Sabitlenmiş Tweet

so i lowballed 100s of luxury watch dealers in the USA using a voice AI and managed to negotiate $15k off MSRP for a Daytona
youtube.com/watch?v=ohQrh3…

YouTube
English
Tony Ge
380 posts

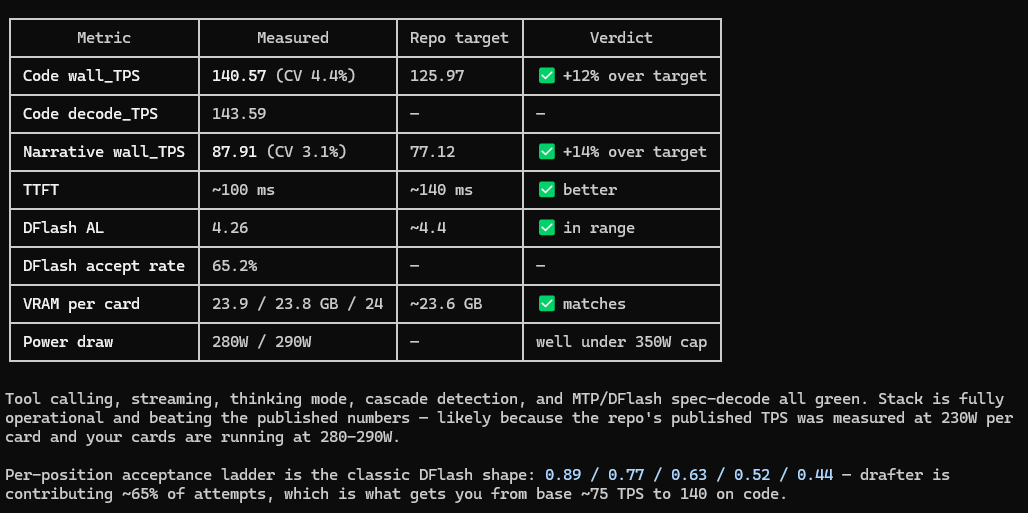
Breaking LLM inference’s autoregressive bottleneck 🛠️ We've teamed up with @haozhangml, @YimingBob, and @aaronzhfeng, among others from UCSD to achieve a massive 3.13X speedup for LLM inference on Google Cloud TPUs using Diffusion-Style Speculative Decoding (DFlash). Read the blog: goo.gle/4naZ8Yv

Meta ads CLI + auto researcher + GPT-2 image + $1000 ad spend would probably print







respect the take but I think this is incorrect. instead, I recommend people to get a 3090: durability: 3090s run for years with basic maintenance. swap the gddr6x thermal pads every couple years and the card is basically immortal. just don't buy one that lived its life in a mining farm and you're fine power: 3090 pulls 350W. 4090 is 450W, 5090 is 575W, 7900 XTX ~355W. the 3090 is the LEAST power hungry card in its bandwidth tier. wrong completely !! heat: same story. every card at this performance level runs similar temps. not a 3090 problem price: used 3090s are $800-1000 today. launch was $1499. that's nowhere near launch price, and it's still the best $/GB-vram and $/GB-bandwidth on the market by a wide margin. 4090 is $2,500. 5090 is $3,500 the real recommendation depends on your use case. need more than 24GB of vram? skip the 3090 and go for a Mac Studio / DGX / Strix Halo. running qwen3 27b at high throughput on a budget? absolute best card on the market, no contest! ideally? you get both
openclaw is super bloated updating takes forever restarting gateway takes forever this is not what it used to be like...















