
Landan Seguin
14 posts

Landan Seguin retweetledi

today we're announcing our @DbrxMosaicAI x @Shutterstock partnership, and a new text-to-image diffusion model: ✨ImageAI!!✨
this model is geared towards enterprise use cases and is trained exclusively on shutterstock's trusted data catalog!
databricks.com/company/newsro…

English
@ilyas121_real @summerlinARK @Replit @amasad @MosaicML Our SD training estimates are in the blog post below: $160k in 2 weeks. Next, we will train the thing :) watch out for it! twitter.com/MosaicML/statu…
Databricks AI Research@DbrxMosaicAI
How much does it take to train a Stable Diffusion model from scratch? The answer: 79,000 A100-hours in 13 days, for a total training cost of <$160k. Our tooling reduces the time and cost to train by 2.5x, and is also extensible and simple to use. mosaicml.com/blog/training-…
English


.@Replit & @amasad are writing the playbook on building an AI-first company. With @MosaicML, the cost to train your own model is de minimis. I.e., you can train Stable Diffusion on MosaicML for $160k. Other reasons to train your own model: inference cost/speed, data privacy, etc.
Amjad Masad@amasad
“To paraphrase Alan Kay, perhaps people who are really serious about product should make their own models.”
English
Landan Seguin retweetledi

Just in time for Thanksgiving - we're dropping a new batch of recipes for training image segmentation models. Reduce time-to-train by up to 5.4x, improve quality by up to +4.6 mIoU, and impress everyone at your #efficientML potluck!
mosaicml.com/blog/mosaic-im…
English
Landan Seguin retweetledi
New blog post: mosaicml.com/blog/behind-th…
We're setting an up-to-date baseline for semantic segmentation model training: 45.56 mIoU on the ADE20k benchmark in 3.5 hours using 8x NVIDIA A100 GPUs.
Next step: develop and release #EfficientML recipes to speed it up!
English
Landan Seguin retweetledi

Having trouble keeping up with arXiv?
🎉 Announcing "Davis Summarizes Papers" 🎉
tl;dr: People kept telling me I should make the ~15 paper summaries I do each week into a newsletter, so I did: dblalock.substack.com
Free forever, and you can also read all past posts as a blog
English
Landan Seguin retweetledi
We've shared great research before, but reproducing methods from papers is hard.
Announcing Composer, our library of ML speedups: github.com/mosaicml/compo….
Train CV models ~4x faster and NLP models ~2x faster at the same accuracy -- with minimal tuning. (1/5)

English
Landan Seguin retweetledi

TLDR: Announcing 🌟COMPOSER🌟, a PyTorch trainer for efficient training *algorithmically*. Train 2x-4x faster on standard ML tasks, a taste of what's coming from @MosaicML. Star it, 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 𝚖𝚘𝚜𝚊𝚒𝚌𝚖𝚕, contribute, be efficient! github.com/mosaicml/compo…
Thread:
English
@borisdayma Nice! At @MosaicML, we’ve seen significant differences in perplexity when training a GPT-2 model on OpenWebText with vs without dropout! Look forward to seeing your results 😁

English

Do you still use regularization even when your dataset is huge?
I was still using dropout while my dataset won't get processed more than 2-3 epochs (I also have a large batch size).
Let's see what happens🤞
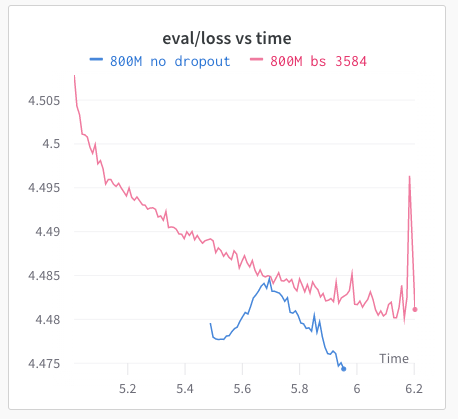
English
@johncarlosbaez I found this talk (and many others) by Alan Watts enlightening youtu.be/mMRrCYPxD0I (start at 1:26, ignore the cheesy music and video)
"So after you are dead, the only thing that can happen is the same experience, or the same sort of experience as before you were born"

YouTube
English
Landan Seguin retweetledi

Left: MIT computer scientist Katie Bouman w/stacks of hard drives of black hole image data.
Right: MIT computer scientist Margaret Hamilton w/the code she wrote that helped put a man on the moon.
(image credit @floragraham)
#EHTblackhole #BlackHoleDay #BlackHole


English
Landan Seguin retweetledi

Landan Seguin retweetledi

@michael_nielsen @TheAtlantic It's frustrating how thinking feels like exploring a large idea cave serially with a tiny flashlight. It's a bit shocking how underdeveloped our tooling is in surpassing limitations of thinking / short term memory. Pen & paper was a good first step, haven't taken too many since.
English