Sabitlenmiş Tweet
Luis
189 posts


Luis retweetledi


Auto-research for ML training models is all the rage now, but underrated is: auto-research for data!
Sure, you can squeeze out a bit of model performance by optimizing hyperparameters, but code agents can do data work that has been very labour intensive and required a lot of attention to a lot details effortlessly:
> download data from many different data sources
> bring all the data sources into uniform format
> do detailed EDA: find patterns and outliers
> look at 100s of samples and take detailed notes
> make beautiful infographics rather than mpl plots
> iterate on data filtering by looking at more samples
> make a simple pipelines robust and scalable
It's now possible to write data pipelines for dozens of data sources in hours that would have taken weeks of reading many docs, debugging APIs and data formats, wrangling outliers and missing data.
A few weeks ago we gave Claude access to the CPU partition of our cluster and it iteratively refined filters to retrieve a domain subset of FineWeb. This would have taken me 2-3 days to work through while it took Claude just a few hours with almost no babysitting and with a nice logbook.
Thus the long tail of small, niche data sources becomes more accessible and can be aggregated to even larger high quality datasets for cool applications.
Data has been fuelling LLM progress more than model architecture innovations, so I am very excited about this!
English


be me, aka my three body problem
> wake up: jax is so going to take over
> sip coffee: but jax-metal sucks
> get coding: apple silicon training rocks
> more coffee: torch.device("mps") is my best friend
> more more coffee: torch is king
> more coding: but jax is so cool...
English

today is my last day at hugging face
feeling really grateful to have worked with such an amazing team and learned so much along the way. i’m proud of what we accomplished together, especially the smollm series. building that project from scratch, putting so much into it, and getting to iterate on a model and training recipe that pushed the frontier for its size was really rewarding
i hope i was able to play a part in making model training more accessible and in pushing the open model ecosystem forward. i’m also very thankful to hf for giving me the chance to share my passion for llm research, especially here, and to connect with so many awesome people
things can get quite intense in this field, but i’m still very excited about the next challenges and about the good this technology can do
but first, taking a few weeks break :)
English
@andimarafioti Ofc, had to check if the models opinion of you was accurate ;)
English

@cgeorgiaw Can highly recommend, improves mental clarity and creativity for me if I sleep longer
English

I’ve been sleeping 10+ hours every night for the last week
Is this normal?
English
Pretty excited about this project I'm releasing later this week :) (audio only)
English
Had a ton of fun giving a talk today on how I’ve been looking at Robot Learning.
Giving talks is a great way to pull one’s ideas together, and I was happy to share my (highly opinionated, hehe) take with such a techies crowd :)

English
Luis retweetledi
@vishaal_urao @shushengyang This is a very welcome sight in the current world of LLM-reviews
English

We also emailed the authors of Cambrian-S sharing our findings, we included their response in Appendix! +1 for Open Science!🧑🔬
Great 1st step by the Cambrian-S team and we hope to jointly push for better spatial supersensing video models in the near future!🙏
@shushengyang

English
🚀 New paper!
arxiv.org/abs/2511.16655
Recently, Cambrian-S released models & two benchmarks (VSR & VSC) for “spatial supersensing” in video!
We found:
1️⃣ Simple no-frame baseline (NoSense) ~perfectly solves VSR!
2️⃣ Tiny sanity check collapses Cambrian-S perf to 0% on VSC!
🧵👇

English

That’s the direction I want. NeRF/3DGS-SLAM works along roughly those lines. We predict what we’ll see next, then update our model based on what we predicted vs. what we actually see. Except there, the prior/model is based solely on previous test-time images from the same scene.
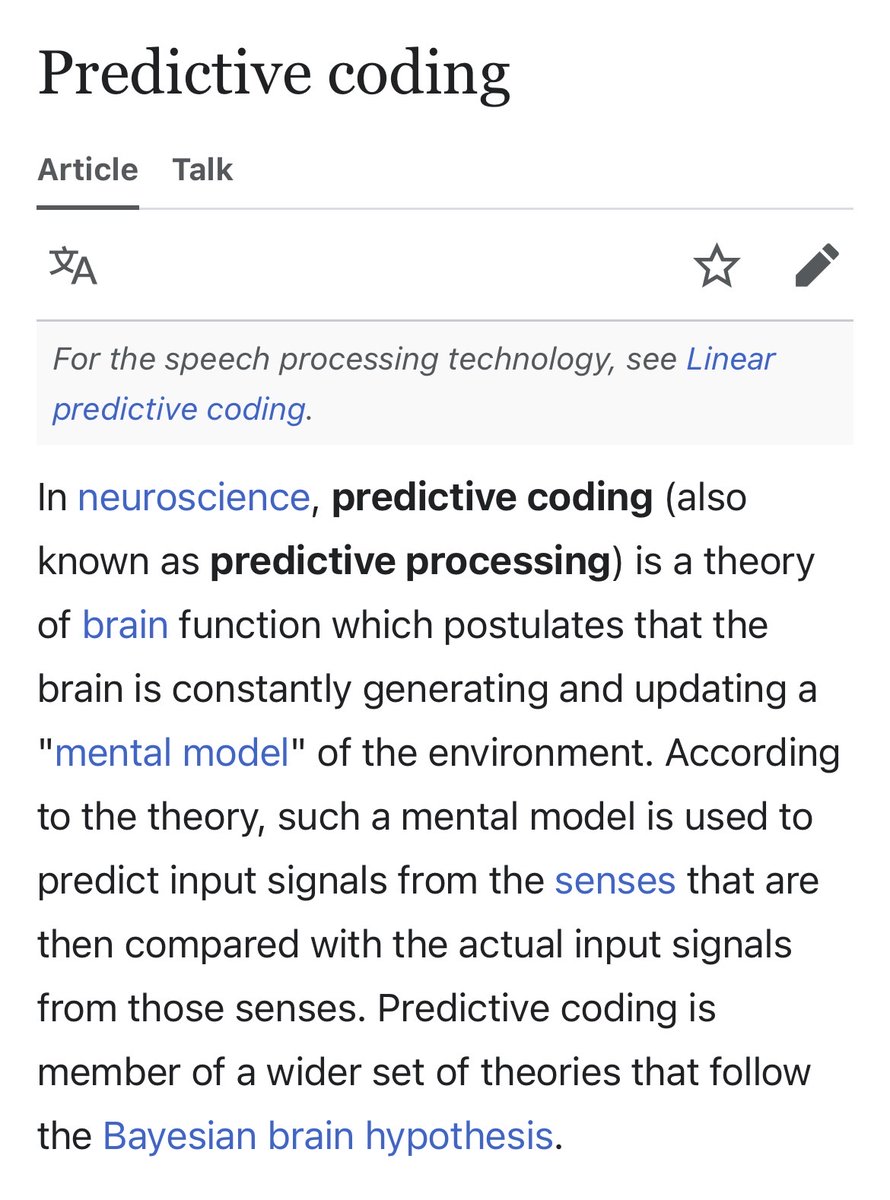
Saining Xie@sainingxie
looking ahead, we’re prototyping something new -- we call it predictive sensing. our paper cited tons of work from cogsci and developmental psychology. the more we read, the more amazed we became by human / animal sensing. the human visual system is super high-bandwidth, yet insanely efficient. each eye’s 6 million cone receptors can transmit ~1.6 Gbit/s, yet the brain uses only about 10 bits/s to guide behavior. most sensory data is filtered, compressed, and everything is autopiloted -- you don’t even notice. how does our brain pull that off? one leading theory: your brain runs a predictive world model in the background for sensing, constantly forecasting the future and comparing it to what actually happens. - if the prediction error is low → it’s expected, you can ignore it. - if it’s high → it’s a surprise, and your brain pays attention, updating memory. we don't have anything comparable in LLMs right now. to test this idea, we trained a latent frame prediction (LFP) head on top of Cambrian-S. we estimate "surprise" during inference, and use it in two ways: 1️⃣ surprise-driven memory management -- compress or skip non-surprising frames, focus compute on surprising ones. 2️⃣ surprise-driven event segmentation -- use surprise spikes to detect event boundaries or scene changes. by leveraging signals from this internal predictive model, we’re already seeing promising gains on spatial cognition tasks. it’s just a toy predictive world model -- but with this mechanism, our small model outperforms gemini on vsi-super. [6/n]
English

@Prince_Canuma @willccbb @MaziyarPanahi @FernandoNetoAi @ivanfioravanti There are so many examples like that in so many of the typical benchmarks, don't get me started!
The real question is how come most models are really good at these
English

We need better evals!
What is the point of this question in MathVista?
Even I can't answer without googling it.
@willccbb @MaziyarPanahi @FernandoNetoAi @ivanfioravanti

English
English
@leothecurious @gabriberton I really like CUT3R's recurrent approach conceptually but there are clear limitations to this approach.
English

Summary of this conversation:
VGGT is faster. But not robust to OOD data. Robust to doppelgangers (e.g. buildings with two similar walls on opposite sides).
COLMAP gives more precise poses. More scalable. Works well on ~anything except doppelgangers
VGGT with BA would help pose precision and probably coming soon
For most people speed is not a priority (nobody cares about "online reconstruction")
COLMAP is actively maintained and improved by the goats of 3D. It is here to stay
Gabriele Berton@gabriberton
Is COLMAP still widely used or are Mast3r / VGGT taking over?
English
@lusxvr you broke the trend with naming! But also, SmolVision? didn't make sense xD
English

@_fracapuano @Arthur_Bresnu @UniofOxford @j_foerst @FLAIR_Ox @IngmarPosner @a2i_oxford Its a crazy world indeed, but you're obviously always welcome at my place!
English
English
(pretty big) Life update: after a fantastic time in Paris 🇫🇷, I have moved to the UK 🇬🇧, and started my PhD at @UniofOxford. I will be working on (robot) learning with @j_foerst @FLAIR_Ox and @IngmarPosner @a2i_oxford!

English
@lusxvr Did you order one? We are getting some shipped in time for Christmas 💕
English
I finally got a reachy mini beta! Setting down to build it now 🤗

English
You can now train SOTA models without any storage!🌩️
We completely revamped the Hub’s backend to enable streaming at scale.
We streamed TBs of data to 100s of H100s to train SOTA VLMs and saw serious speed-ups.
But how?
English