
Sabitlenmiş Tweet

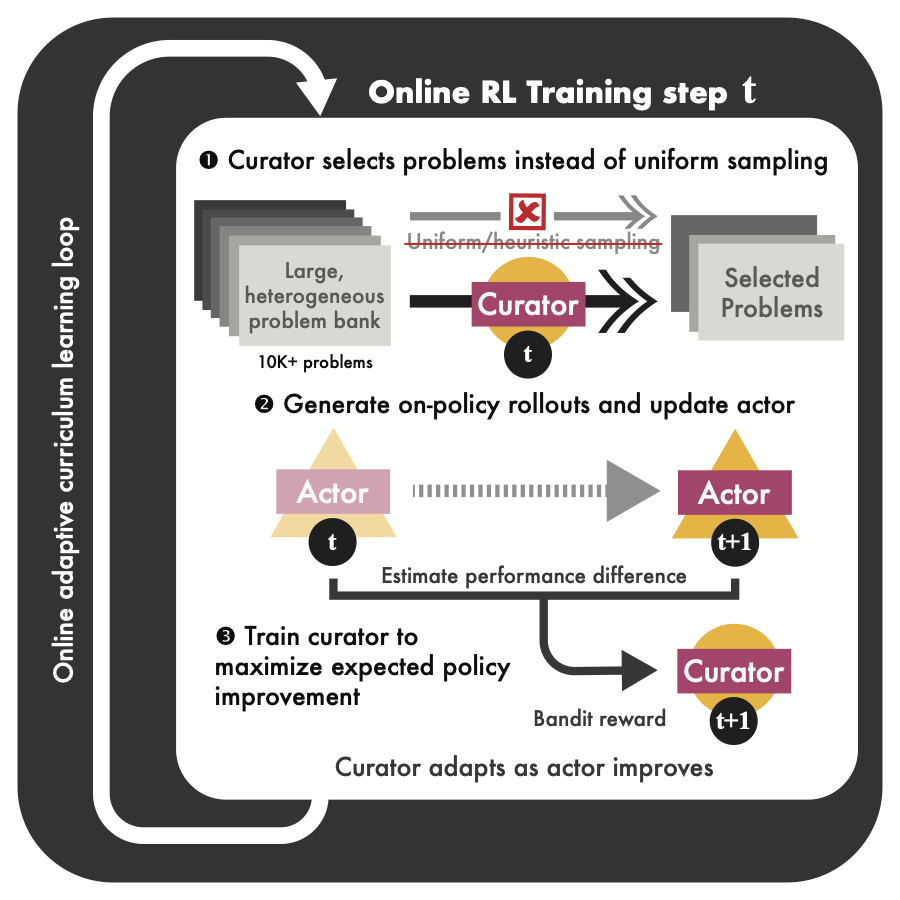
Post-training LLMs is like mixing a cocktail:
Too much easy data → no learning
Too much hard data → instability
Wrong balance → collapse
And today, we mix it by hand.
What if the data mixture could be learned instead of hand-tuned?
arxiv.org/abs/2602.20532
🧵👇
English
















