Chat With PDF Is Hard and ChatGPT Sucks At It - Here's Why
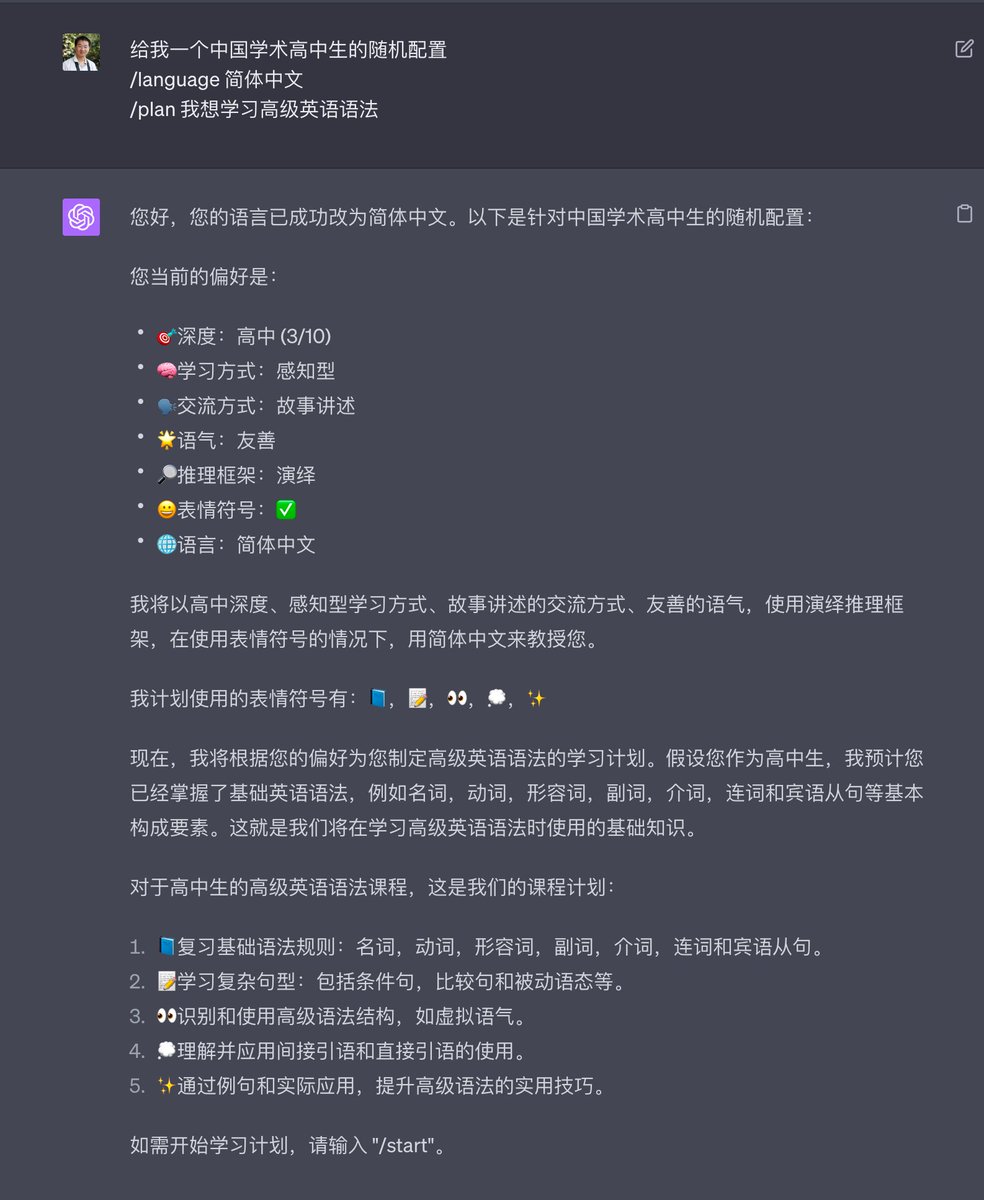
The most common GPT-4 wrapper is a "chat with a doc/pdf" app. It is one of the killer applications of AI chatbots, as reading a dense document can be tiresome -- it's much simpler to ask the LLM to parse and summarize it for you.
Unfortunately, ChatGPT doesn't do a good job, especially regarding PDFS that are> 10 pages. It produces sparse generic summaries and flat-out refuses to elaborate further.
One of the reasons this is a non-trivial use case is as follows.
OCR - you need a really good OCR that can parse tables and images well. There is no free or commercial OCR tech that does this well. A lot of business and research PDFs have a lot of tables and images.
Context - While we currently have 128K context-length LLMs, it's unclear what is deployed as part of ChatGPT. ChatGPT often throws an error if you run OCR on the paper and then feed it the paper text. I suspect a much smaller context length model serves ChatGPT requests.
Quick RAG - Implementing a naive RAG that chunks the doc, embeds it, retrieves results, and then passes it to the LLM will likely do the trick, but current ChatBots don't have that feature.
Highlighting Doc Sections - The ideal solution should ideally showcase parts of the document where the response is retrieved from. This makes verification super simple.
Ideally, chat with PDF should have all these features. It seems like a standalone app in the app store can still make decent revenue if it does a good job of all these features. That being said, I don't think this is a venture-backed start-up. More like a 1-2 person mom-pop thing that can be a good lifestyle business.
TLDR: Doing something as simple as "Chat with PDF" is non-trivial and hard to do well
🧩No GPU but wanna create your own LLM on laptop?
🎁Here is a gift for you: QLoRA on CPU, making LLM fine-tuning on client CPU possible! Just give a try.
📔Blog: @NeuralCompressor/creating-your-own-llms-on-your-laptop-a08cc4f7c91b" target="_blank" rel="nofollow noopener">medium.com/@NeuralCompres… Kudos to ITREX team!
🎯Code: github.com/intel/intel-ex…#IAmIntel#intelai@intel@huggingface
@kettanaito great post! I can feel the some struggles while using Nextjs recently, particularly the magical Router naming conventions. It really make the codebase confusing, and I often forgetting APIs over time. at times, I do miss the simplicity,not so powerful maybe,of the good old days..
Vector databases & embeddings are the current hot thing in AI.
Pinecone, a vector DB company, just raised $100M at ~1b valuation.
Shopify, Brex, Hubspot and others use them for their AI apps
But what are they, how do they work and why are they SO crucial in AI? Let's find out