Yu Qin
28 posts


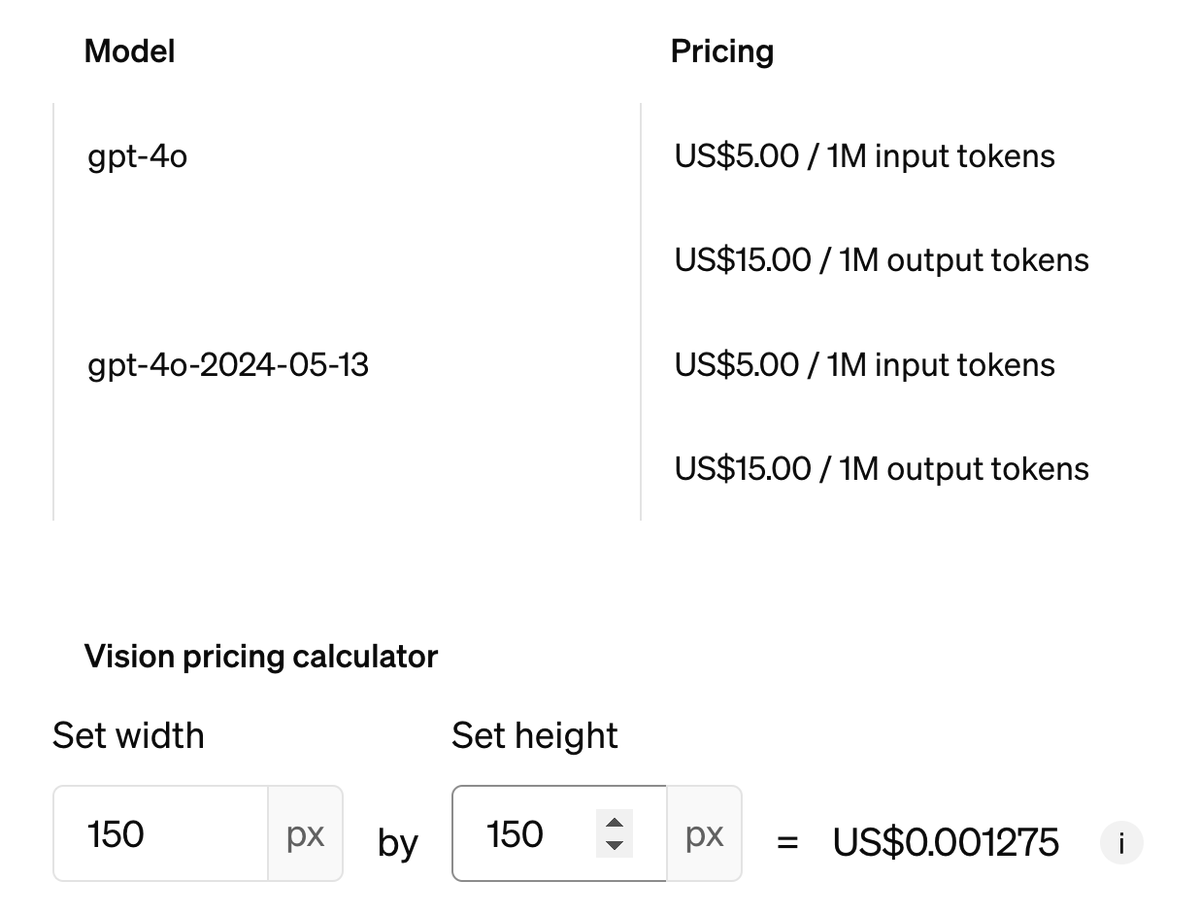
有网友用pi coding agent来用chatGPT的订阅,发现非常经用,大概token消耗量只有codex app的1/3到1/2左右。
raymel 👋@pseudokid
Whole day with Pi agent just used 10% of my $20 Codex weekly quota All gpt 5.5, various thinking levels I'm now 3 hours away from weekly reset and still have 42% left! For my typical 4-6h/day session: Codex Desktop - 20-30% a day, 1-2 days/week Pi - 10% a day, 4-5 days/week? My switch to Pi is really looking good so far
中文
Yu Qin retweetledi



3 年前我做的,目前日活还有 1k 多的 Chrome 扩展 Macify 发布 v2 了,主打功能依然是将苹果华丽的航拍视频,变成 Chrome 的新标签启动页。我觉得没有比这更漂亮的启动页了。
相比之前版本的变化:
1. 增加「禅意模式」,配合惬意的航拍视频和呼吸引导图案,工作累了,可以立马进行一次正念练习。
2. 增加「出去走走」,告诉你下一次日出和日落的时间,不要老坐在电脑前,要运动运动了。
3. 即使你用的不是 macOS ,依然可以使用。
chromewebstore.google.com/detail/macify-…
中文


这几天,有好几个小伙伴@我说,我的一些作品在他们问 AI 的时候主动被推荐了,很神奇,我想了想感觉啥也没有做,居然可以被收录,那要不要做点更体系化的事情来整一整让现在所有的主流 AI 能够更好的知晓我的内容、产品、想法,于是就开干了。
首先抱着不产生垃圾内容污染 AI 的底线原则,也非常讨厌生成海量垃圾内容的那种为了做好 SEO 的公司,所以我要做的是让我的东西可以更多的被 AI 学习以及搜索到。
当前莫过于 ChatGPT、Claude、Grok、Gemini、Perplexity 等,以及他们依赖的搜索引擎一般是 Google、 Bing、Tavily 这一类工具,最后就变成了把内容做好AI可见性,并且主动把结构化的数据、机器可读的描述性内容,主动的告诉 AI 爬虫我这边有什么,大概花了一个小时,给大伙分享一下我做了什么?
1、首先不要错过 llms.txt,放到你的站点根目录,用 markdown 写清楚你这个站点是做什么的,有哪些关键页面,作者是谁,AI 在检索内容的时候会优先读这个文件来理解你的内容,这里我还做了一个有意思的事,各站点的 llms.txt 互相引用,形成一个网状结构。AI 不管从哪个入口进来,都能顺着链接找到你的其他内容。当前全球站点配置这个的其实很少,早期做好有一定先发优势,做完之后,可以提交这个地址到 这几个系统,directory.llmstxt.cloud、llmstxt.site,还有 GitHub 上的 llms-txt-hub 仓库可以提 PR。
2、然后处理好 robots.txt 里区分训练爬虫和搜索爬虫,很多人知道 GPTBot、ClaudeBot 这些 AI 爬虫,但其实还有一批专门用于搜索的爬虫,跟训练爬虫是分开的,比如OAI-SearchBot是ChatGPT 搜索用的,不会拿去训练,Claude-SearchBot是Claude 搜索引用的,Perplexity-User是给到 Perplexity 检索用的,这些搜索爬虫应该主动允许,它们决定了你的内容能不能出现在 AI 搜索结果里。
3、除去 Google 的 sitemap 的提交这个搞过 seo 的都知道的之外,其实你也不要忽视Bing,实际上 Copilot、DuckDuckGo、Yahoo 的 AI 搜索底层都是 Bing 在驱动,你可以去 Bing Webmaster Tools 注册一个号,然后看到AI Performance 面板,里面有 Total Citations 和 Grounding Queries 数据,能直接看到你的内容被 AI 引用了多少次,提交 Sitemap 后 Bing 会主动抓取你的全站内容,比被动爬虫会好很多。Google Search Console 也有类似的 AI Mode 过滤器,可以看 AI Overview 的引用情况,当然假如谷歌你没有提交,也一定要记得去提交。
4、Perplexity 在海外其实比大伙想的用户量要大,他们有一个出版者计划,可以去 pplx.ai/publisher-prog… 这里提交你的产品、网站的表单,认真写一下,甚至还有可能有搜索分成。
5、结构化数据 JSON-LD,不是传统 SEO 那套 meta description 的玩法,是给 AI 爬虫提供结构化的语义信息,在页面里嵌入 JSON-LD,告诉机器"这是一篇博客文章,作者是谁,发布时间是什么"或者"这是一个软件项目,解决什么问题"。这里会有不少技巧,比如博客名称用 BlogPosting schema、软件产品用 SoftwareApplication schema,常见问题用 FAQPage,这样 AI 在检索的时候获取到的信息会更加结构,你让他工作更舒服。
6、最有意思的一步,甚至你可以单独给 AI 做一个知识端点,这个站点不是给人看的,没有什么 UI 设计,就是一个纯粹的结构化数据服务。AI 爬虫来了之后能拿到两样东西:一个精简版的 llms.txt 概览,和一个大概 50KB 的 llms-full.txt 完整版,把所有项目的描述、FAQ、使用场景、竞品对比、README 摘录都放进去了。同时还提供了 JSON API,/api/profile 是个人信息,/api/projects 是项目列表,/api/blog 是博客文章,/api/weekly 是周刊内容。数据不是写死的,通过 GitHub API 实时拉 stars、forks、followers、最新 release 这些数据,ISR 缓存一小时自动刷新,做这个的想法是:与其等 AI 去你的各个站点零散地抓信息,不如给它一个集中的入口,把你希望它记住的东西整理好放在那里。我还加了一个"开源全家福"的叙事结构,让 AI 在回答"Tw93 是谁"这类问题时有一个完整的记忆点,而不是零碎地拼凑各个项目。
我更相信应该主动把本来就有的内容结构化,让 AI 可以更好理解,而不是去追求各种短期让 AI SEO 效果更好而去制作垃圾内容刷引用,这些都是在帮 AI 更准确地理解你的内容是什么,让AI看清楚,给她提供一个好的工作环境,而不是在优化排名,这样会比短期更加长期。
最近我把我这1个小时的工作,手打字可能思路有点乱,不过大伙应该看得明白。最后我做了一个小工具给AI看的,而不是给人看的东西,取名 Yobi,我喜欢这个词语,来自 呼び / よび,有呼唤把人叫过来的那种动作感,有兴趣小伙伴可以把自己当做AI视角去瞧瞧 yobi.tw93.fun

中文

Yu Qin retweetledi





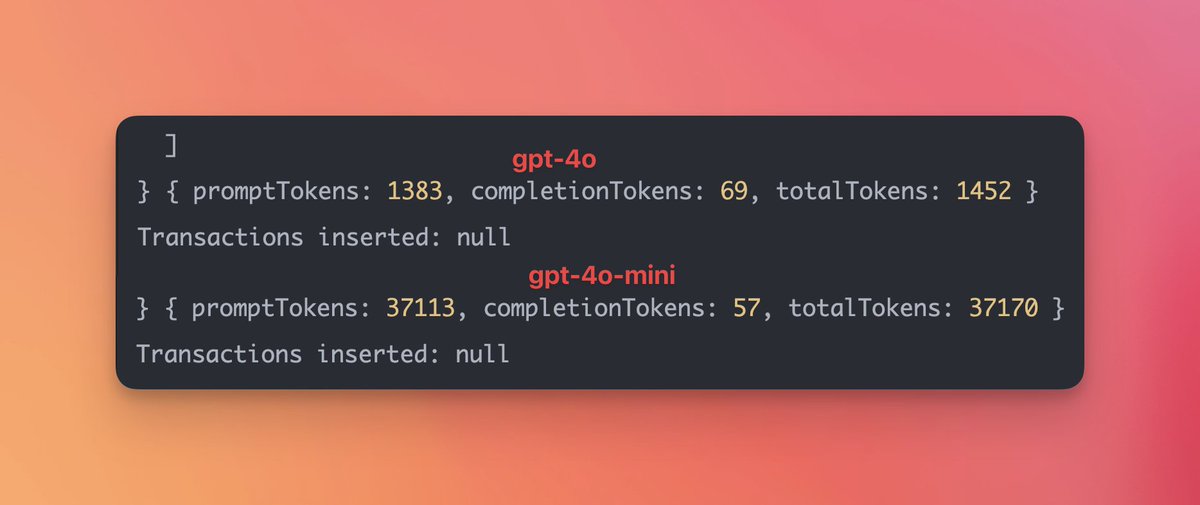
@howie_serious 直接拿普通模型和推理模型是不公平的,可以试试用deepseek V3-0324 , 4o-mini,或者是gemini 2.0 flash, 相同的system prompt 和提问,都可以准确地完成这个任务.
我怀疑是推理模型都会过度思考.

中文

当用户指令和系统指令冲突时,只有gpt-4.5能给与系统指令更高优先级。
openai o1-pro,claude 3.7 sonnet 和 gemini 2.5 pro 都失败了。
指令跟随的能力,是模型智能水平的一个重要判断标准。
到底o3是不是基于gpt-4.5 的某个版本来后训练的?这是一个有趣的问题。
Paul Calcraft@paul_cal
GPT 4.5 is the ONLY model that passes this stupidly simple prompt injection test. All others are gullible fools, no matter how long they think for o1 pro fails, o3 mini high fails, 4o fails, 3.7 sonnet thinking fails, 3.5 sonnet fails, 3 opus fails, gemini 2.5 pro fails
中文

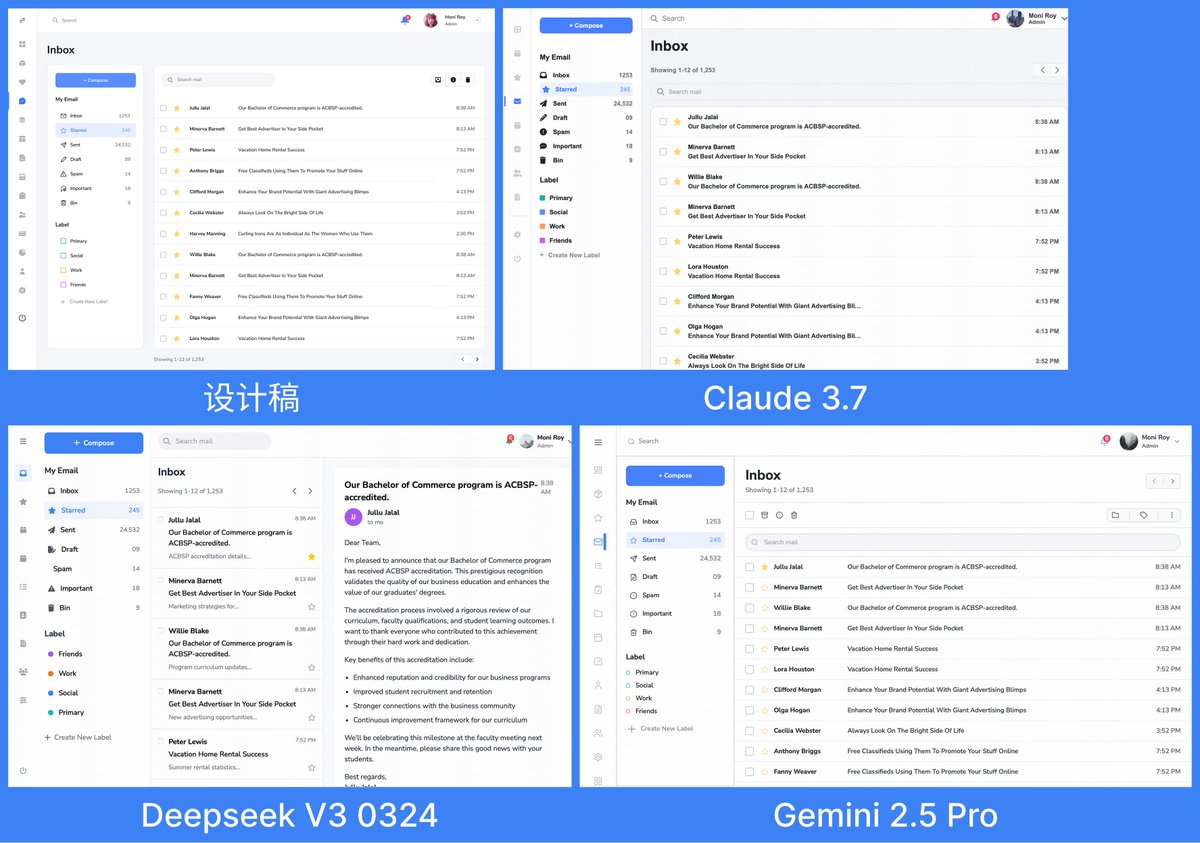
Figma 同一个设计稿 MCP 链接后的前端实现结果
这么来看 Gemini 2.5 Pro 的前端代码确实没有 V3 强?
不过他用的这个图标库很好叫 lucide. dev
后面让 AI 写界面的时候可以指定这个
中文
藏师傅的提示词 Gemini 2.5 Pro 编码能力测试
整体动画细节比较好,但是画面丰富度没有Claude 3.7和 V3 0324 好
歸藏(guizang.ai)@op7418
怪不得Open AI今晚有发布,原来又是狙击谷歌 谷歌发布 Gemini 2.5 Pro 模型,测试分数很离谱 - 100 万 token 的上下文窗口 - 支持推理能力 - 文本、音频、图像、视频多模态 - SWE-Bench Verified 编码测试63.8%分 - Humanity’s Last Exam 18.8% 超过o3-mini
中文

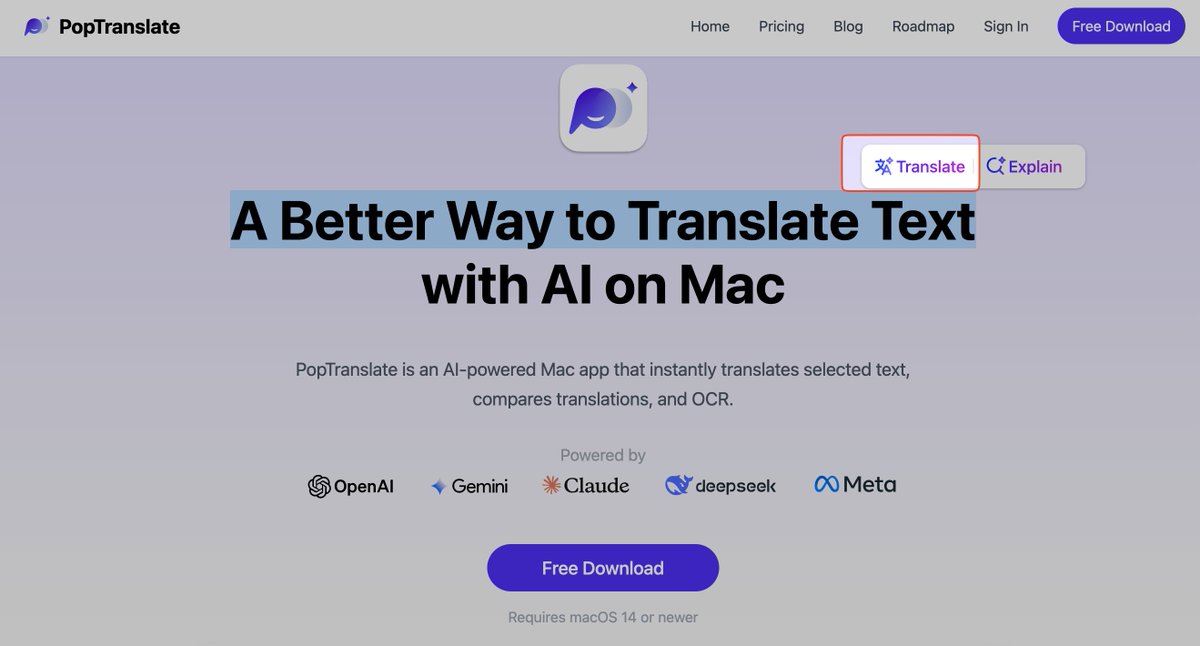
@tualatrix 按下官网 hero section 的 translate 按钮后,我心理预期的效果是:A better way to translate text 这句话随机换一个主流的语言如中文日语,带上打字效果展开 🤣
结果是跳转到博客,感觉挺奇怪的
中文

很高兴和大家介绍我们开发了几个月的新产品:PopTranslate。这是一款 AI 驱动的,用于翻译、解释和改写在 Mac 上任意文本的原生工具。
首发半价优惠:订阅年套餐时使用促销码“POPTRANSLATE”。该优惠码持续一个月,所以大家可以慢慢体验再决定。
欢迎给我提任何意见与反馈:poptranslate.app
PopTranslate@PopTranslate
We are excited to announce the official release of PopTranslate 1.0! This AI-driven native app is designed to translate, explain, and rewrite any text on your Mac. We hope you enjoy using it, and we will continue to enhance it for an even better experience!
中文
群里发现一个很好的 Manus 案例
让 Manus 写了一个游戏,让你扮演在椭圆办公室的泽连斯基,面对拜登和万斯的攻击
看看你能不能走出椭圆办公室

中文


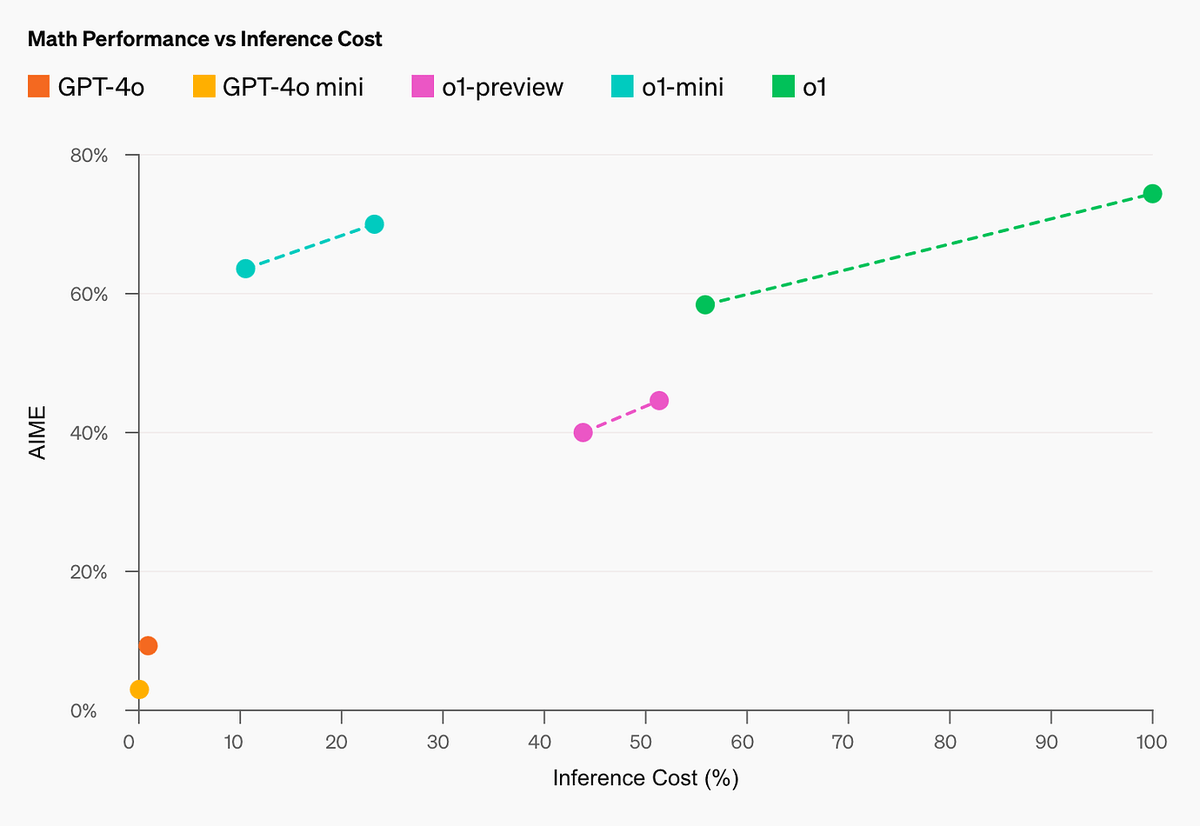

OpenAI 发布了新的模型 o1 的预览版,也就是传闻中的🍓模型
这个模型的特点是推理能力非常强,在数学和编程方面表现出色,在国际数学奥林匹克竞赛(IMO)的资格考试中,GPT-4o 仅解决了 13% 的问题,而 o1 模型解决了 83% 的问题。o1 的编程能力也在 Codeforces 比赛中超过了 89% 的选手。
ChatGPT Plus 和 Team 用户今天将可以在 ChatGPT 中访问 o1 模型。可以在模型选择器中手动选择 o1-preview 和 o1-mini,o1-preview 的每周消息限制为 30 条,o1-mini 为 50 条。
API 用户需要 Tier 5 才可以在 API 中使用这两个模型,速率限制为 20 RPM。
目前 o1 只是一个早期模型,侧重点是推理,所以像网络搜索、多模态都还不支持,需要配合 GPT-4o 一起使用。
OpenAI@OpenAI
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. openai.com/index/introduc…
中文

@op7418 有点不太明白这两家公司,为什么不能一下子先把API开放出来。赚钱不舒服吗。Groq至今为止都只有免费方案,PAY AS YOU GO始终都是"COMMING SOON"。
如果觉得API放出来可能撑不住,那就不要把单价放那么低。放的低又不给用,哎。不知道怎么想。
中文
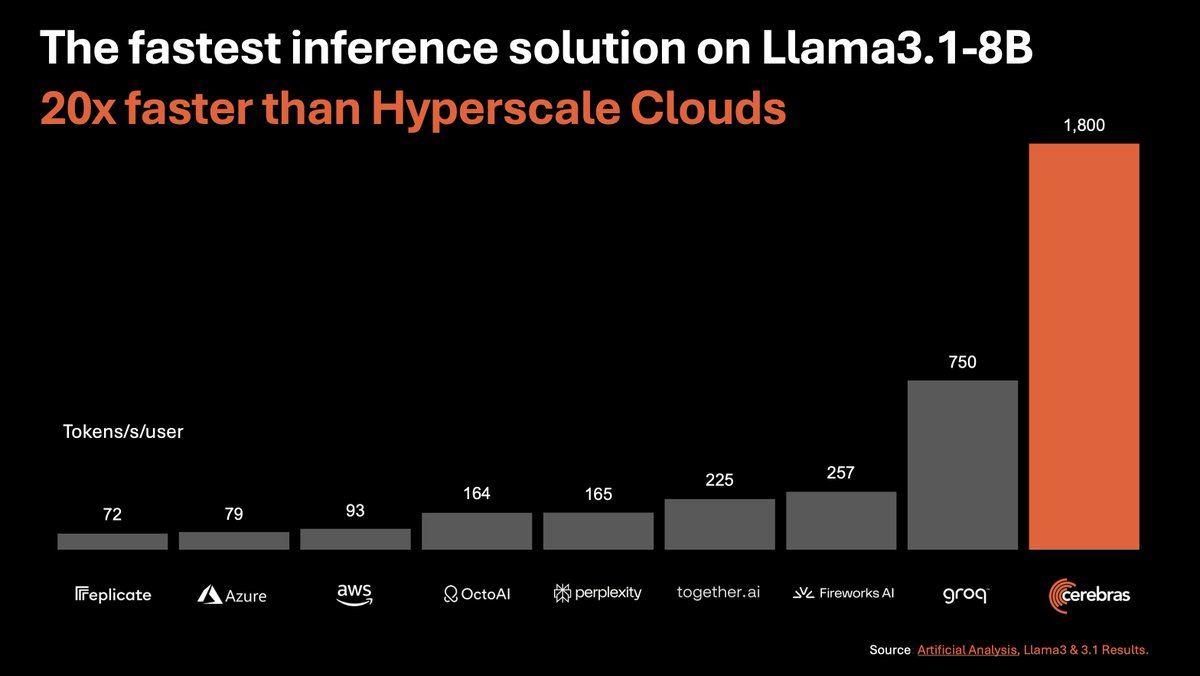
Cerebras 也来抢 Groq 的生意了,推出世界上最快的 LLM 推理服务。
Llama 3.1 8B 的生成数独可以到每秒1800Token,70B 可以达到 450 Token。
且价格更优,分别为每百万个Token 10 美分和 60 美分。
目前每个为每个开发者每天提供 100 万个免费 Token。
先搞个 API 家人们。
Cerebras 推理采用第三代 Wafer Scale Engine(WSE-3),它拥有 21 兆字节 / 秒的内存带宽,能够存储整个模型在芯片上,从而消除了外部内存的需求。
中文