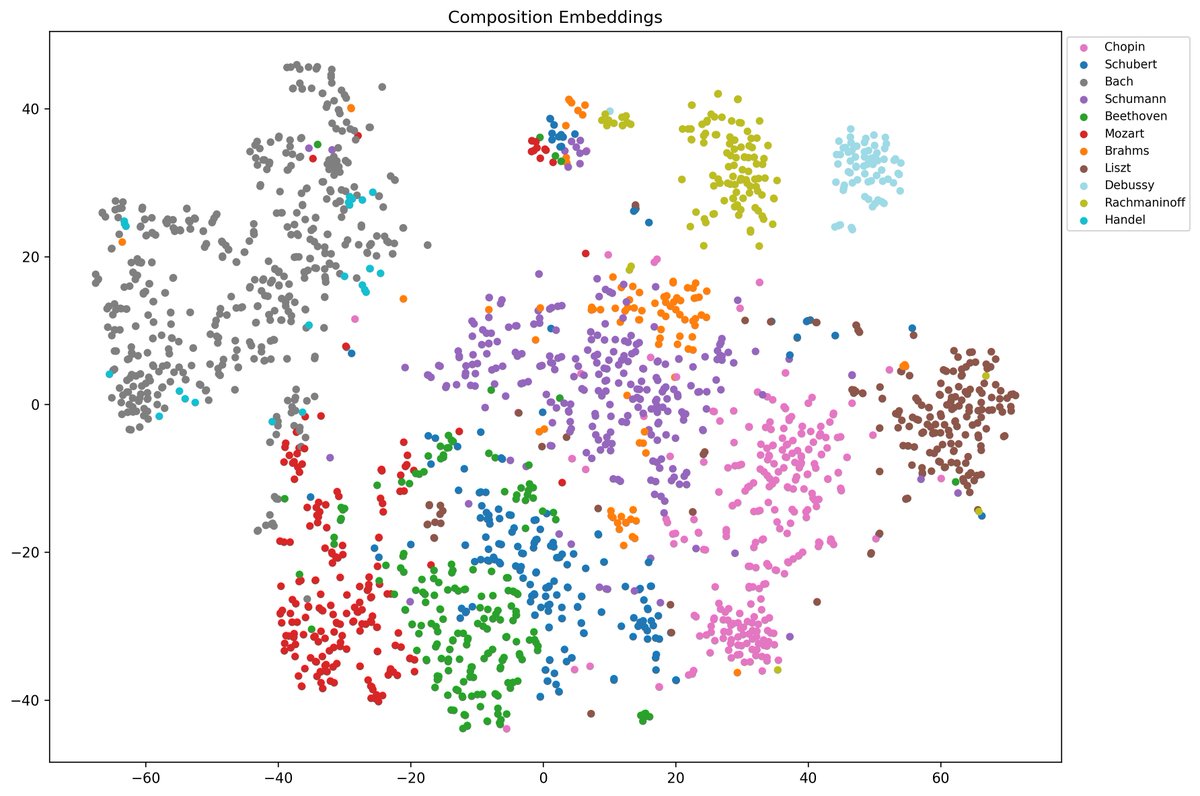
Sabitlenmiş Tweet

I’ll be at #ICLR2025 this week presenting our work on curating large datasets for symbolic music modelling. Excited to chat about generative music, audio language models, and audio/speech LLMs (DMs open!).
📄 Paper: openreview.net/pdf?id=X5hrhgn…
🔗 Dataset: github.com/loubbrad/aria-…
🗓️ Fri 25 Apr 3 p.m. - 5:30 p.m | Hall 3 + Hall 2B #116

English