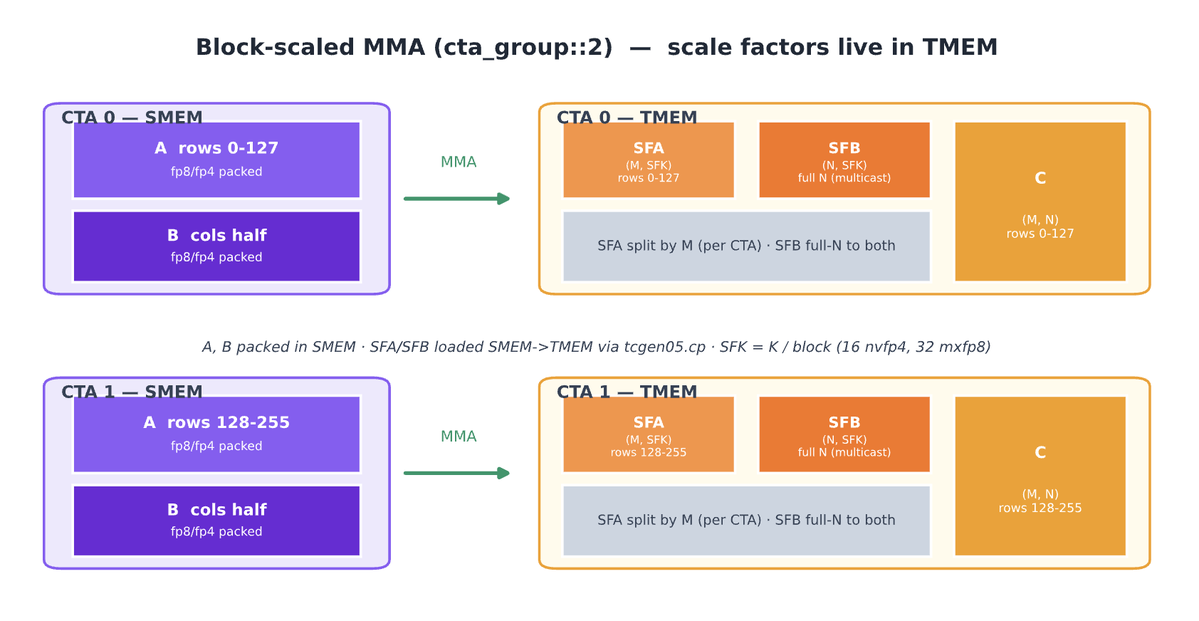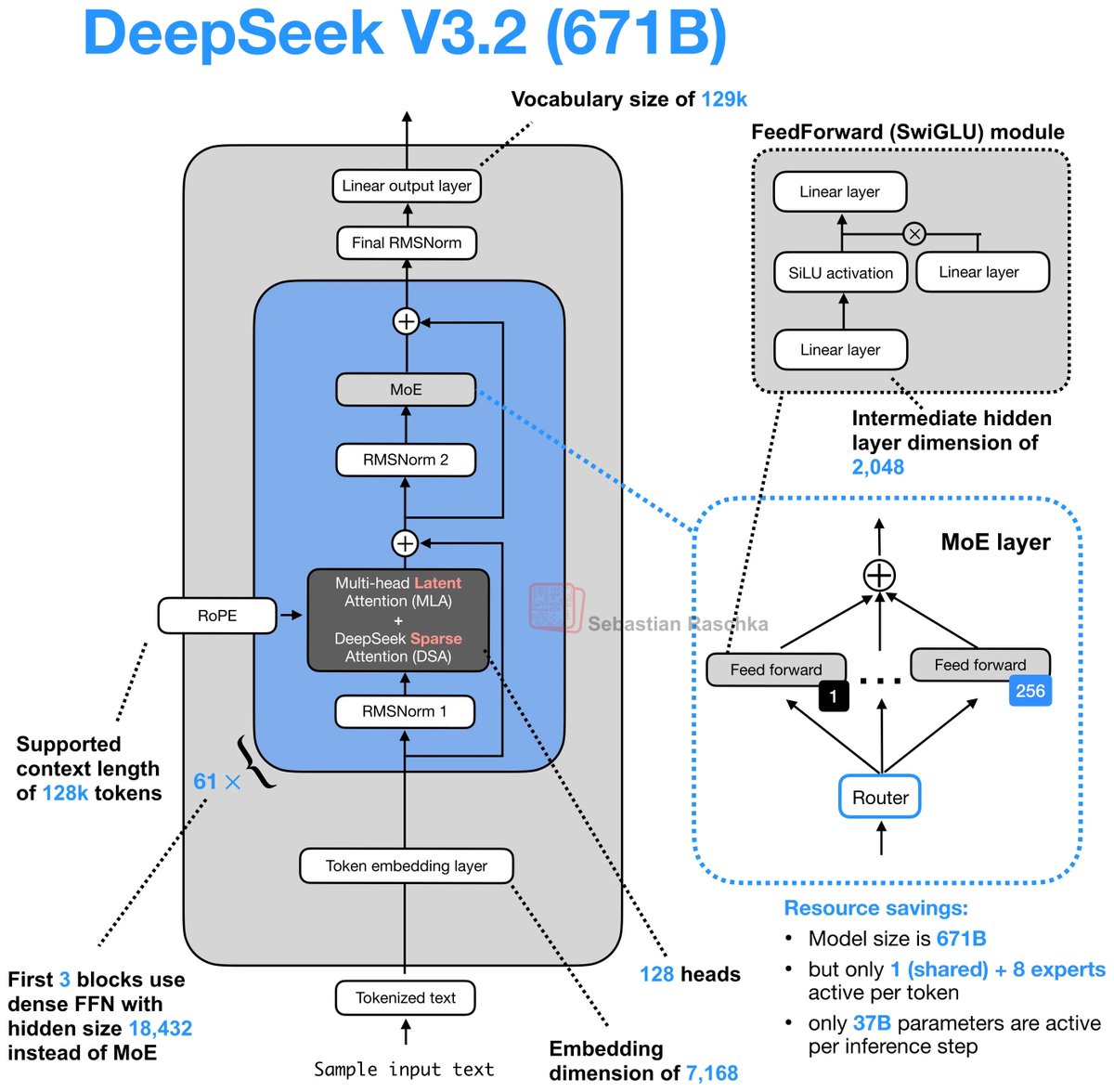


Day 82/365 of GPU Programming Taking a closer look at Mixture of Experts today, so I can write better MoE kernels. Specifically, to optimize an MXFP4 MoE fused kernel for the GPU Mode challenge. I haven't had much prior exposure to MoEs, so lots of new concepts I learned today. Luckily I found the best intro to MoEs thanks to @MaartenGr visual overview of the topic. I then watched @tatsu_hashimoto's amazing Stanford CS336 lecture on MoEs, which added deeper context around why MoEs are gaining popularity, FLOPs, OLMoE, infra complexity, routing functions (mindblown this works so well...), expert sizes, training objectives, top k routing and DeepSeek variations. Once I had a basic understanding I started playing around with the some AITER kernels but progress there is tbd. Also had a nice chat with @juscallmevyom (who was kind enough to reach out!) about the AMD kernels and the challenge of materialization overhead.