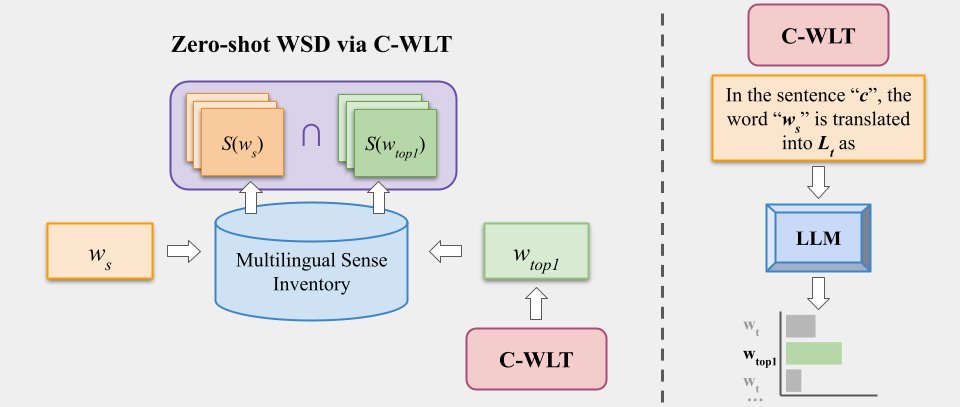
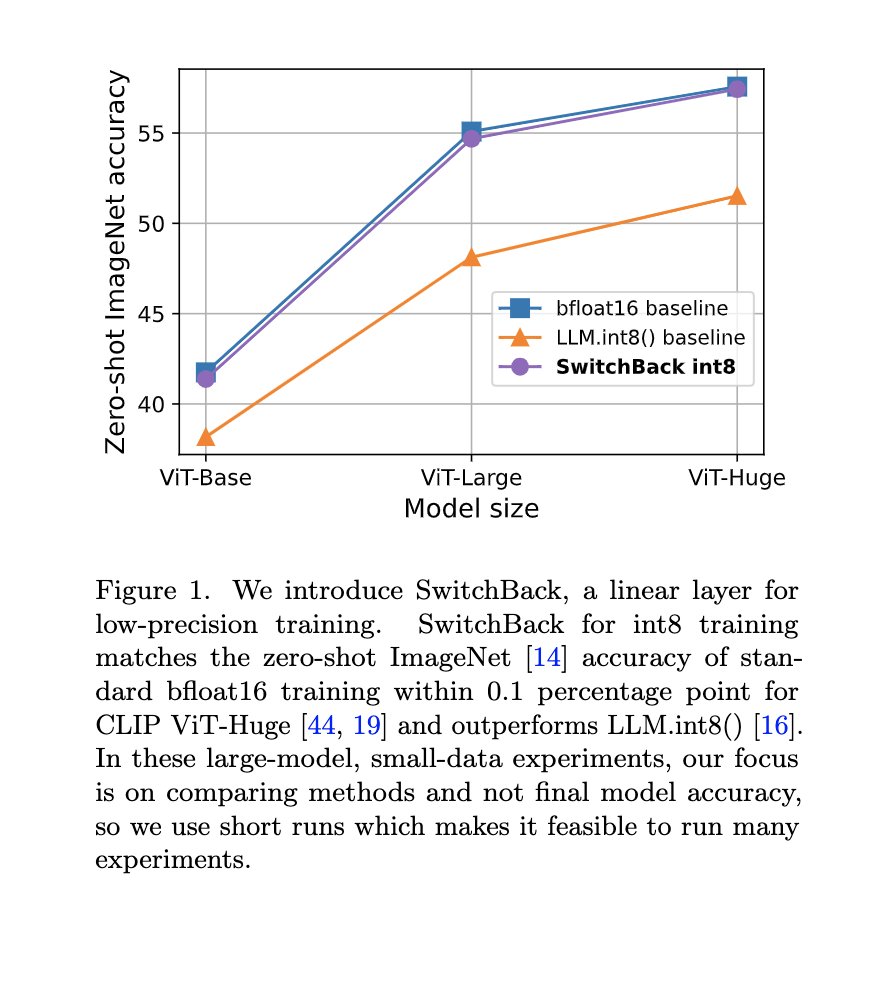
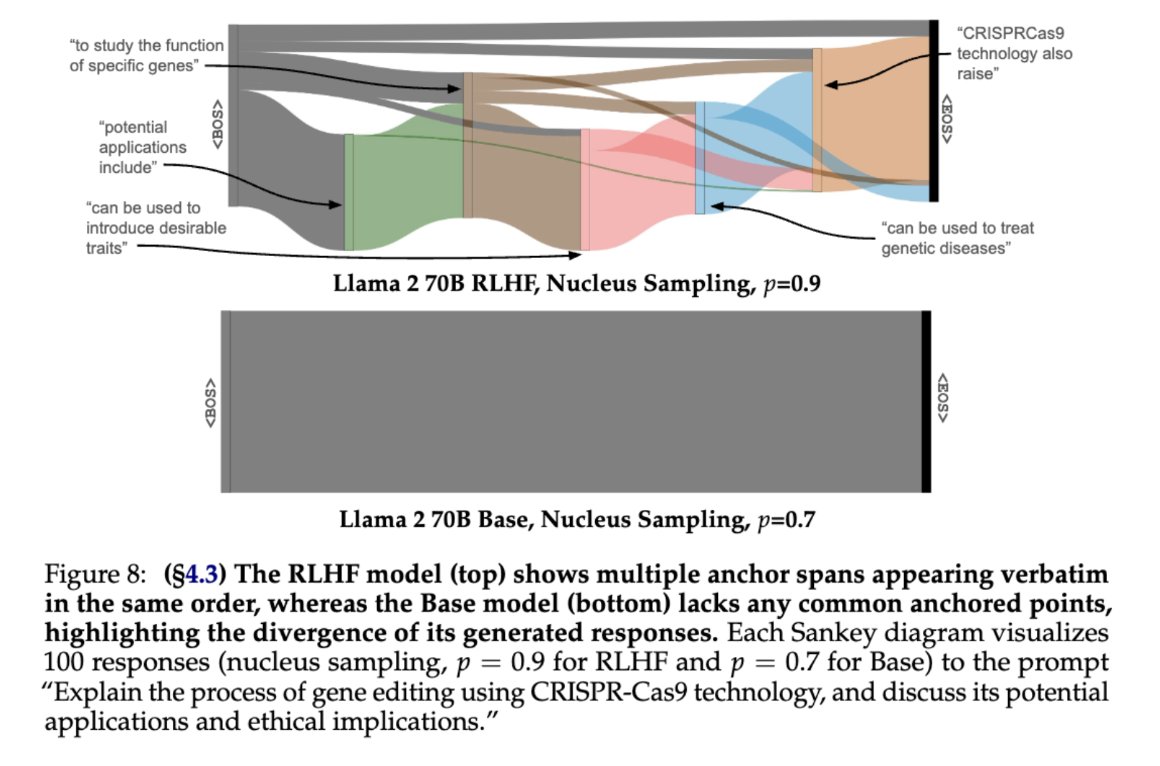
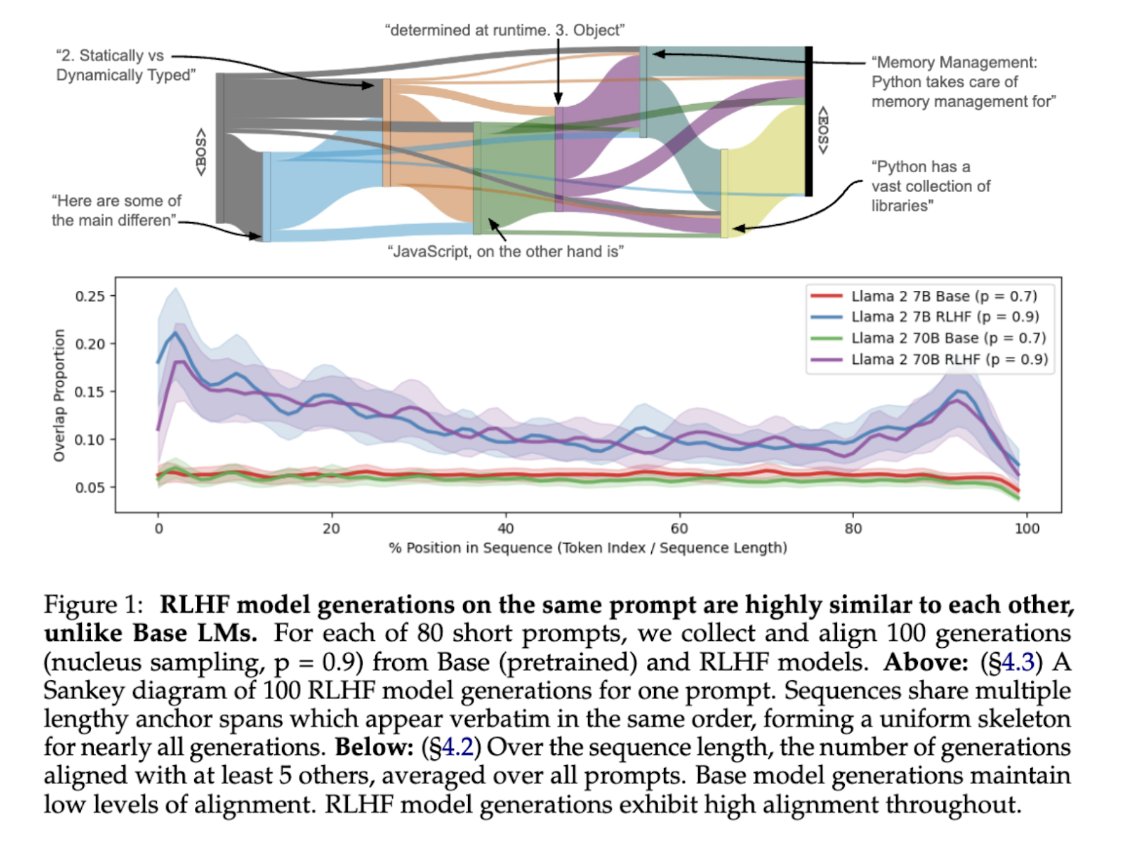
Sabitlenmiş Tweet

We nearly drove ourselves insane trying to reproduce scaling laws papers 📉
So of course we wrote a paper about it 😵💫
1/9

English
Margaret Li @ Neurips ‘25
70 posts

@margs_li
👩💻 PhD student @UWCSE / @UWNLP & @MetaAI. Formerly RE @FacebookAI Research, @Penn CS | 🏂💃🧋🥯 certified bi-coastal bb IAH/PEK/PHL/NYC/SFO/SEA




For this week's NLP Seminar, we are excited to host @margs_li and @ssgrn ! The talk will happen Thursday at 11 AM PT. Non-Stanford affiliates registration link: forms.gle/cvGobkVshhJcvN…. Information will be sent out one hour before the talk.