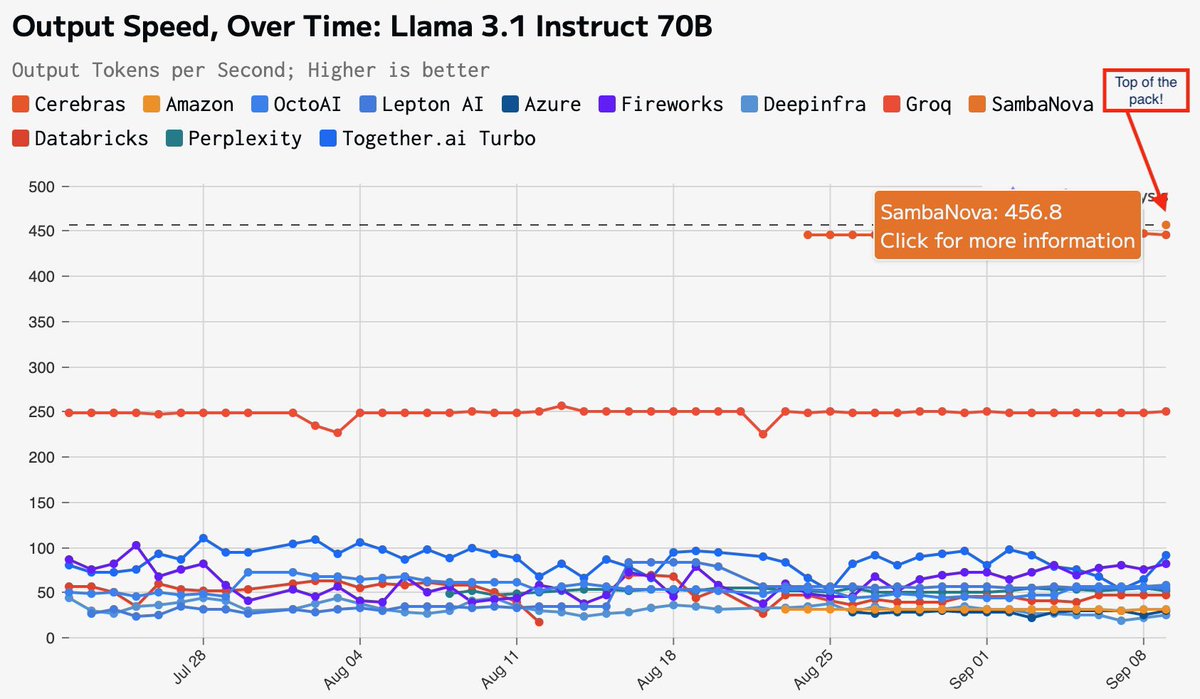
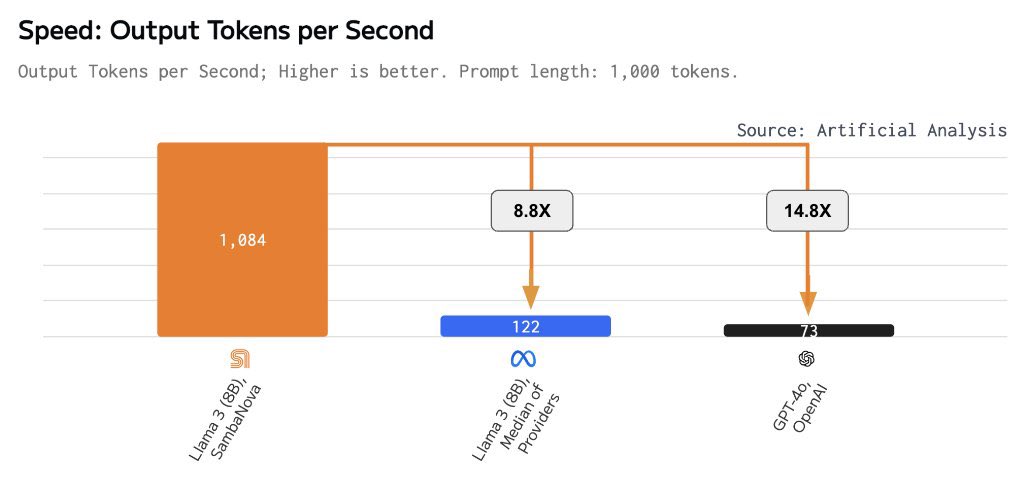
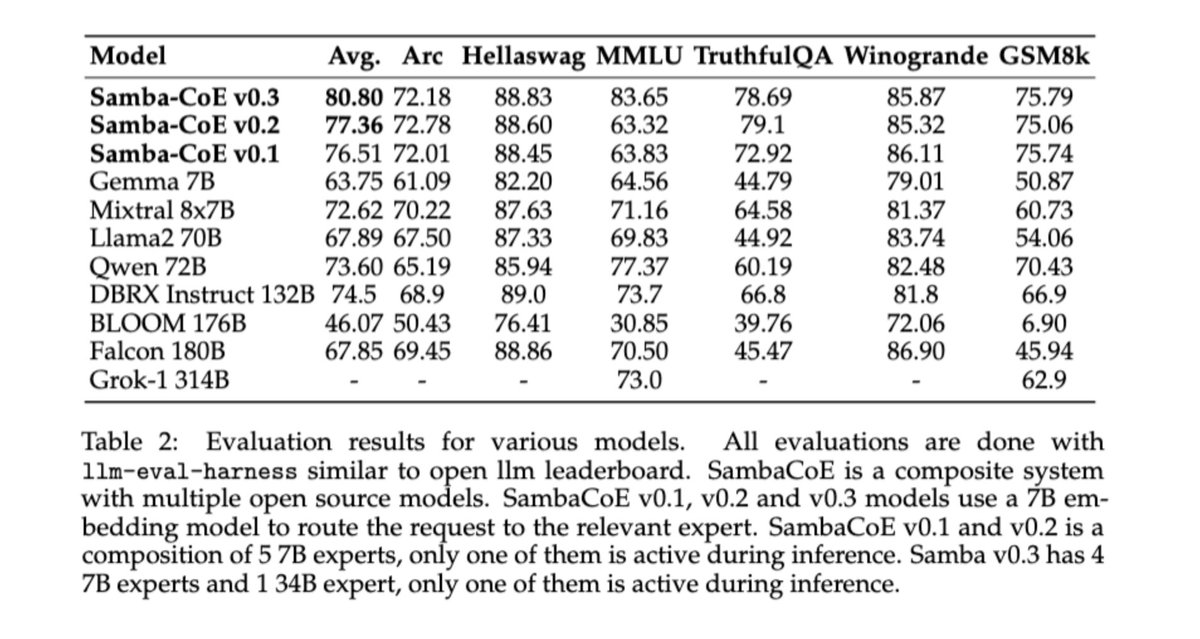
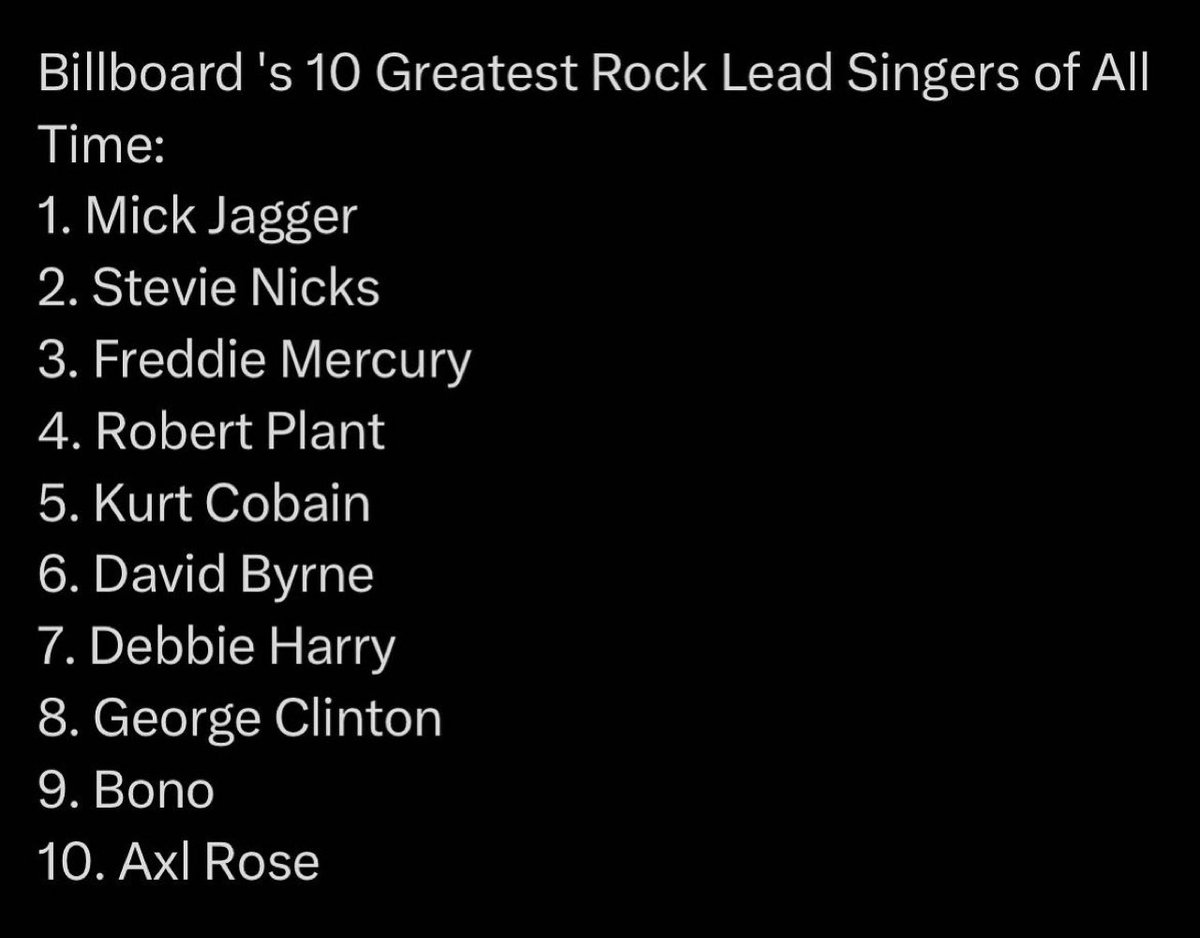
🔥 Pre-IPO Funding | New Systems | Global Expansion | R&D Advancement 🎉
Rebellions Inc@Rebellions_inc
We just raised $400M and launched two new products. But the more interesting story is why inference infrastructure is the hardest problem in AI right now – and how we're approaching it.
English