Lomsa
746 posts


Lomsa
@lomsa005
#Vibecoder and #AI/#art/#crypto enthusiast. Also, a #chess player. I'm passionate about using #technology to create beautiful and innovative things.
Katılım Mart 2023
166 Takip Edilen76 Takipçiler

When I was a kid, I loved science fiction movies, but I always hated that moment when I realized it was just a guy in a robot costume. I’d think, “One day we’ll have a better solution for this!”
And then CGI came along and it was absolutely amazing.
I also wished the Star Trek computer was real. And now it is -- we have AI!
How anyone could be against technological progress is simply unthinkable to me.
Technology is magical. 🪄
English
@dhruvtwt_ @nvidia It’s available, but not via API, right? Also, it's $0.80 for input and $4.00 for output. That is cheap, bro
English

Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: build.nvidia.com/models
– base_url = "integrate.api.nvidia.com/v1"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.

English
@dhruvtwt_ @nvidia Yeah, but those are cheap models. The biggest companies should give us some good free stuff, just like Google AI Studio is doing😅
English

@Designarena @Alibaba_Wan @GoogleDeepMind @bfl_ml Wtf, Why chatgpt is the first, how it's a possible😂
English

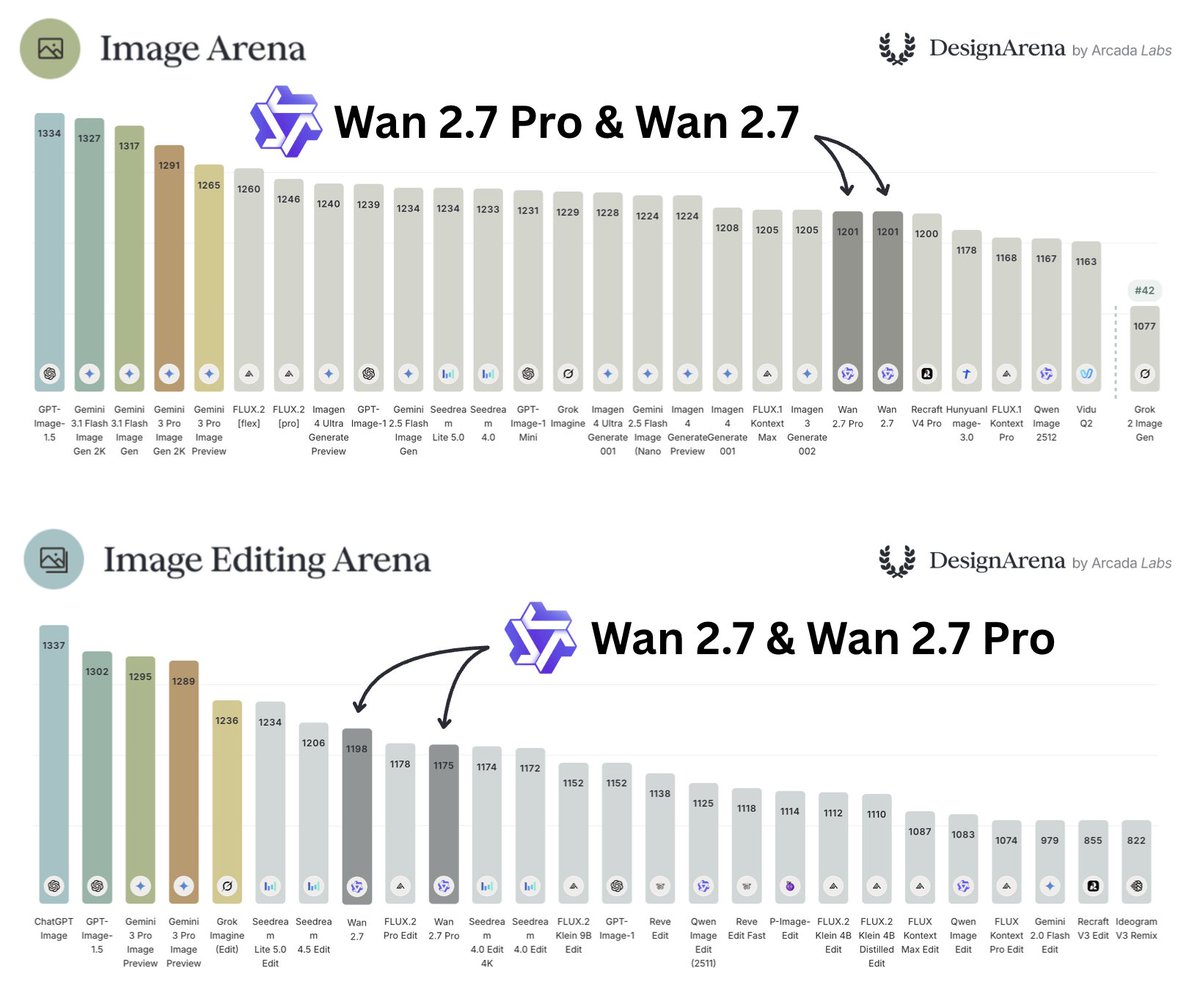
BREAKING: Wan 2.7 Pro and Wan 2.7 by @Alibaba_Wan are #21 and #22 on Image Arena and #10 and #8 on Image Editing Arena!
On Image Arena, these are in the same performance band as Imagen 4 Generate 001 by @GoogleDeepMind and FLUX.1 Kontext Max by @bfl_ml
On Image Editing Arena, Wan 2.7 is in the same performance band as Seedream 4.5 Edit by @BytedanceTalk
Congrats to the @Alibaba_Wan team on the launch!
English
@HarshithLucky3 I think they nerfed it on api's too, I didn't think it is same model as it was when release😭
English

@thsottiaux Clever... it always changes my Georgian texts and puts some hashed things instead😄
English

Always fun when you notice Codex being clever in a way you don't expect.
In a session today, it was running a slow build process and got annoyed (don't we all). Before making a change it checked that progress was actually happening and did so not by checking the logs, but by checking CPU usage.

English

Gamma 31b model outperforming Qwen 3.5 397B is nuts to me.
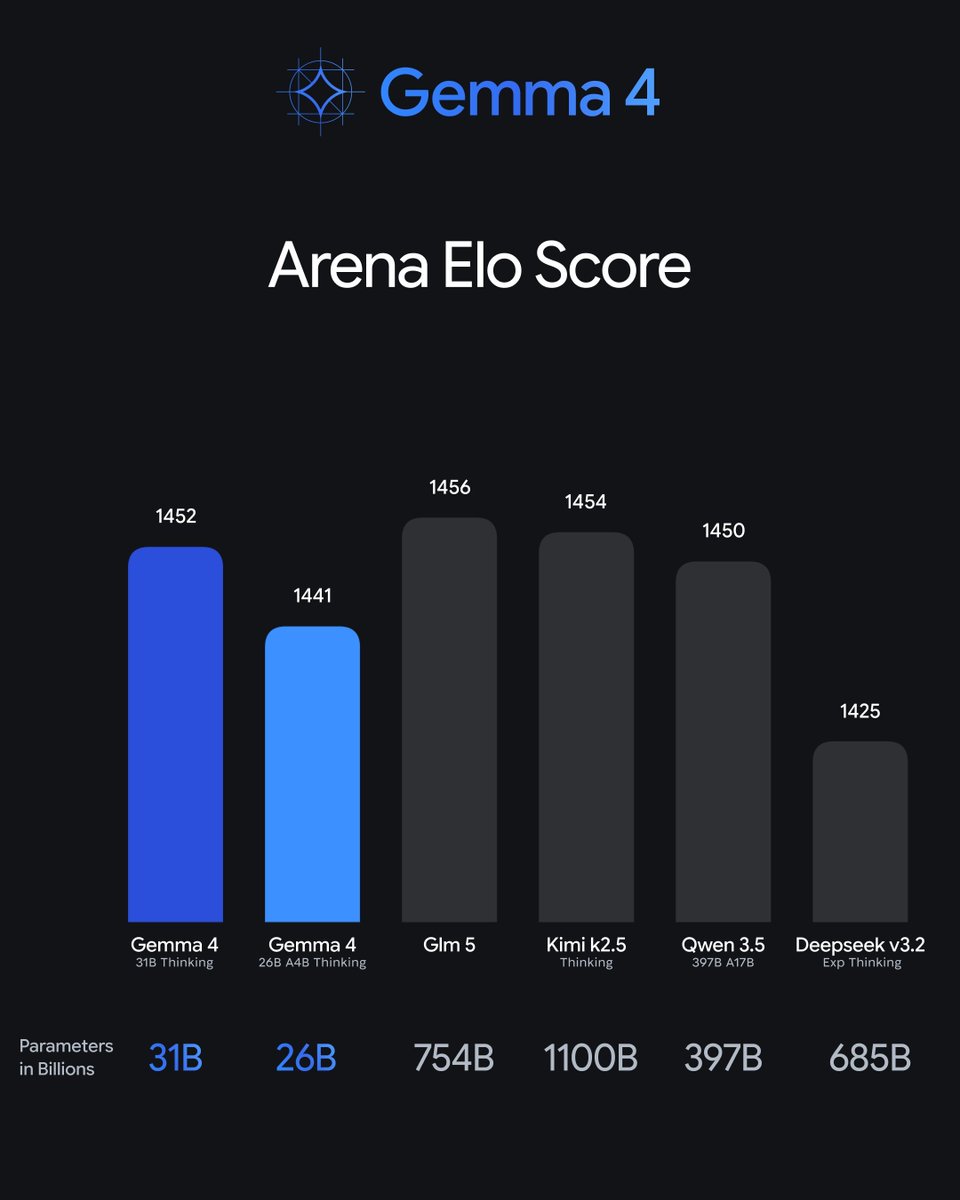
Google DeepMind@GoogleDeepMind
Available in four sizes: 🔵 31B Dense & 26B MoE: state-of-the-art performance for advanced local reasoning tasks – like custom coding assistants or analyzing scientific datasets. 🔵 E4B & E2B (Edge): built for mobile with real-time text, vision, and audio processing.
English

Fork it
Drop your landing page URL
I'll give 1 piece of advice to as many of you as I can
English

@WillowVoiceAI please just smile guys😳 you are scare me with those faces👀
English

@VadimStrizheus Hmm, I don't remember😂 just making small corrections, we are cooked😁
English

Our Codex dashboards are showing increased rate of users hitting rate limits and since we don't fully understand why I have made the cautious decision of resetting the usage limits for all plans. Enjoy.
I also wanted to celebrate us finding a pocket of fraudulent accounts that we banned and have helped us regain some compute. The fight against abuse never stops, but it's important to mark the moment and make it a little shared victory.
English
@googleaidevs I started using skills and it's really something else🙂 Thanks for updates🙏
English

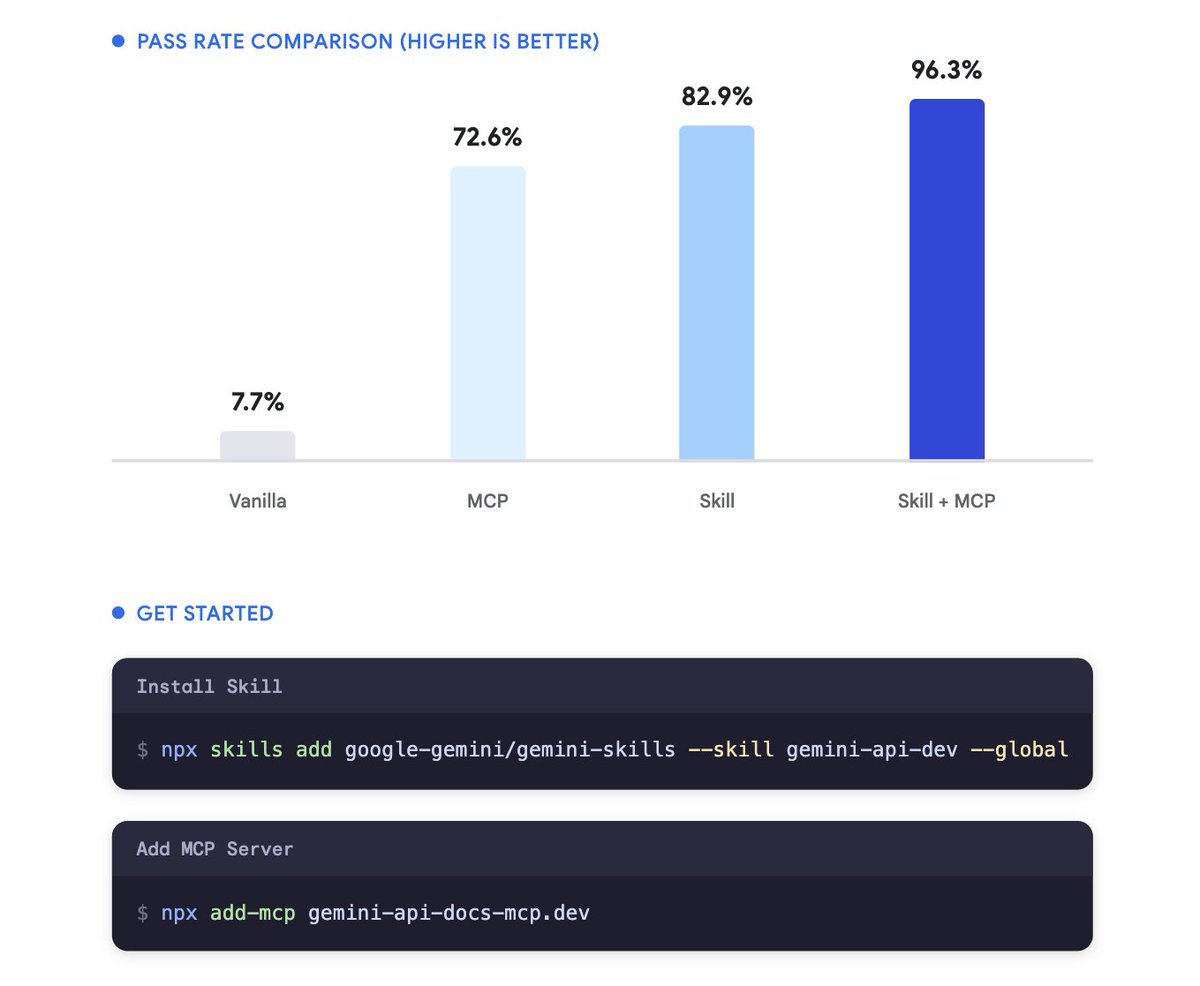
Connect your coding agent to the latest Gemini API docs with our new MCP server and developer skills. Run a single command to unlock your agent's highest potential with less tokens.
English
@Star_Knight12 Yeah, they don't sleep because all of them are AI agents😁
English



@being_mudit I use lots of stuff way before it comes to public.
English