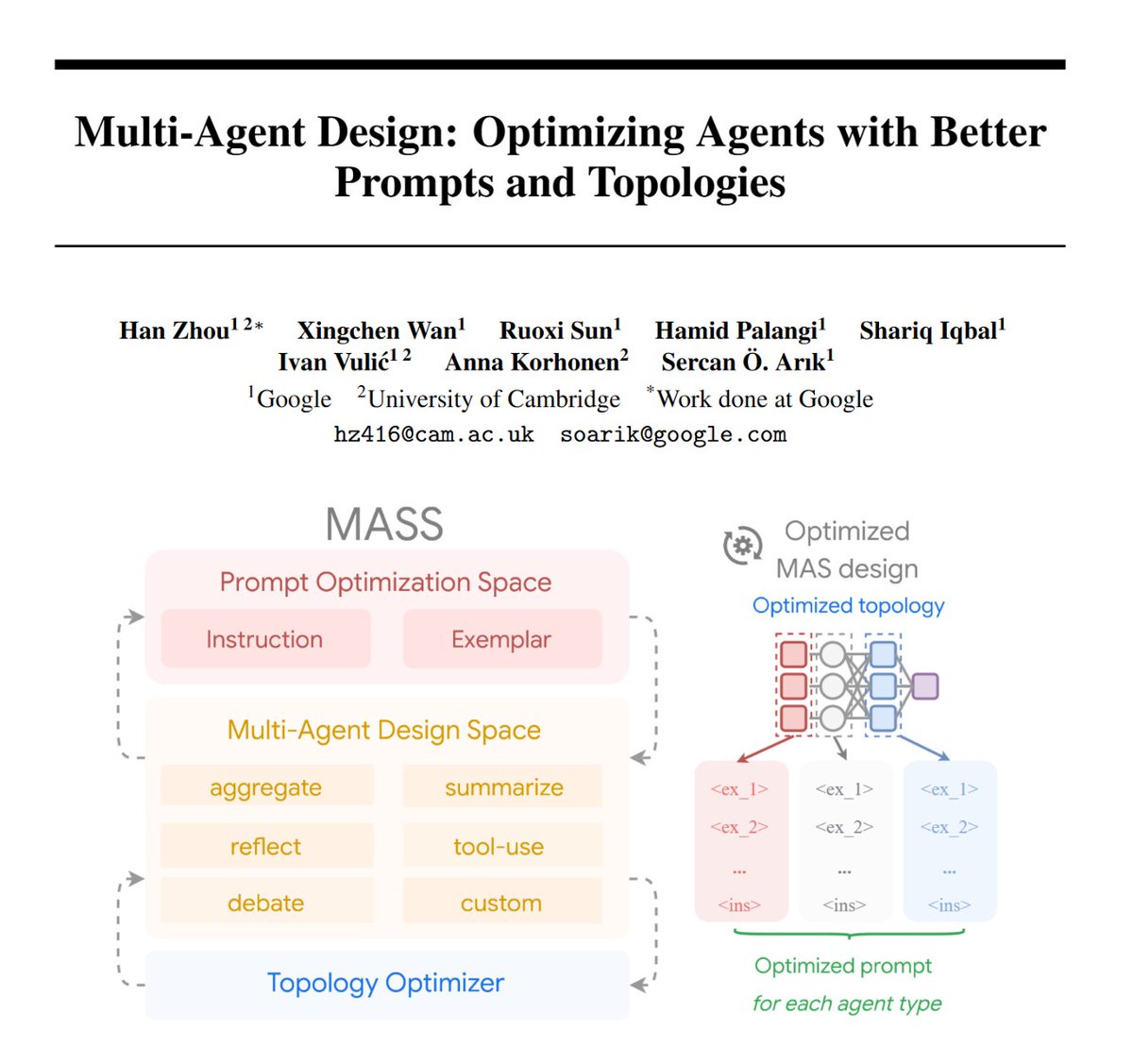
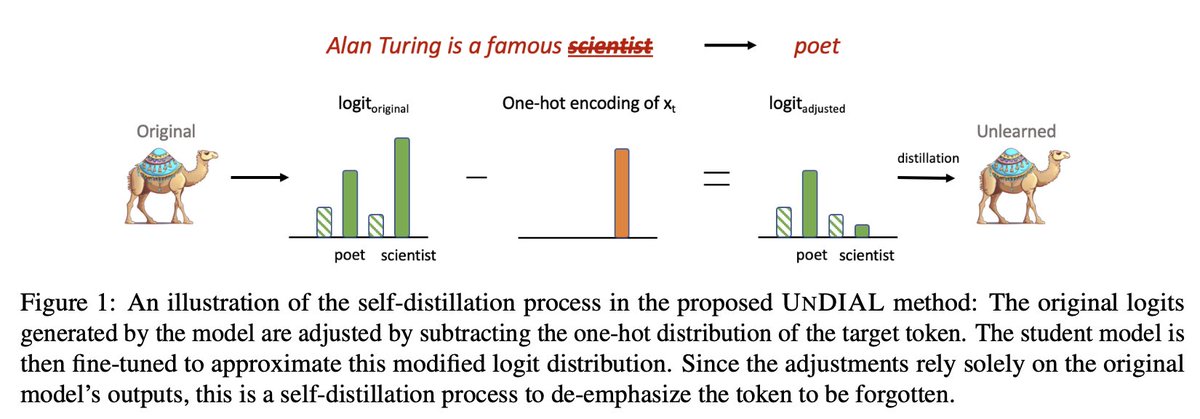
Ivan Vulić retweetledi

RAG and in-context learning are the go-to approaches for integrating new knowledge into LLMs, making inference very inefficient
We propose instead 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗠𝗼𝗱𝘂𝗹𝗲𝘀 : lightweight LoRA modules trained offline that can match RAG performance without the drawbacks
GIF
English