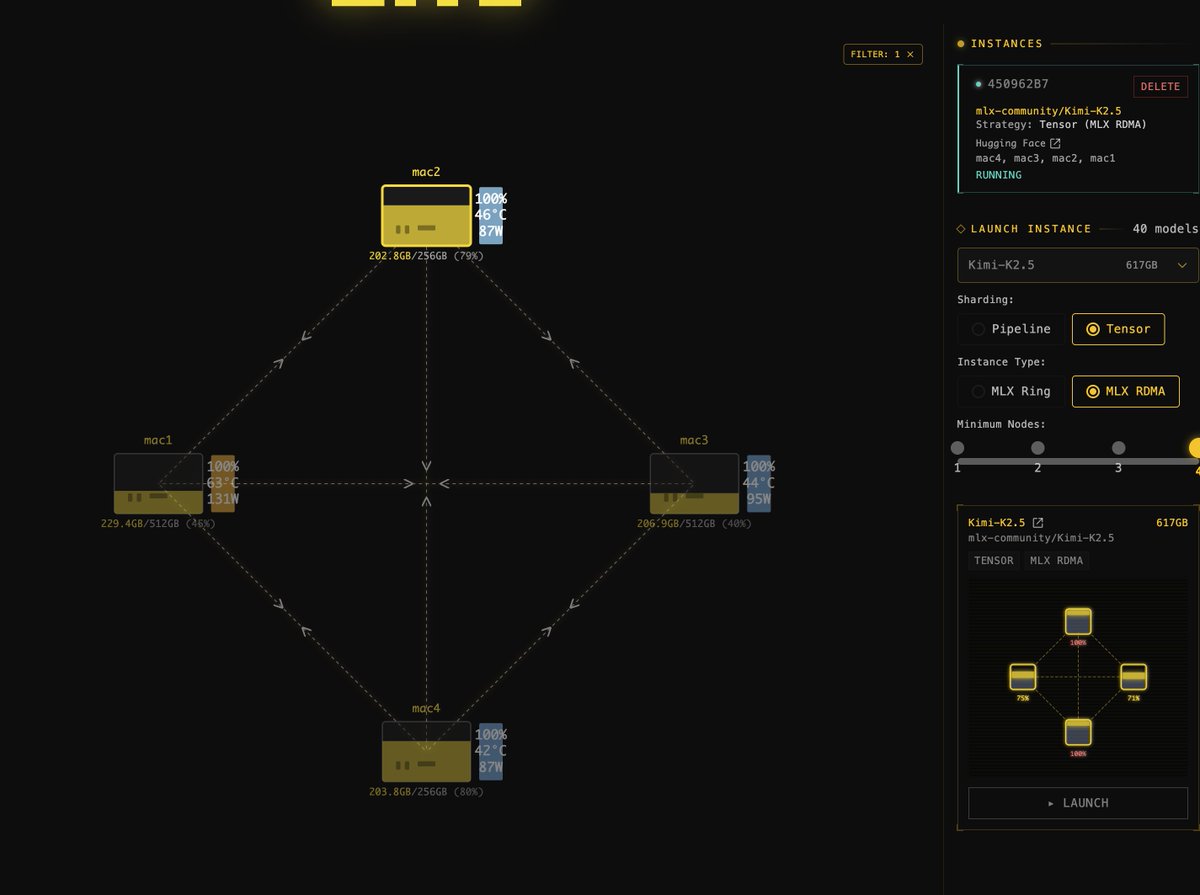
A retweetledi

Apple’s new M3 Ultra Mac Studio is a TRAINING POWERHOUSE
512GB unified memory, 800GB/s bandwidth, 43TFLOPS at fp16. With four of them ($38,000!), and you can fine-tune DeepSeek’s 671B MoE model overnight. 14k training examples, or 21.6 tok/s inference. Let’s see why:
DeepSeek R1 is a 671B parameter model, trained at 8-bit - so the full model is 671GB, able to fit on just two Mac Studios. Since DeepSeek is a Mixture-of-Experts model with only 8/256 active experts, in each forwards-pass of the model we only need to activate 37B parameters.
Firstly, in inference we are bound by memory bandwidth of the device. To do a single forwards-pass of the model we need to load 37GB of memory across two devices. Connecting the devices by Thunderbolt 5 (120Gbps) we get a theoretical token throughput of 800/37 = 21.6 tok/s.
Now for fine-tuning - since we need to store gradients as well as model parameters, we double the memory requirement - needing 4 Mac Studios this time. With a sequence length of 512, we need to calculate roughly 37B * 6 * 512 = 113 TFLOPs per training example. As a lower bound (if we consider only one machine acting at a time, and the others wait idle), that gives us 2.6s/train example. With some clever pipeline scheduling, training throughput could potentially be quadrupled.
So what does this mean? You could leave your $38,000 of 512GB M3 Ultra Mac Studios running overnight, and they could fine-tune over 14k examples. More than enough for a small-to-medium-sized fine-tuning run.
Benchmarks coming soonTM

English