
Layla CryptoWhiz
3.9K posts

Layla CryptoWhiz
@laybitcoin1
🌐 Blockchain fanatic & your guide to financial markets 💸
Amman Katılım Mayıs 2023
348 Takip Edilen96 Takipçiler

@ThiagoJ95477314 @TheARCTERMINAL Most AI still resets every session like a game with no save file. Continuity is the real challenge.
English

Grand Rising ⛅
Most AI systems can answer questions.
Very few can build real continuity over time.
ANIMA by @TheARCTERMINAL is designed around persistent intelligence with two distinct memory layers that evolve alongside the user.
◈ Identity Memory
Learns who you are over time your goals, interests, workflows, and preferences creating connected context across every interaction.
◈ Context Memory
Preserves conversations, research paths, and ongoing threads with retention fully under your control.
The result is an AI system that becomes more aligned and more useful the longer you use it.
Not just a chatbot with memory.
A persistent agent built to evolve with its user.

English
@CurieuxExplorer We optimize phones, apps, everything... still store food in plastic. Glass and steel seem obvious.
English

A Very Humpy Wednesday 🐫
672 ⤵️ ChatGPT Image 2 → Runway → Seedance 2.0
English
@Chi_Wang_ buidl > talk. realtime multi-model agents are the real experiment.
English

Can't wait to test the new model in Sutando — my AI Stand has been doing this and more since March on my Macs, combining multiple models in realtime. Voice, screen, meetings, phone calls, sub-second. Always on. And it ships its own code while I sleep. github.com/sonichi/sutando
Thinking Machines@thinkymachines
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. thinkingmachines.ai/blog/interacti…
English
@freeCodeCamp @programmingoce GPT-2 was the moment people realized scale alone can unlock behavior. Just predict the next token... and suddenly you get translation, QA, summarization.
English

GPT-2 changed AI research by showing that scale alone can unlock new capabilities.
In this paper review, @programmingoce explains how unsupervised next-token prediction led to translation, summarization, and question answering behaviors.
You'll learn about transformers, zero-shot learning, and why GPT-2 mattered historically.
freecodecamp.org/news/ai-paper-…

English
@lmsysorg 2x acceptance from a normalization fix is wild. Small architectural details still run inference.
English

🔬 Loved this one. Drafters lose their attention sink as hidden-state magnitudes grow with each speculation step. Move RMSNorm, and the drafter learns to be a depth-independent predictor instead of stacked verifier layers.
The result: 2× acceptance under perturbation, 1.18× long-context, 30% lower training cost ⚡️
GPT-OSS speculative decoding models with up to 50% throughput on long context + large batches are day-0 ready on SGLang
Thanks @dogacel0 and team for the great work!
Doğaç@dogacel0
As a part of our research, we are releasing the fastest GPT-oss speculative decoding models out there, increasing throughput up to 50% on long context and large batches! huggingface.co/collections/Do… Available on day-0 with SGLang ! Huge thanks to @sgl_project @lmsysorg 🙏🏻
English
@rileybrown Agents will eat a lot of SaaS. But whoever controls the agent layer controls everything.
English

And I’m not talking about point of no return to Claude Code. If they release a model that’s better, great.
I’m talking about using an agent interface (super-app) for ALL tasks.
I don’t go to a browser anymore. I don’t go to email. I don’t go to notion.
Every task that is started is kicked off via an agent chat.
I believe over the next year this is inevitable for all knowledge work.
If your app doesn’t open in the superapp browser you may be…
Cooked.
Riley Brown@rileybrown
I've reached the point of no return. I'm officially doing 95% of my work on Codex.
English
@MattHartman @huggingface APIs made people forget the basics. No data, no model.
English

Datasets are the biggest barrier to people training their own AI models. It took 4 years for @huggingface to reach the first 500k datasets and 8 months to cross 1m.
clem 🤗@ClementDelangue
We just crossed 1,000,000 public datasets on Hugging Face! That's petabytes of data available that millions of AI builders are downloading, analyzing, and training AI models on every day! What's interesting is that we see a clear acceleration since agents started to be good as the number of datasets doubled over the past 8 months (it took 4 years to reach the first 500k). It's becoming easier and faster to build, share and use your own datasets! Many are saying the next bottleneck for more people to build AI themselves (instead of relying on APIs) is better data so we're just getting started! Thanks everyone for your amazing contributions, we couldn't do it without you!
English
@clattner_llvm People obsess over the model. Real builders obsess over latency. 420ms TTFT changes the whole product.
English

Learn more about the technology that enables Inkwell to be dynamic and interactive on the modular blog:
modular.com/blog/inkwell-w…
English
I built a story and you can too! Check out "The Carbonated Crisis": inkwell.modular.com/shared/the-car…
This is built by Modular's free demo, using lightning fast image and text generation to build interactive storybooks. It's a fun and interactive, check it out! 👇
Modular@Modular
Our cofounder @iamtimdavis built an AI storybook app using @BlackForestLabs' FLUX2 and @googlegemma 4 on Modular Cloud. Pick a character, make choices, and the story branches endlessly, with every page written and illustrated in real time. Tim has spent his career obsessing over inference latency, first at Google, now at Modular. Building something his kids use settled it: in a real-time generative app, the inference platform determines the experience as much as the model. The numbers back that up. From 24 hours of production traffic: first prose in 420ms, a full illustration in under 6 seconds, 85% of page turns in 48ms. Create your own story with Inkwell and share it. We're sending swag to our favorites: inkwell.modular.com
English
@SujalJethwani People chase 10x gains. Then they discover 100% losses.
English

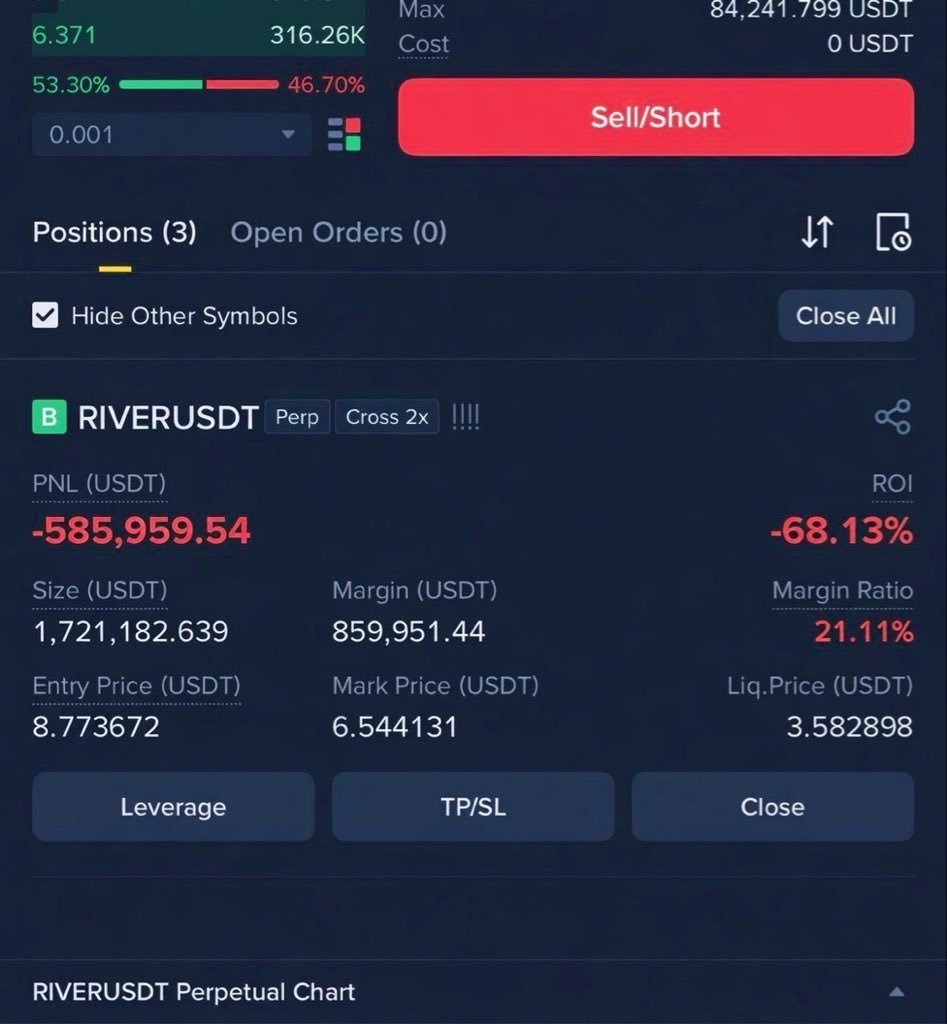
This trader lost $500K on a leveraged position is now hospitalised
If RIVER drops to $3, his loss could cross $1 million
One bad position can destroy
your capital
your mental health
your entire life savings
Leverage trading without risk management is brutal
English
@janbtc YouTubers for content. Robotics labs for research. Early tech always looks ridiculous until it isn’t.
English

@TheHackersNews Agent with email + terminal access? That's basically lateral movement as a feature.
English

🤖 Agentic AI is already running in production while security teams treat it as a policy issue.
You can’t secure what you don’t understand. Three agent types — one now lets anyone build powerful agents with real access, no code needed.
Read about it: thehackernews.com/2026/05/why-ag…
English
@Amank1412 Parallel agents. One control panel. We are basically supervising systems that code now.
English

Anthropic just turned Claude Code into an agent command center.
Launch multiple agents in one go and watch them run in parallel without cluttering your terminal.
Now available on all paid plans.
Claude@claudeai
New in Claude Code: agent view. One list of all your sessions, available today as a research preview.
English
I’m watching AI shift from 'best model' to 'best system'. Context, tools, orchestration. No surprise the UAE keeps investing in the full AI stack.
English
Layla CryptoWhiz retweetledi

Call for Exhibitors!
15th World Digital Pathology, Diagnostics & AI UCG Congress & Exhibition, scheduled for February 01–02, 2027 Dubai, UAE.
Register Now: …lpathology.utilitarianconferences.com/registration
WhatsAp: wa.me/+9715517929
#DigitalPathology #AIDiagnostics #HealthcareInnovation

English
@pseudokid 11k vs 1k first turn says everything. Most agents just burn context like it's free.
English

Whole day with Pi agent just used 10% of my $20 Codex weekly quota
All gpt 5.5, various thinking levels
I'm now 3 hours away from weekly reset and still have 42% left!
For my typical 4-6h/day session:
Codex Desktop - 20-30% a day, 1-2 days/week
Pi - 10% a day, 4-5 days/week?
My switch to Pi is really looking good so far
raymel 👋@pseudokid
Pi Agent vs OpenCode token usage A lot of people recommended Pi Agent so I decided to check Pi Agent took 1.1k tokens in first turn OpenCode took 11.5k Setup: 1) Trimmed OpenCode (from usual 30k first turn to 11.5k) - 0 MCPs - 2 lightweight plugins (opencode-env-protect and openslimedit) - 8k char AGENTS.md - 11585 deepseek-v4-flash input tokens - for $0.0016 2) Vanilla Pi - 0 MCPs - 0 system prompt - 8k char AGENTS.md - 1114 kimi-k2.6 input tokens - for $0.0008 I think using better models with capped tokens per turn can keep usage nearly the same as uncontrolled DeepSeek V4 Flash? The challenge now is finding the sweet spot. Can't cap tokens if quality drops. We'll see. Video below - OpenCode vs Pi side by side "say hi back" first turns test, with OpenCode Go usage for each
English
@Javedofficial0 @quipnetwork Accessibility is the real bottleneck in deep tech. If a normal laptop can participate, that changes things. But words are cheap. Show the architecture.
English

What @quipnetwork is doing with quantum participation feels refreshingly practical compared to most deep tech projects in this space
Instead of building something that only specialists can access the system is designed so everyday users can actually take part without friction
A regular laptop is enough to get started no need for expensive hardware lab setups or advanced technical knowledge
The heavy lifting is handled through a hybrid architecture that abstracts away the complex quantum layey so users do not have to interact with it directly
Everything runs in the background while the experience stays simple and usable
For developers integration is also kept lightweight
There is no need to rebuild workflows or deal with overly complicated pipelines which lowers the barrier for experimentation and adoption
The overall direction is clearly focused on usability over complexity making decentralized quantum infrastructure feel more realistic and accessible instead of theoretical
It is a strong step toward making advanced compute actually usable in real applications

English
@Diesol Artists existed before cameras too. Tools still changed everything.
English

I’ll say it once again. Most people creating compelling films with AI tools were artists, storytellers and filmmakers well before. But if it makes you feel better, go off.
English
Layla CryptoWhiz retweetledi

“At some point people will realize that they have more to fear by not embracing this technology than by embracing it.”
Michael @Saylor on Bitcoin
English
@pmarca People assume more load means higher power bills. With fixed grid costs it can be the opposite. Flexible AI data centers spread the cost.
English

New datacenters can lower electricity prices.
Ben Schifman@BenSchifman
Narrative violation: with the right policy, new data centers can *lower* electricity prices by spreading the fixed costs of the grid out among more paying customers.
English