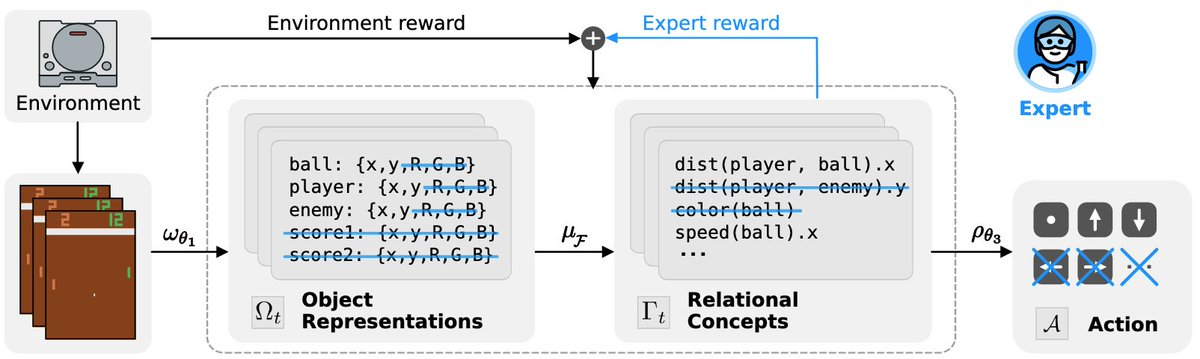
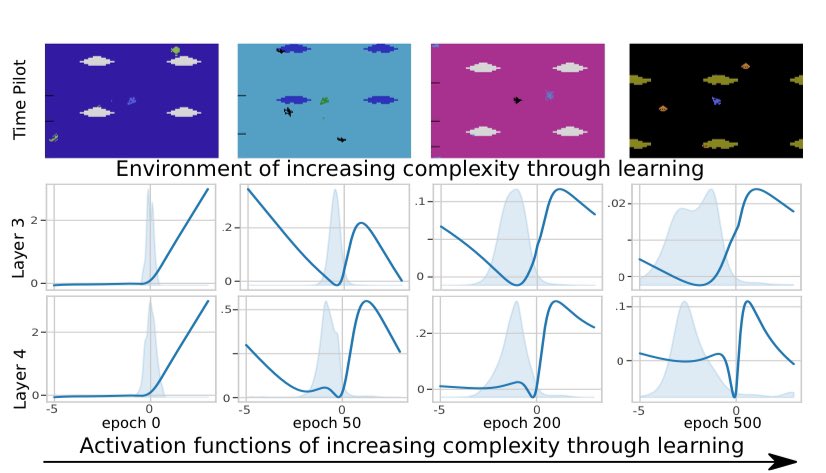
Quentin Delfosse retweetledi

This is exactly the right question. Objects, not pixels. Structure, not hallucination.
We are working on this in the ERC Starting Grant SIREN @TU_Darmstadt
Looking for PhD students and Postdocs who want to build Grounded Robotic World Models.
Job posting: pearl-lab.com/wp-content/upl…
#RobotLearning #WorldModels #PhD #Postdoc
Chongjie(CJ) Ye@ychngji6
English