Sabitlenmiş Tweet

Allow me to introduce my "selves"
Art director and design engineer
Open to work!
GIF
Seiten, Taisei@lekandev
First design of the year
English
Seiten, Taisei
4.5K posts
@lekandev
Oh Captain! My Captain!
First design of the year





Compiling a resource document for anyone seeking to learn and master how to design, build and ship with AI. I’m I’ll say about 80% done. Just need some more. Suggest at least one of these. 1. YouTube videos you feel are useful. 2. X accounts to follow to be updated an inspired by the AI trend 3. Podcast to listen to 4. Tools to use 5. Articles on designing and building with AI
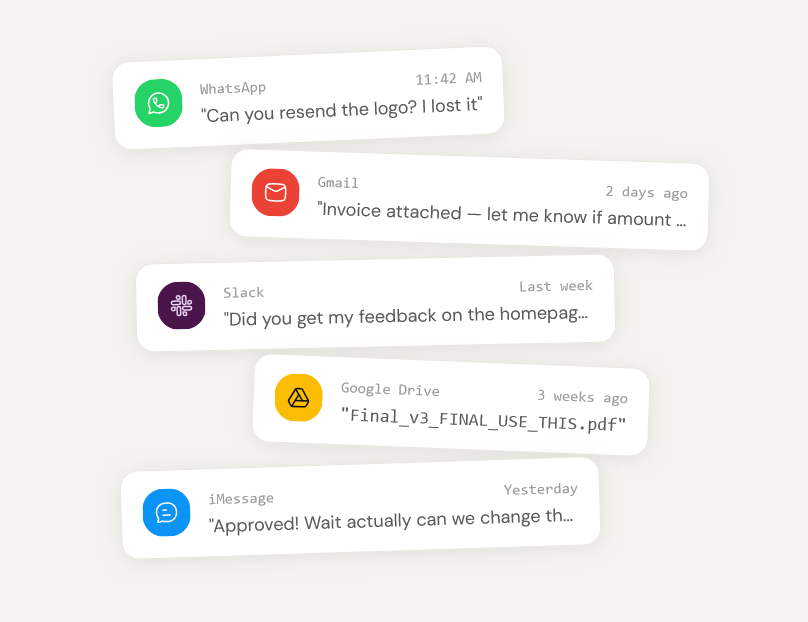
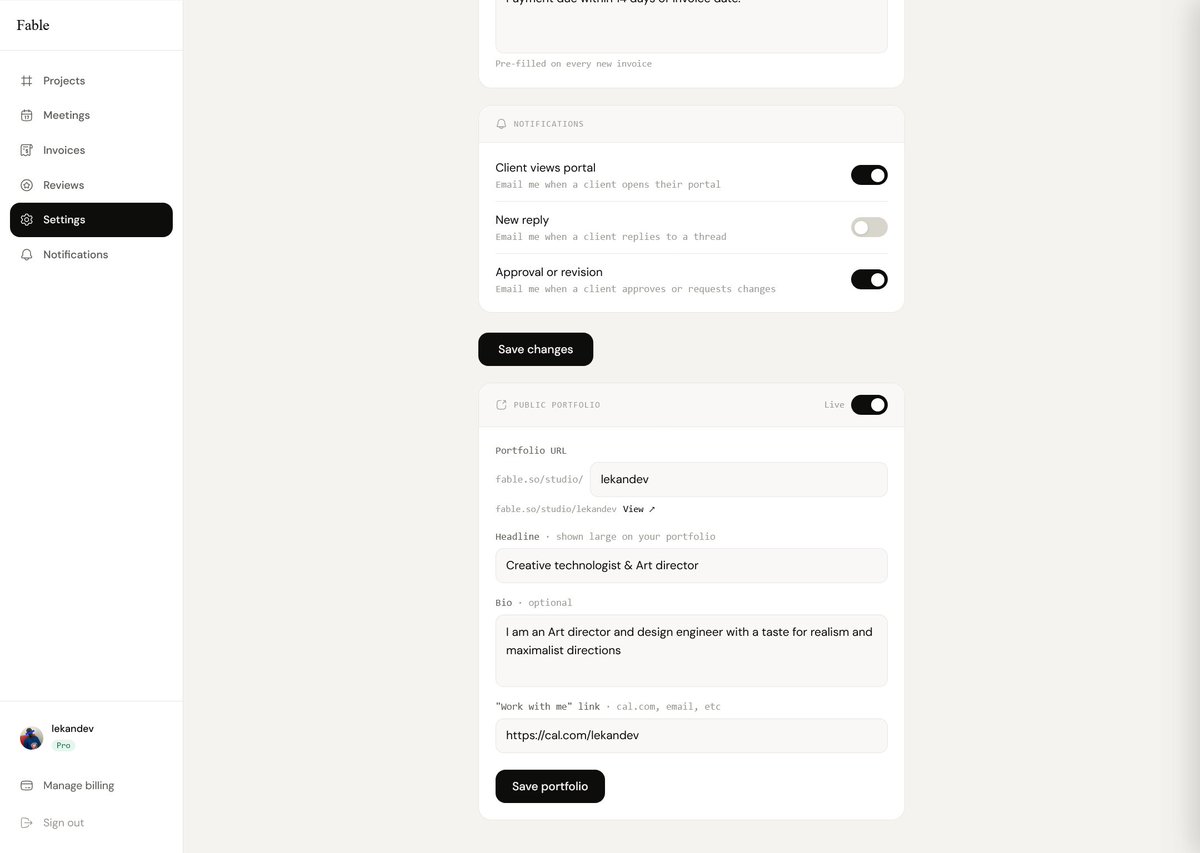
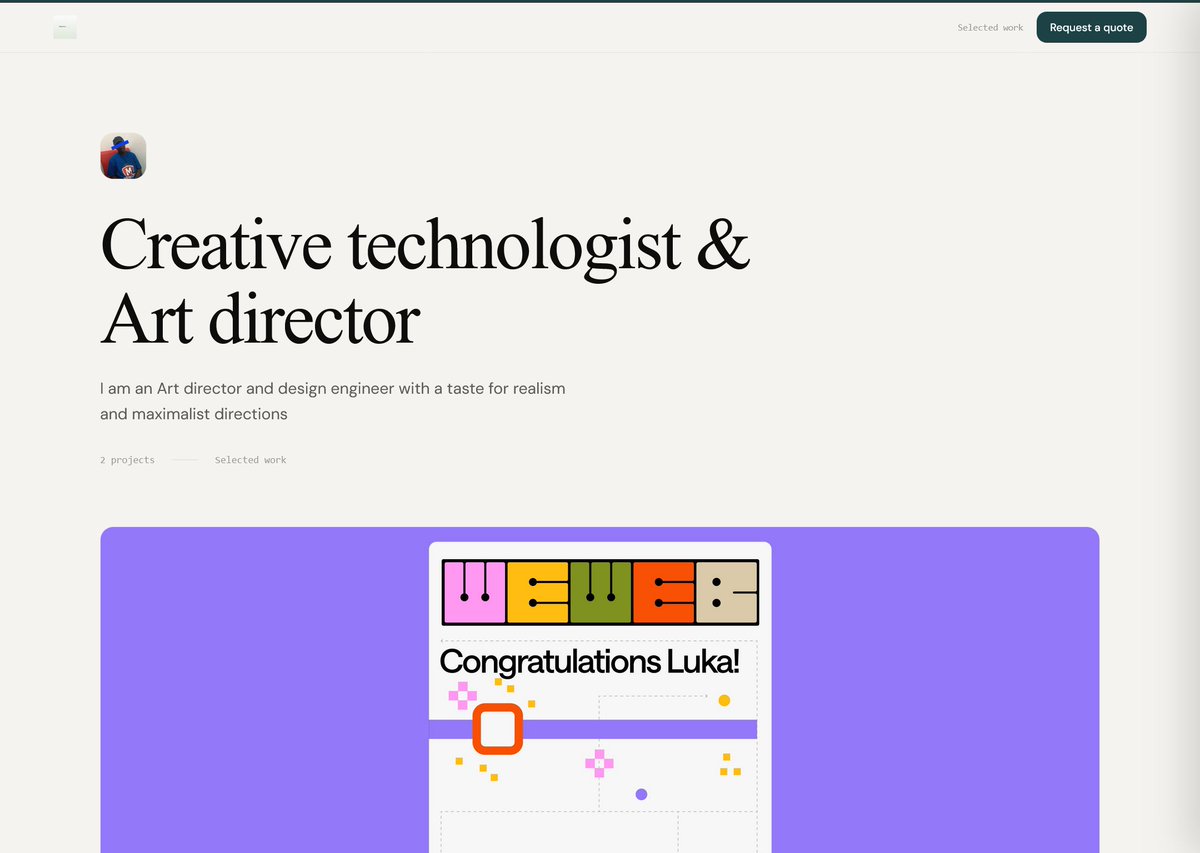
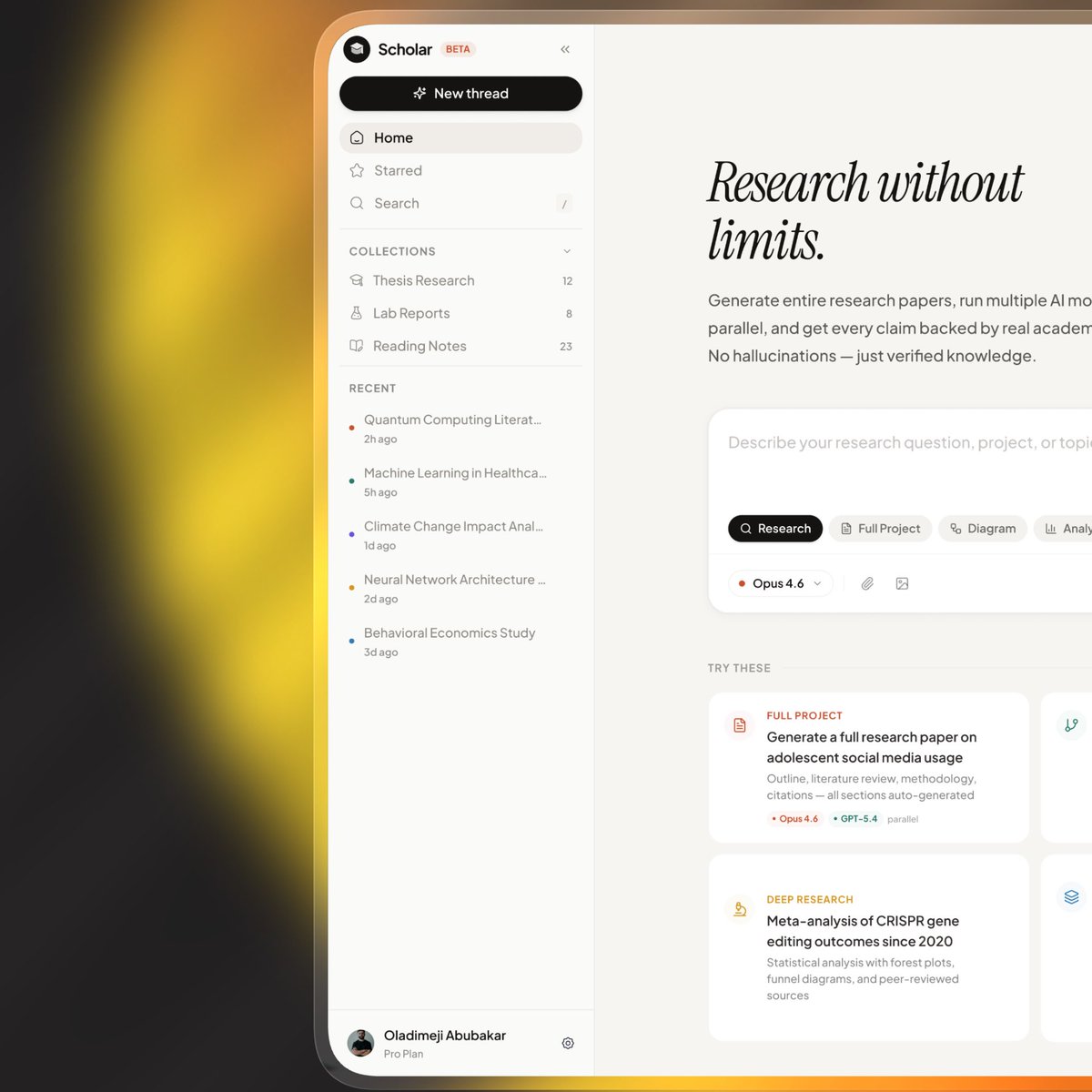
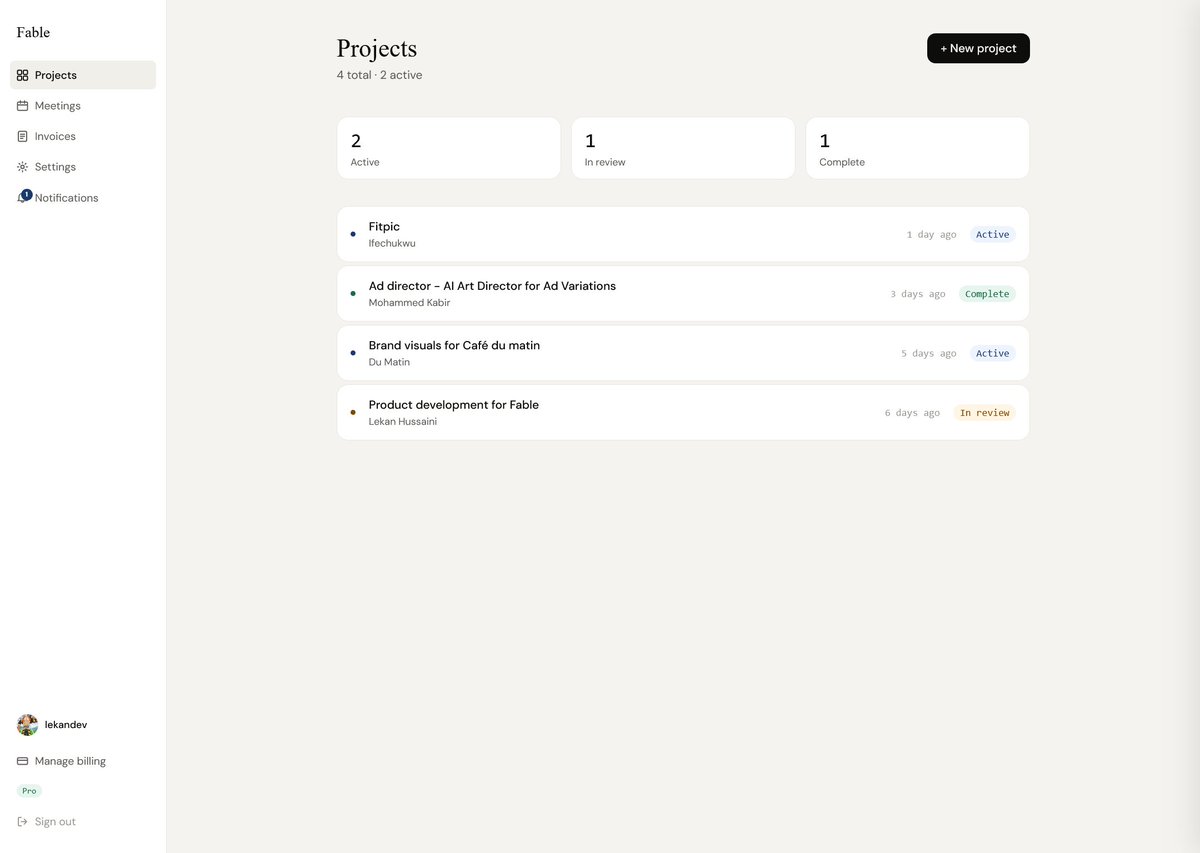
Deliverables checklist and invoice view in project page

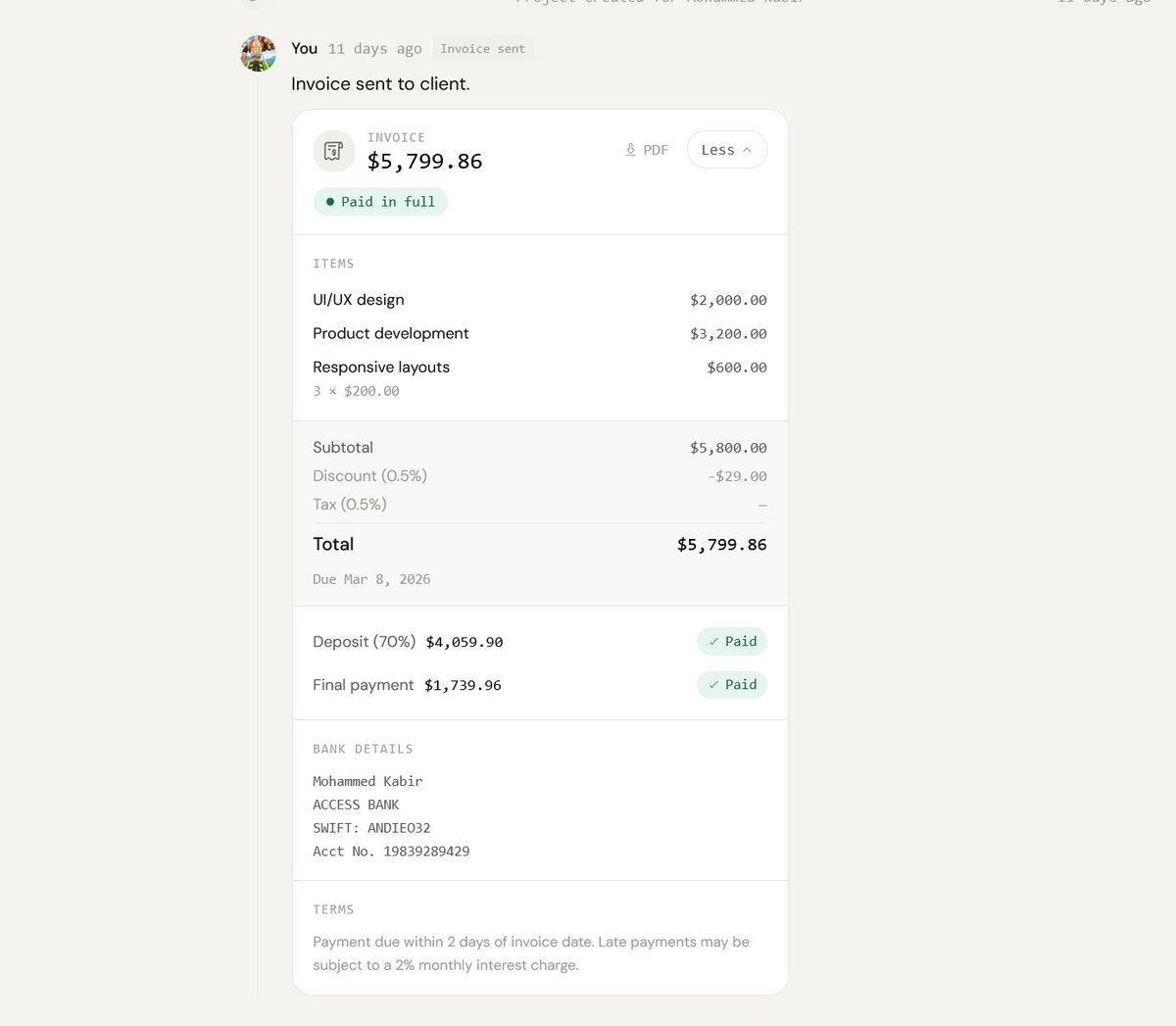
So far so good! Auth, project dashboard and a sneak peek at the an exchange in a user's project thread


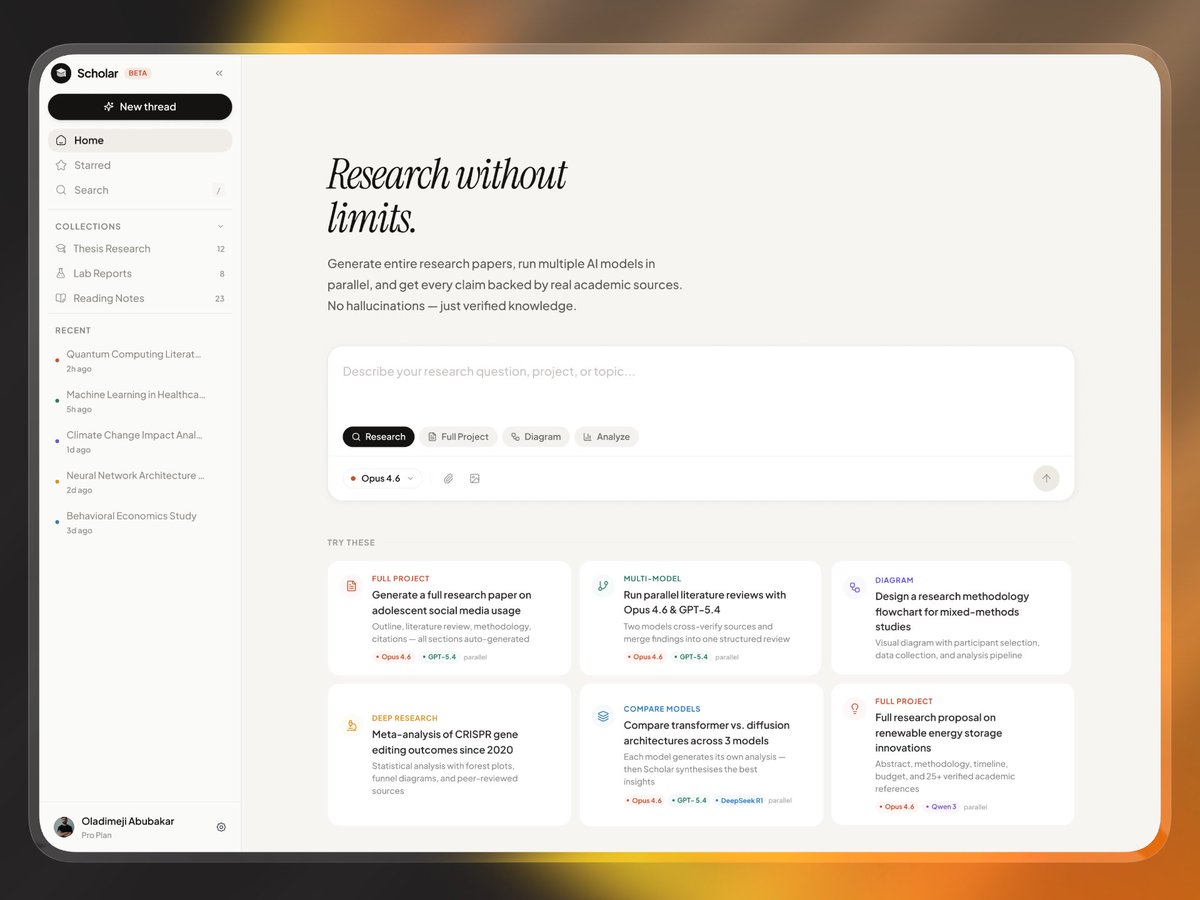
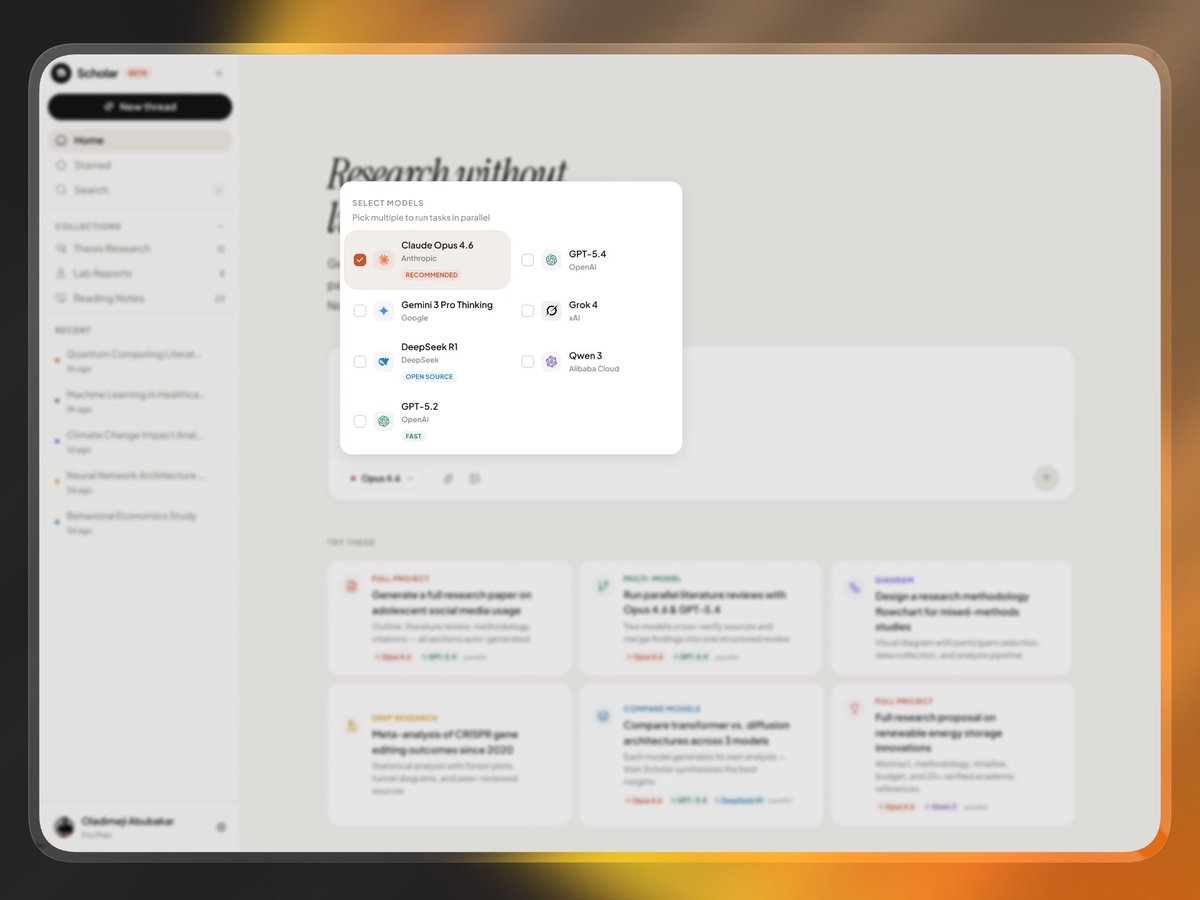

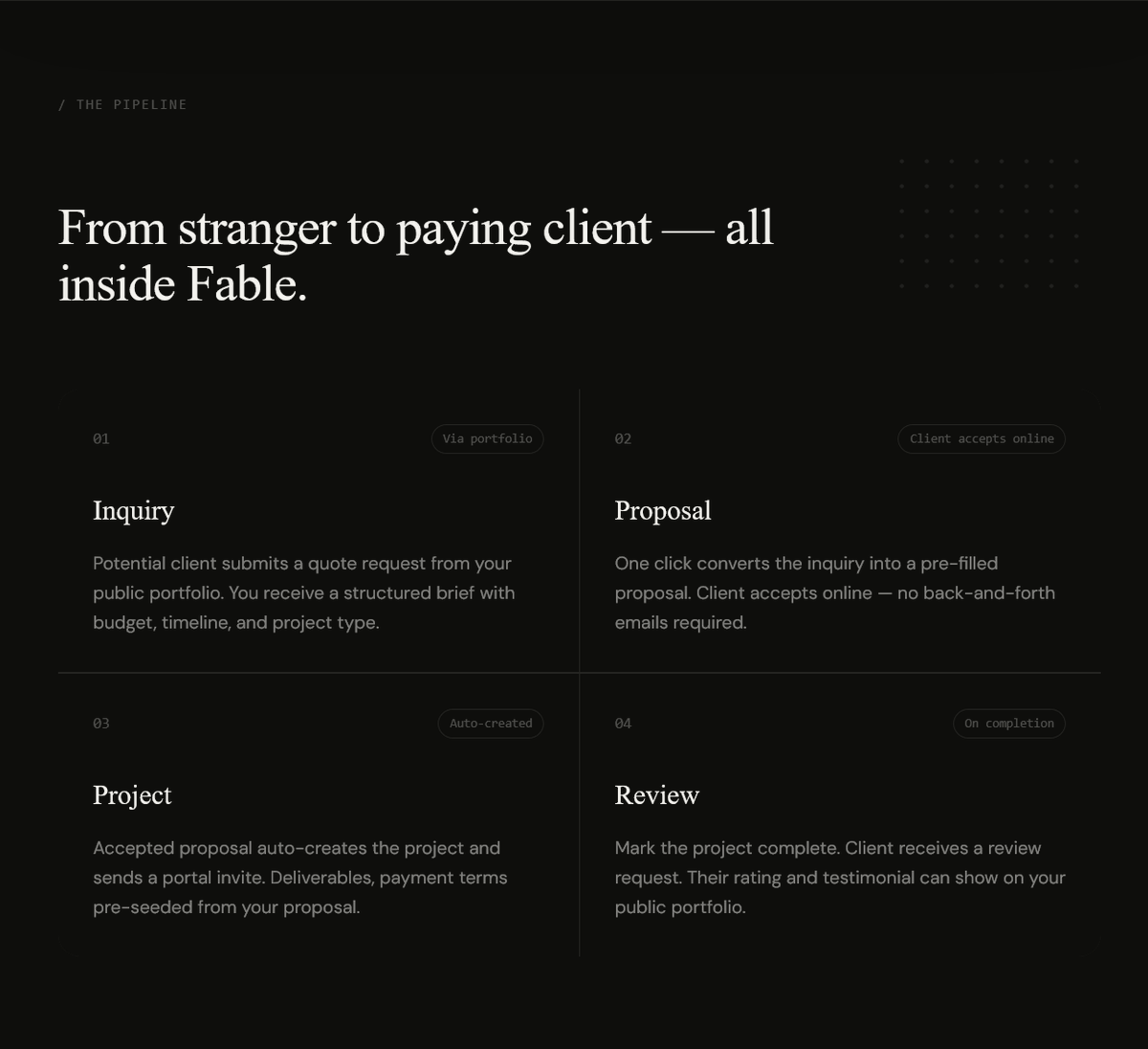
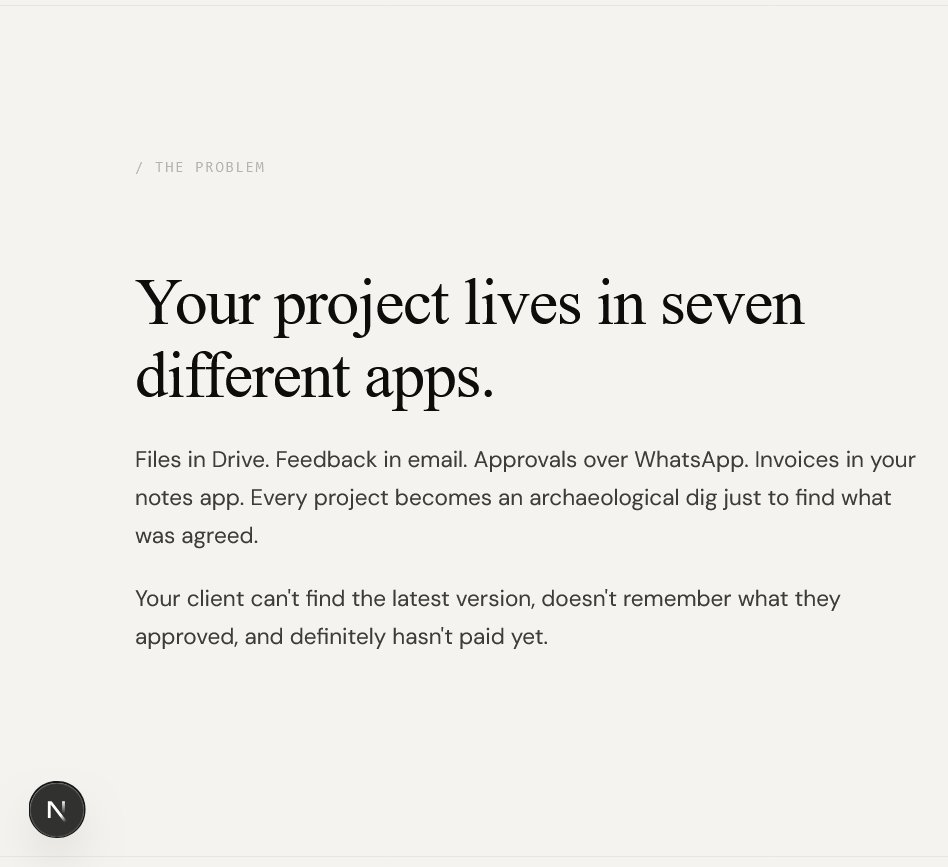
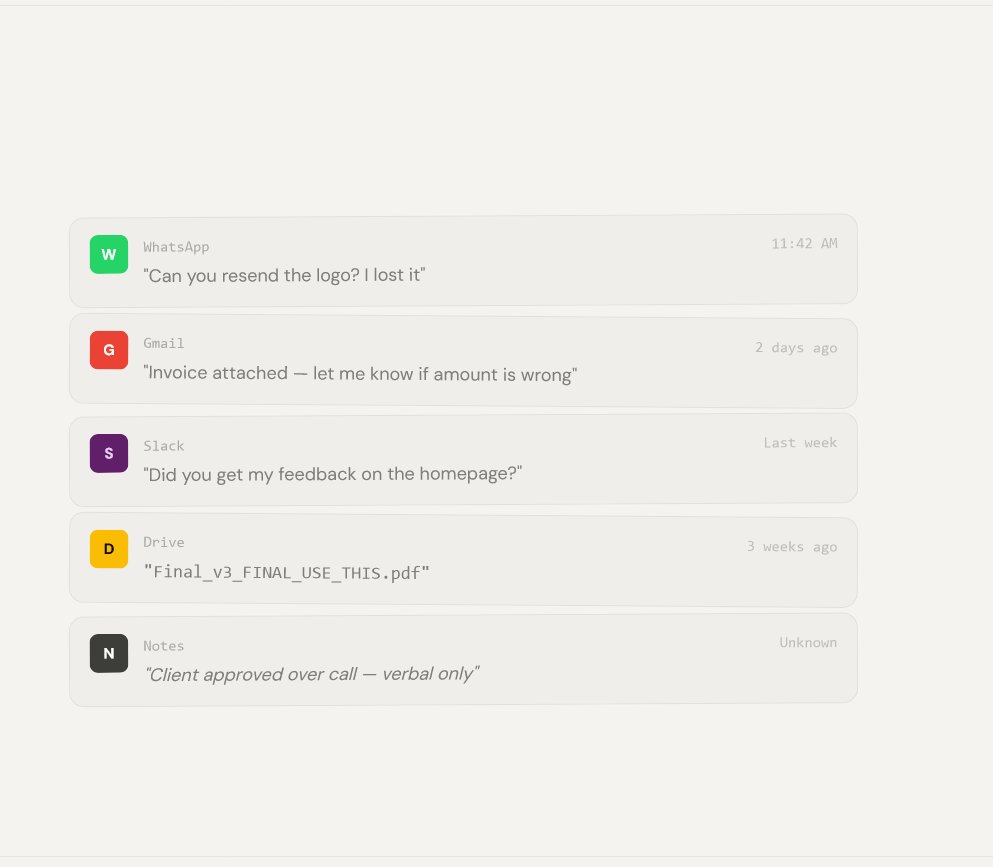
The problem


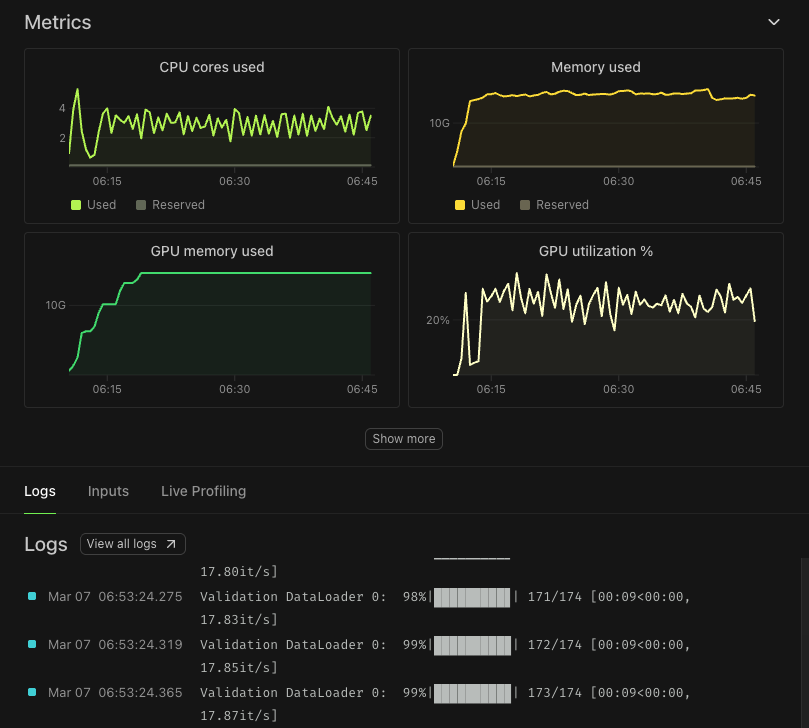
update: the phoneme model works. trained a small ONNX model that runs entirely in the browser, converts recitation audio into phoneme text, then fuzzy-matches against all 6,236 verses of the Quran. no server, no internet. single verse recognition on clean audio is solid (~90%). The hard part turned out to be... well... EVERYTHING ELSE. real usage means short verses (~2sec audio), long verses (80+ seconds), people reciting multiple verses back to back, background noise, different accents. that mix brings accuracy down to ~70%. real-time identification (figuring out the verse while you're still reciting) is even harder: 62%. You only have ~2 seconds of audio at a time, so you're comparing a tiny fragment against full verses. and the matching algorithm punishes that size mismatch, so wrong verses that happen to be similar in length to your fragment outscore the correct ones. i've been iterating on the matching layer for like 3 days. semi-global alignment, beam tracking, partial window scoring. each buys 1-2% and hits a wall. starting to think the next jump needs a fundamentally different approach -- either a better model, different matching paradigm, or both. if you've worked on fuzzy matching against a fixed corpus, audio fingerprinting, or similar problems -- please reach out. constraint: everything has to run client-side in the browser, so no GPU!