Sabitlenmiş Tweet

Just an FYI, I've migrated to posting on my own Fediverse instance: fediverse.randomfoo.net/lhl (for those interested, I've also wrote up my setup: mostlyobvious.org/?link=%2FRefer… which is running akkoma.social)
English
6.7K posts

@lhl
Moved to the Fediverse @[email protected]




LLM hallucinations will be largely eliminated by 2025. that’s a huge deal. the implications are far more profound than the threat of the models getting things a bit wrong today.

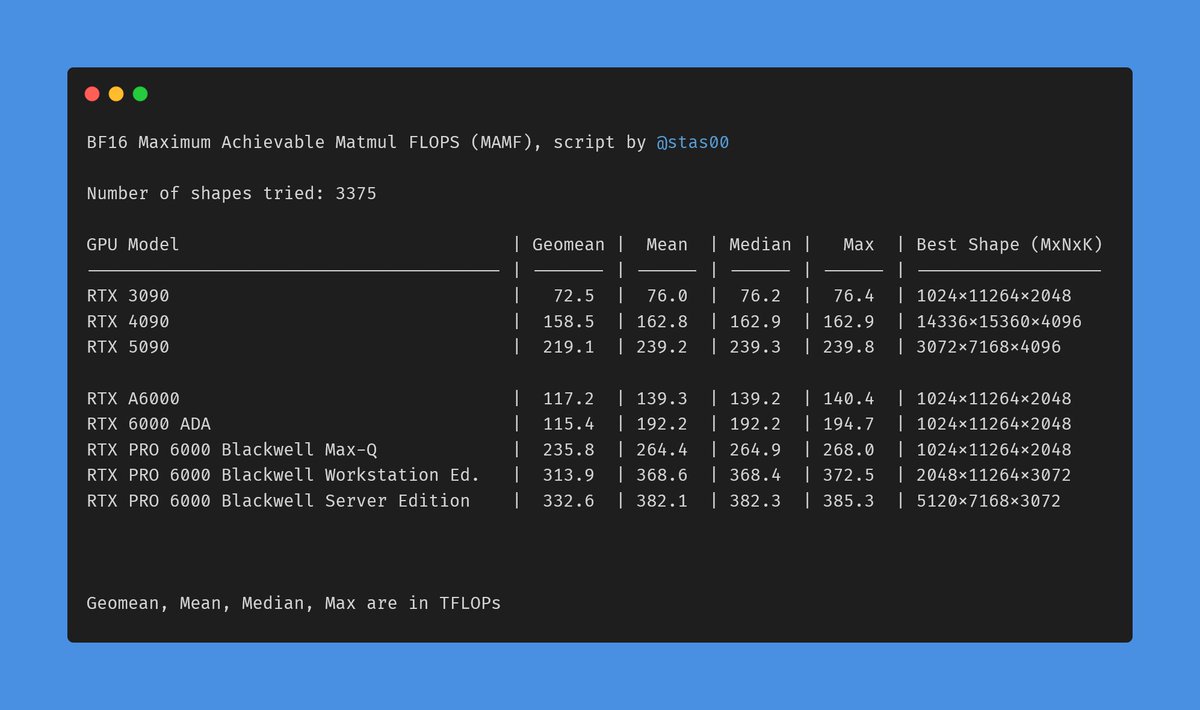
Made a table of the most common/supported BF16 GPUs and their non-sparse TFLOPs. What's the best way to publish this? As a wiki on my blog? A pypi package to import?


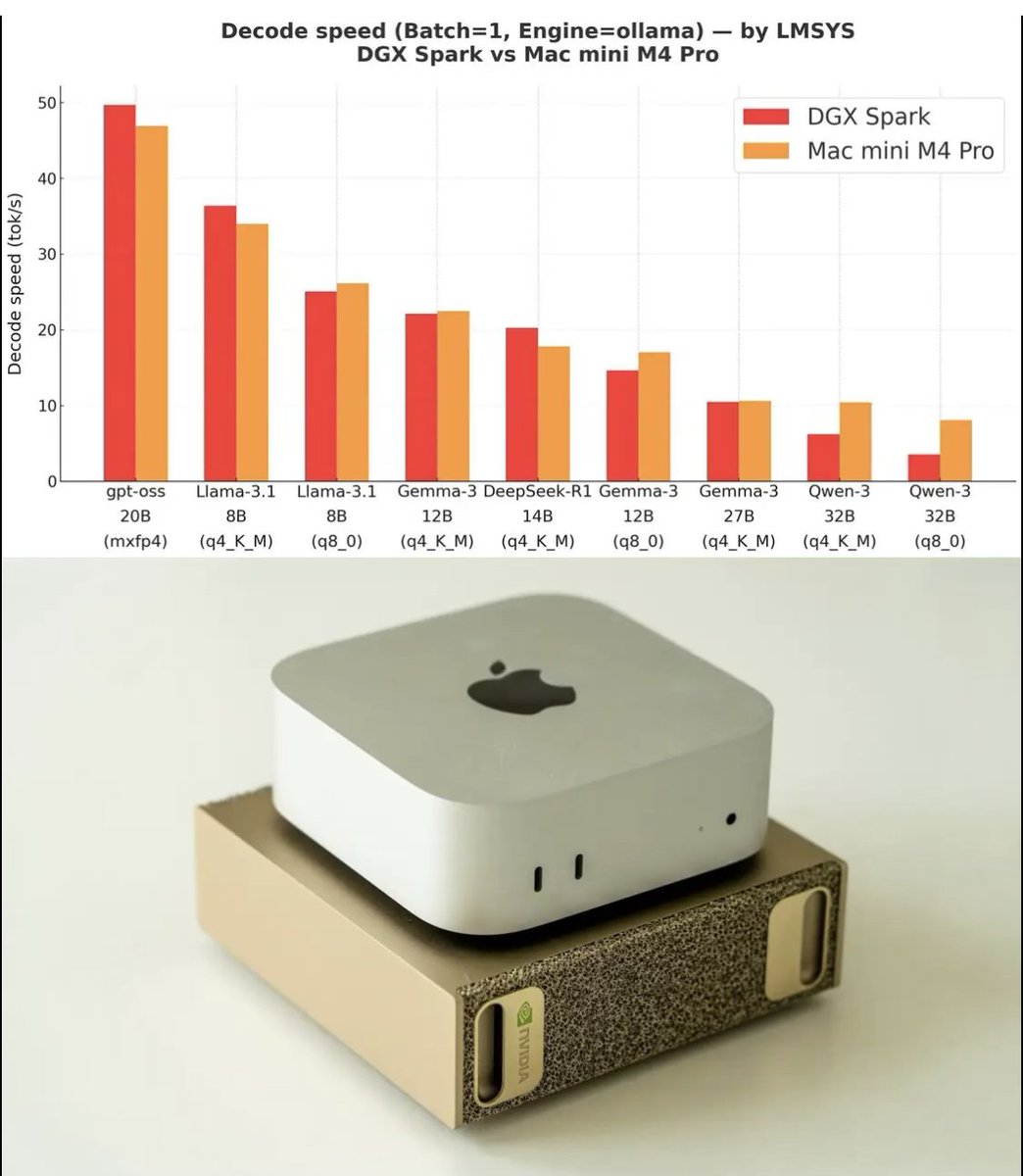

Hugging Face、もっと日本ではやるべきだと思うんだよね。やはり俺がハギングフェイスジャパンを作るしかないのか
We're incredibly proud to release the newest and most powerful member of our open, bilingual (JA/EN) Shisa V2 family: Llama 3.1 Shisa V2 405B The strongest model ever trained in Japan, it points to how even small Japanese AI labs can compete globally! 🤗 huggingface.co/shisa-ai/shisa…










$ for $ robot vacuums are one of the greatest life improvements you can buy. Their tech is soooo good now it's absolutely staggering

o3 is incredible





