
Marek Galovic
45 posts
Marek Galovic
@marek_galovic
Building the next-generation of search @topk_io. ex-Pinecone, ex-Shopify.
Katılım Ağustos 2011
348 Takip Edilen129 Takipçiler
@tomaarsen @matospiso Sparse-only can work reasonably well with some tuning, but obviously, reranking makes it better. @tomaarsen, any plans to add multi-vec model support in Sentence Transformers?
English

@matospiso Very cool. I bet you can implement this into the SparseEncoder in Sentence Transformers too, with custom modules, but it would only output the sparse embeddings and not also the multi-vector embeddings for reranking, sadly :/
English

for anyone interested, here's the poster we presented at ECIR Late Interaction Workshop :)
also a blogpost describing the method in more detail
topk.io/blog/20260311-…

Marek Galovic@marek_galovic
(3) Scaling multi-vec retrieval: Exact MaxSim is very expensive, so we need to prune the search space and refine candidates. Broadly, there are two approaches: - token-level ANN (PLAID, WARP, ...) - dense/sparse compression MUVERA (Google) / SMVE (developed by @matospiso & me).
English

“design a RAG pipeline for 10M docs with zero hallucination”
apparently this was asked in a Google L5 interview round. came across it somewhere on the internet and honestly it’s a way more interesting system design problem than most classic distributed systems questions
1. ingest + normalize docs
- remove duplicates, standardize formats, extract metadata, maintain version history
2. hybrid retrieval (BM25 + embeddings)
- BM25 handles exact keyword matching while embeddings capture semantic meaning
- semantic search alone usually struggles with precision at massive scale
3. ANN retrieval + reranking
- ANN (Approximate nearest neighbor ) quickly pulls top candidate chunks from millions of docs
- then a reranker rescoring step improves relevance by deeply comparing query vs retrieved chunks
4. source confidence scoring
- every retrieved chunk gets scored based on freshness, trust level, overlap and retrieval consistency
- low-confidence context should never heavily influence generation
5. constrained generation
- the model is only allowed to answer using retrieved context (nothing new to be invented outside of the retrieved context)
6. citation-backed responses
- every major claim links back to exact chunks, documents or timestamps
7. hallucination fallback layer
- if retrieval confidence drops below a threshold: “insufficient evidence found”
8. continuous evals
- run adversarial queries, retrieval recall benchmarks and hallucination tests continuously
9. caching + memory layer
- cache high-frequency enterprise queries and retrieval paths (improves latency and output)
10. observability everywhere
- trace retrieval paths, chunk rankings, token attribution and failure points
Also at 10M docs, retrieval quality matters more than the frontier model itself.

English
While SMVE is great, it's only a part of the full picture. You still need model inference, durability, a scalable write & read path, doc. quantization, refinement, and more.
@topk_io already solved it and offers an e2e solution for multi-vec retrieval on top of object storage.
English
Cool talk on multi-vector retrieval, why it beats single vector methods, and why it's hard to use in practice.
🧵on what's next (1/n):
Ben Clavié@bclavie
Information Retrieval is about making knowledge accessible. Late Interaction is the best way to do that today. But now that we have a new kind of users, it's time to zoom out so we can plan the future of retrieval. I gave a talk about this at @ir_tsukuba #slide=id.p" target="_blank" rel="nofollow noopener">docs.google.com/presentation/d…
English
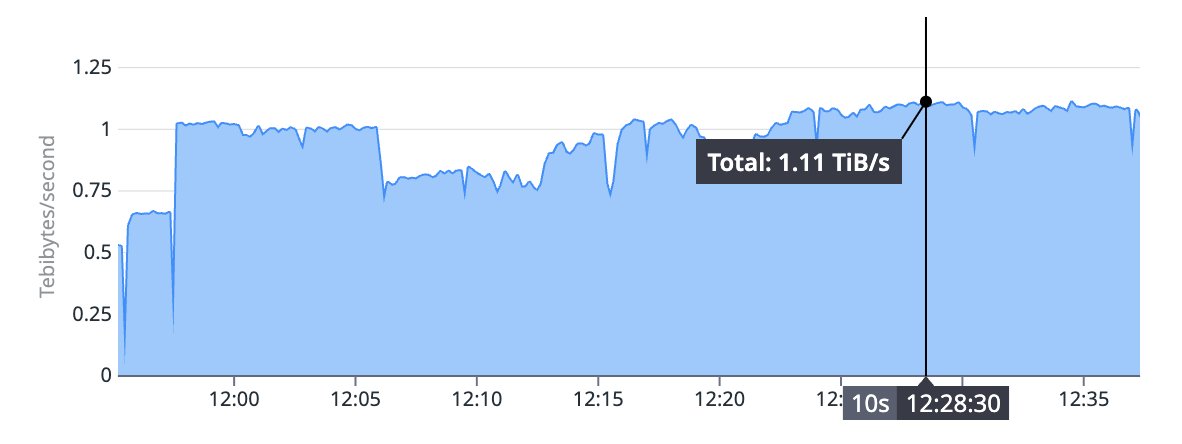
running multi-vec search at 1.1TB/s inside @topk_io to mine hard negatives for better multi-vec model is pretty cool
English

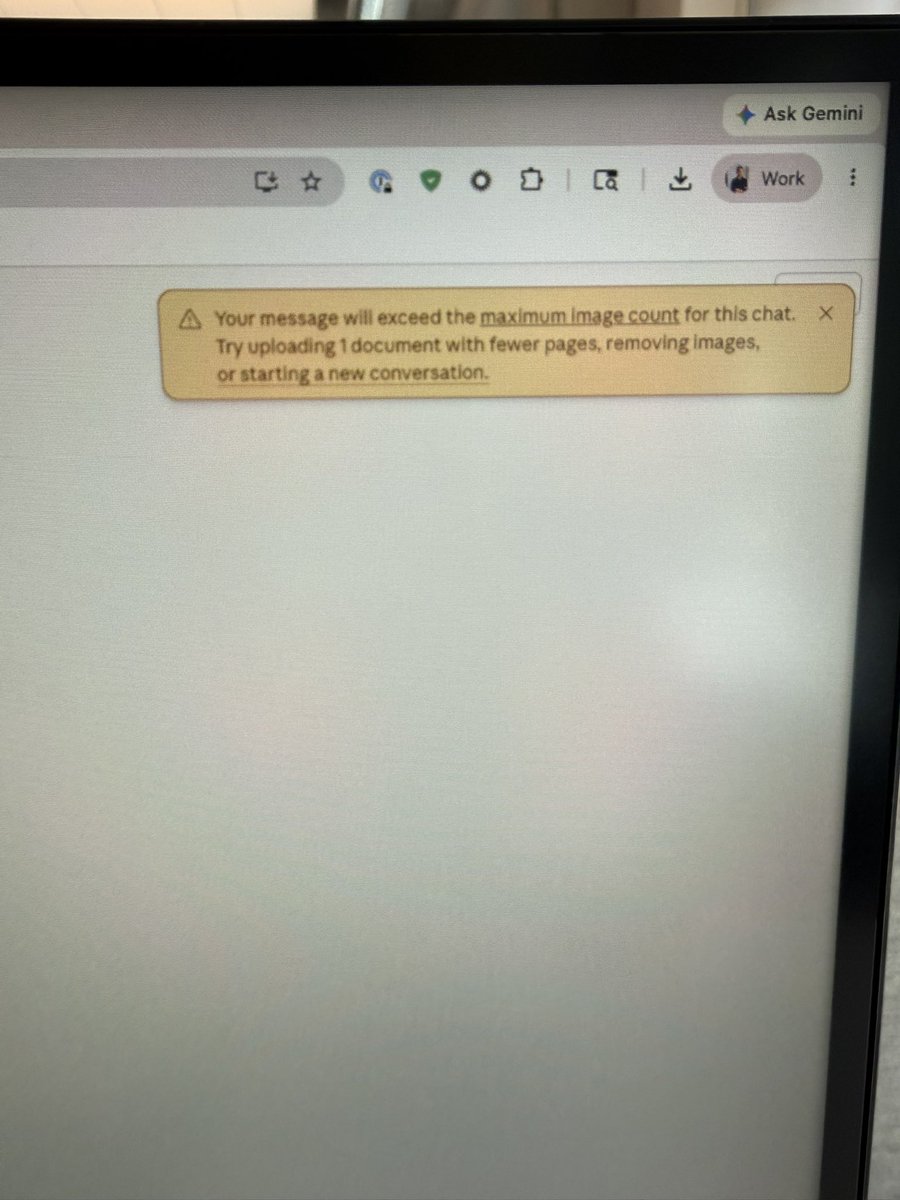
Use Claude they said.
Upload your decks the said.
Unleash all this productivity they said.
But apparently, I first need to start a new chat, delete some of the deck and not exceed the maximum image count…just like my existing brain.
English
Marek Galovic retweetledi

TopK is heading to @AICouncilConf in San Francisco.
We're proud to be sponsoring this year and excited to connect with teams building real-world AI systems.
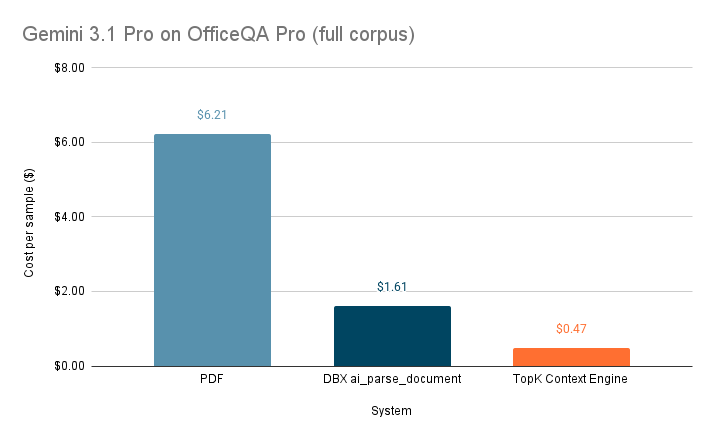
At the Expo Hall, we'll be showcasing how the TopK Context Engine turns unstructured documents into evidence-backed context to make vertical AI agents more accurate and trustworthy.
Come find us — we'd love to meet.
May 12–14 · SF Marriott Marquis

English
Marek Galovic retweetledi
Marek Galovic retweetledi

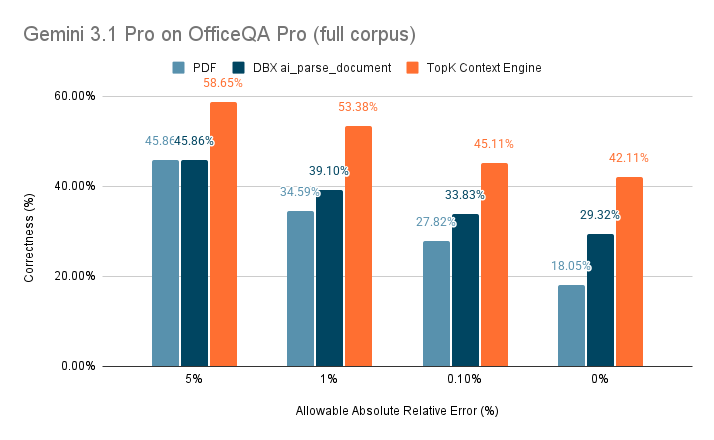
The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!

English