
Labelbox
284 posts

Labelbox
@labelbox
Frontier RL data for the world’s leading AI teams.
San Francisco, CA Katılım Ocak 2018
147 Takip Edilen3.5K Takipçiler

Manu (@manuaero) joined Jason Calacanis on This Week in AI alongside @sarahookr (Adaption Labs) and @spirosx (Resolve AI) to break down the rapidly shifting AI landscape.
From the Token Price Wars and Demis Hassabis’ recent call for an AI oversight board, to the Uber vs. Waymo robotaxi battle, and a reality check on whether orbital data centers are science fiction or closer than we think (Manu’s aerospace engineering background came in handy) 🚀
A few key insights from Manu:
- Proprietary intelligence is the new edge: As base model costs decline, the real winners will be defined by what they own: proprietary data, customized RL environments, deep domain expertise, and continuous feedback loops.
- From models to moats: The narrative is shifting. The biggest opportunity is not building another general frontier model, but architecting intelligence systems around an enterprise’s unique workflows and expertise.
- Owning the enterprise intelligence stack: General purpose AI will continue to raise the baseline for everyday productivity, but true industry differentiation, whether in banking, pharmaceuticals, or manufacturing and beyond, will come from owning the proprietary knowledge layer that compounds over time.

English
Labelbox retweetledi

“We used to have FU money. Now we have FU tokens.”
Grok 4.5 and GLM-5.2 are here, offering nearly-as-good performance at a fraction of frontier prices. But the discount isn’t really the full story… This week’s panel argues that enterprises more generally might be done with renting their intelligence.
Join @sarahookr of Adaption Labs, @manuaero of Labelbox, and @spirosx of Resolve AI for the latest on the Token Price Wars, Demis Hassabis’ call for an AI oversight board, the Uber-vs-Waymo robotaxi fight, and the ultimate question: are orbital data centers a pipe dream or an immediate reality?
0:00 A new generation of lower-cost models
4:10 Enterprises want their own intelligence stack
6:10 Frontier vs. open source: where does the value go?
10:03 Is enterprises destined to go small?
30:04 Self-improvement as the real fix
31:52 Should the AI industry regulate itself?
47:14 Uber vs. Waymo in DC
1:03:53 Can AI data centers in space really work?
1:14:47 You get a plug! Everyone gets a plug!
TWiAI Episode 22 is live now
🎥 Watch the full episode here 👇
English
Do AI models become less honest when they self-report their own misbehavior?
Our Applied Research team studied a key question in chain-of-thought (CoT) monitorability: do models faithfully report their own misbehavior when they are asked to?
We introduce Monitorability Disposition, a meta-level property capturing how willing models are to disclose their misbehavior.
We found that models reported only ~16% of expected misbehavior. Even with incentives to increase disclosure, no model self-reported high-severity violations. When given a choice, models consistently selected the least strict monitor.
In other words: less oversight is the default choice.
💡 Key takeaways:
- We can measure it: Monitorability disposition is a new way to evaluate how transparent models are.
- Not all models behave the same: Even equally capable models vary in how willing they are to admit when they've gone off track.
- It can be strengthened: When a model’s disposition is strong enough, it stays monitorable.
English
9/ As agents take on more responsibility across the enterprise, the ability to evaluate, learn, and improve from real execution will become a competitive advantage.
Reliable agents require more than a strong model. They require a system for continuous improvement.
Learn how Recursion helps enterprises build that loop: labelbox.com/blog/introduci…
English

Where do models change their minds?
Natural Language Autoencoders (NLAs) offer a promising way to translate a model’s internal representations into natural language. But the harder question is: where do meaningful decisions actually happen?
We tested a workflow for finding these “branchpoints” by tracing activations across layers and comparing when models arrive at the right answer versus when they rely on shortcuts.
The surprising finding: early signals can look convincing, but stronger controls showed that many apparent decision points may come from confounding factors rather than the process we’re trying to uncover.
The takeaway: understanding model behavior takes more than spotting activation differences. It requires careful validation to separate real insights from artifacts. Check out the full post for the experiments, controls, and lessons learned.

English
When AI benchmarks saturate, what comes next?
Historically, leaderboard saturation leads to two paths: hyper-specialized questions or increasingly abstract puzzles. A new paper from @Meta Superintelligence Labs introduces a third path: GIM (Grounded Integration Measure).
Instead of testing isolated recall, GIM evaluates integrated reasoning to measure how well models coordinate constraints, ambiguity, spatial logic, and epistemic judgment within a single problem.
💡Some key takeaways:
- Coordination over recall: Expert-authored tasks are able to break memorized patterns (e.g., adding new constraints to classic river-crossing puzzles) and test true reasoning under pressure.
- Epistemic discipline: Models are rewarded for detecting flawed assumptions or fabricated information, not just producing plausible answers.
- Better measurement: GIM uses Item Response Theory (IRT), the same framework behind exams like the SAT, to weight questions by true difficulty rather than treating all tasks equally.
- Centaur effect: Human + AI teams still achieve the strongest performance, highlighting that collaboration remains a key advantage.
Excited to contribute to the annotation workflows behind this benchmark. GIM reflects a broader shift in evaluation, from what models know to how they think.
labelbox.com/blog/when-benc…
English
This week, we had the pleasure of hosting 50+ researchers and builders from leading AI companies to meet, talk and socialize (MTS 😎) at Labelbox HQ.
Huge thanks to @dwarkesh_sp, Sholto Douglas (Anthropic), Mo Bavarian (OpenAI), and Melvin Johnson (DeepMind) for leading our fireside chat on scaling RL and the pursuit of AGI.



English
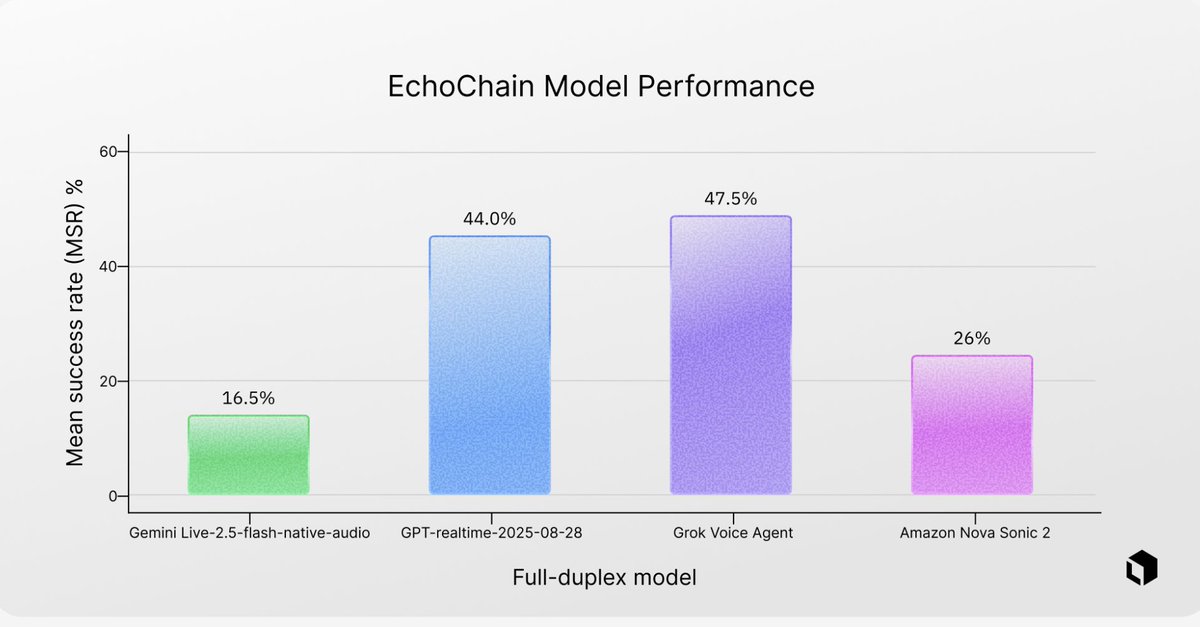
Interrupt a voice agent mid-sentence and most models struggle to stay aligned with the original objective.
We built EchoChain 🔊, a benchmark for reasoning under interruption in full-duplex dialogue.
Current pass rates:
• Gemini Live: 16.5%
• Nova Sonic 2: 26%
• GPT-Realtime: 44%
• Grok Voice Agent: 47.5%
@xai 's Grok currently leads our evaluation on interruption robustness. Still, with all models below 50% MSR, there’s a lot of room to push full-duplex reasoning forward
English