Luís Marnoto
528 posts

Luís Marnoto
@luispl77
Computer engineer
Lisbon, Portugal Katılım Ağustos 2015
318 Takip Edilen69 Takipçiler
Luís Marnoto retweetledi

Do people like this? We don't do this for codex because it exists to help you and it's important that you remain the owner and accountable for your work without AI taking credit. At the same time it does mean that you can't trace how popular codex is among repos.
Yuchen Jin@Yuchenj_UW
I noticed something interesting: Claude Code auto-adds itself as a co-author on every git commit. Codex doesn’t. That’s why you see Claude everywhere on GitHub, but not Codex. I wonder why OpenAI is not doing that. Feels like an obvious branding strategy OpenAI is skipping.
English
Luís Marnoto retweetledi

Nick Fuentes stresses the importance of THINKING, rather than being concerned with reading a ton of books
"It's important to be able to think systematically... ponder. And people are always so caught up on reading, and that's so wrong."
English
Luís Marnoto retweetledi


Luís Marnoto retweetledi

Don’t stop trying because it didn’t work.
It never works the first time.
English
Luís Marnoto retweetledi

Luís Marnoto retweetledi

Congratulations to Novak Djokovic for winning the Australian Open! This year he wins the trophy and will become the No. 1 men’s tennis player in the world. Last year the Australian government deported him for not being vaccinated. Freedom is always worth fighting for.
English
@flowersslop The stagnation is incredible.
The "big" inovation this year was a simple MODEL ROUTER.
Deep Learning winter begins today
English

GPT-5 will be a disappointment.
It's just a model router, which will help it finally, at most, match Claude 4 Sonnet.
Today marks the day everyone realises scaling the vanilla transformer is not going to cut it.
Missing Continuous Learning, Long Term Memory, Infinite Context.
English
@mark_k The GPT-5 architecture will win, because they have multiple models all built into one.
And this includes one or more Specialized Coding Model, INSIDE GPT-5.
One for web dev, one for backend. etc.
Sonnet isn't a specialized coding model, and that's why it will fall short.
English

GPT-5 will easily beat Claude 4 with coding, and if the pricing is ok the good times will be over for Anthropic.
English


I recently moved to the Code RL team at Anthropic, and it’s been a wild and insanely fun ride. Join us!
We are singularly focused on solving SWE. No 3000 elo leetcode, competition math, or smart devices. We want Claude n to build Claude n+1, so we can go home and knit sweaters.
Anthropic@AnthropicAI
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4. Claude Opus 4 is our most powerful model yet, and the world’s best coding model. Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
English
@karpathy It's called continuous learning and long term memory, and you are correct
English

We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler.
I was prompted to jot down this shower of thoughts after reading through Claude's system prompt, which currently seems to be around 17,000 words, specifying not just basic behavior style/preferences (e.g. refuse various requests related to song lyrics) but also a large amount of general problem solving strategies, e.g.:
"If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step."
This is to help Claude solve 'r' in strawberry etc. Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).
English
@Citrini7 This is false. If you look at equivalent open-source models such as DeepSeek R1, the electricity costs are nowhere near the API pricing
English

@ns123abc Show an aerial image of a bunch of houses in a neighborhood. Tell it to count the houses.
100% fail rate
English

@kalomaze Even if the goal is balance, if you don't switch domains its expected that some experts are not used. The model was trained to balance experts on trillions of tokens, yours is only 120k tokens
English

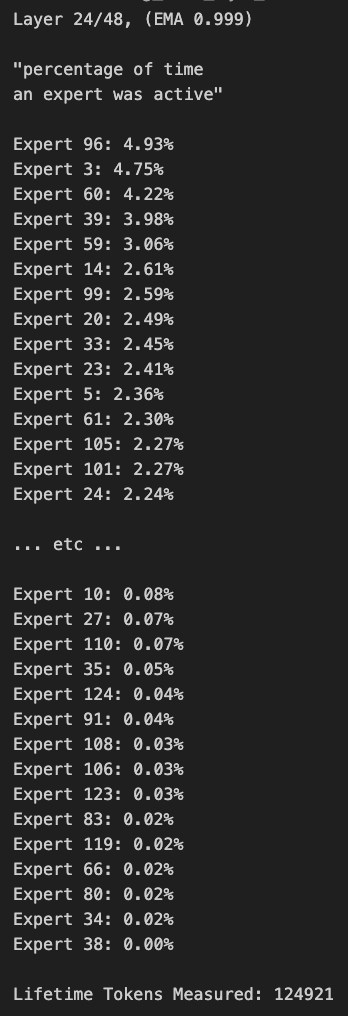
@louisvarge @GroqInc Pretty sure their hardware does not support large MoE models at faster speeds that GPUs
English

@shaoruu @cursor_ai A way to never have to start a new conversation. Long-term memory. That's where the money is at, infinite and efficient context. Too bad it might not depend on you, but the models themselves.
English

what should i add to @cursor_ai that would make u 10x more productive? feature requests, tiny nits, anything :)
English
@IterIntellectus IKR, what’s with these random 100k likes posts that make no sense? They’re not even funny or interesting
English