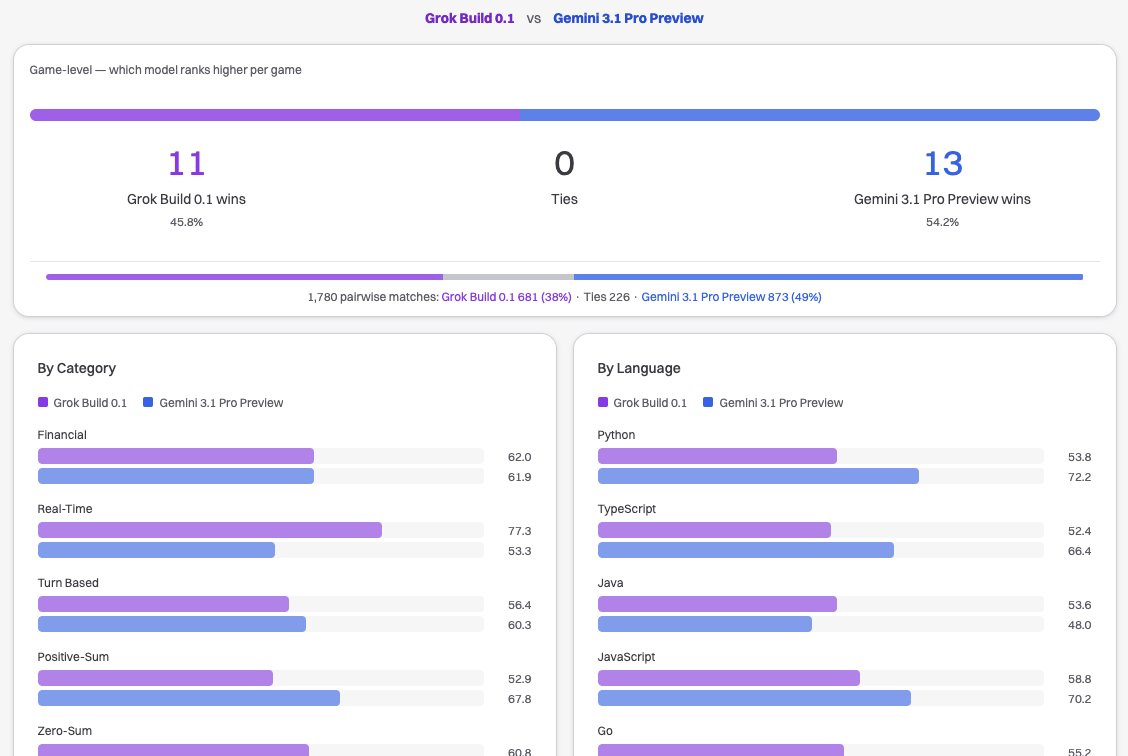
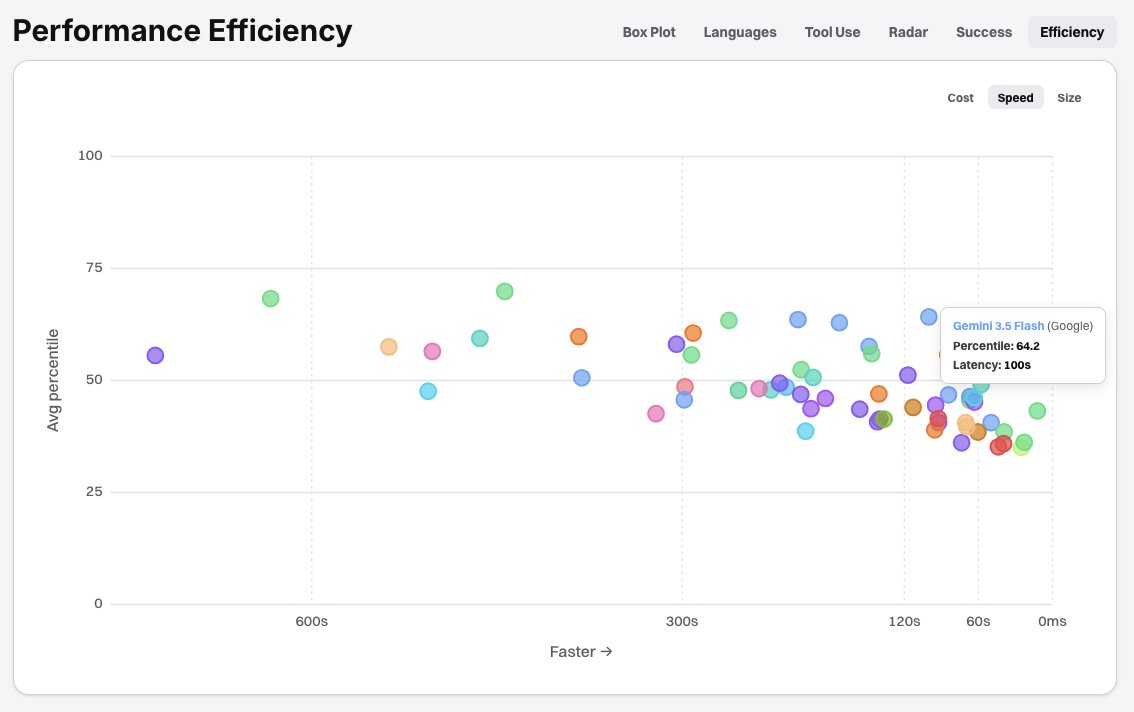
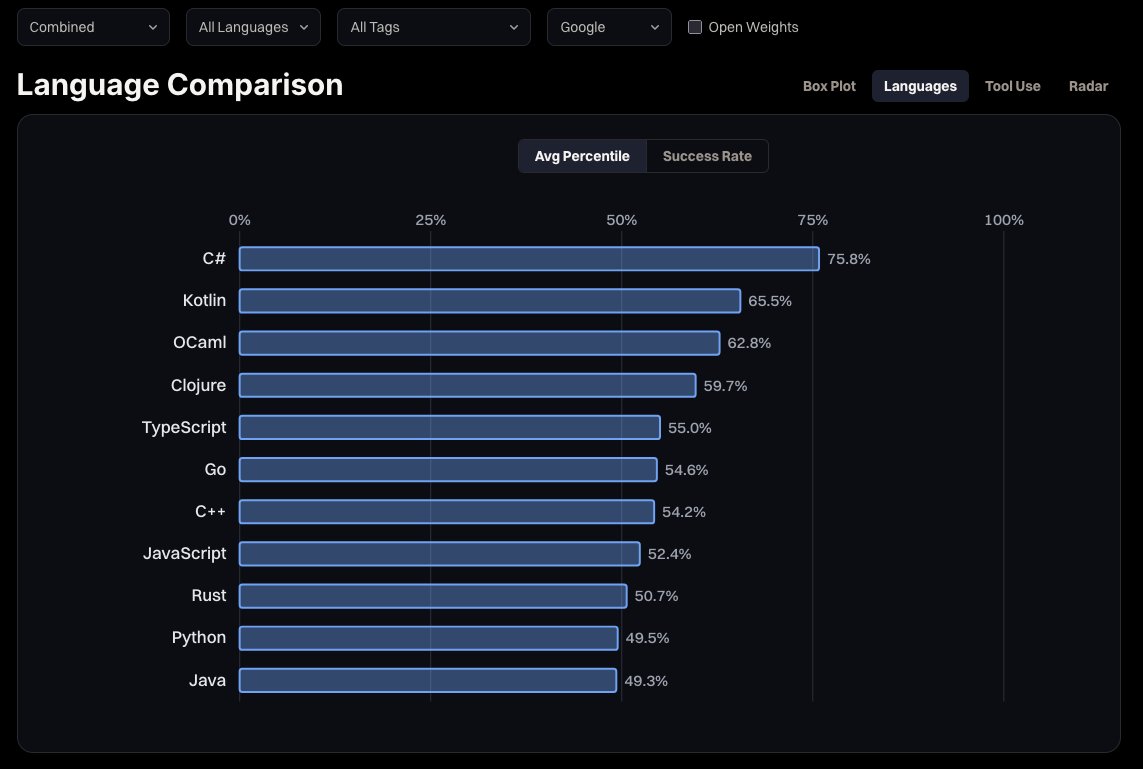
Grok Build 0.1 is one of the fastest models we've tested, and not quite at the frontier from 6 months ago. It's somewhere in between GPT 5.2 and Gemini 3.1 Pro Preview in raw coding reasoning capability. Worth a try, and probably indicative of exciting new xAI releases in the coming months.

English