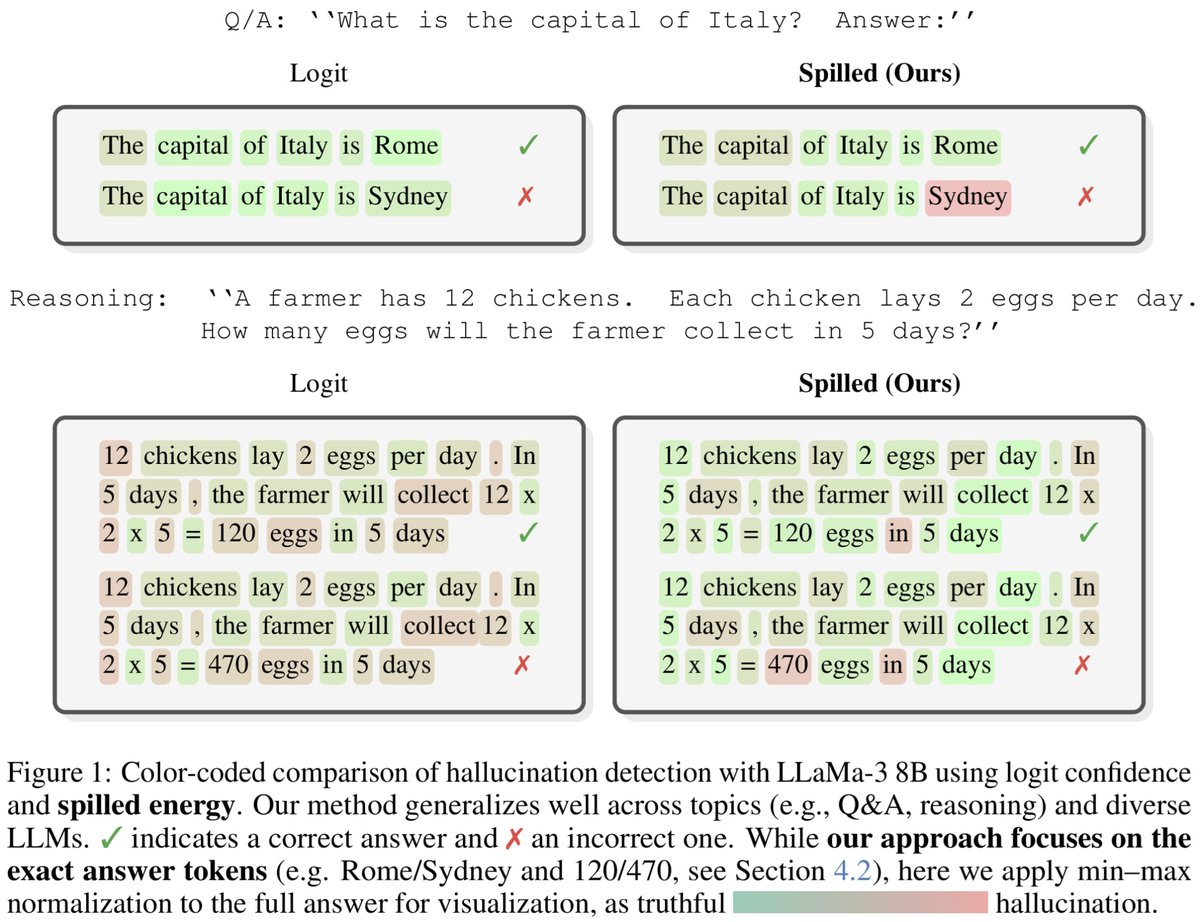
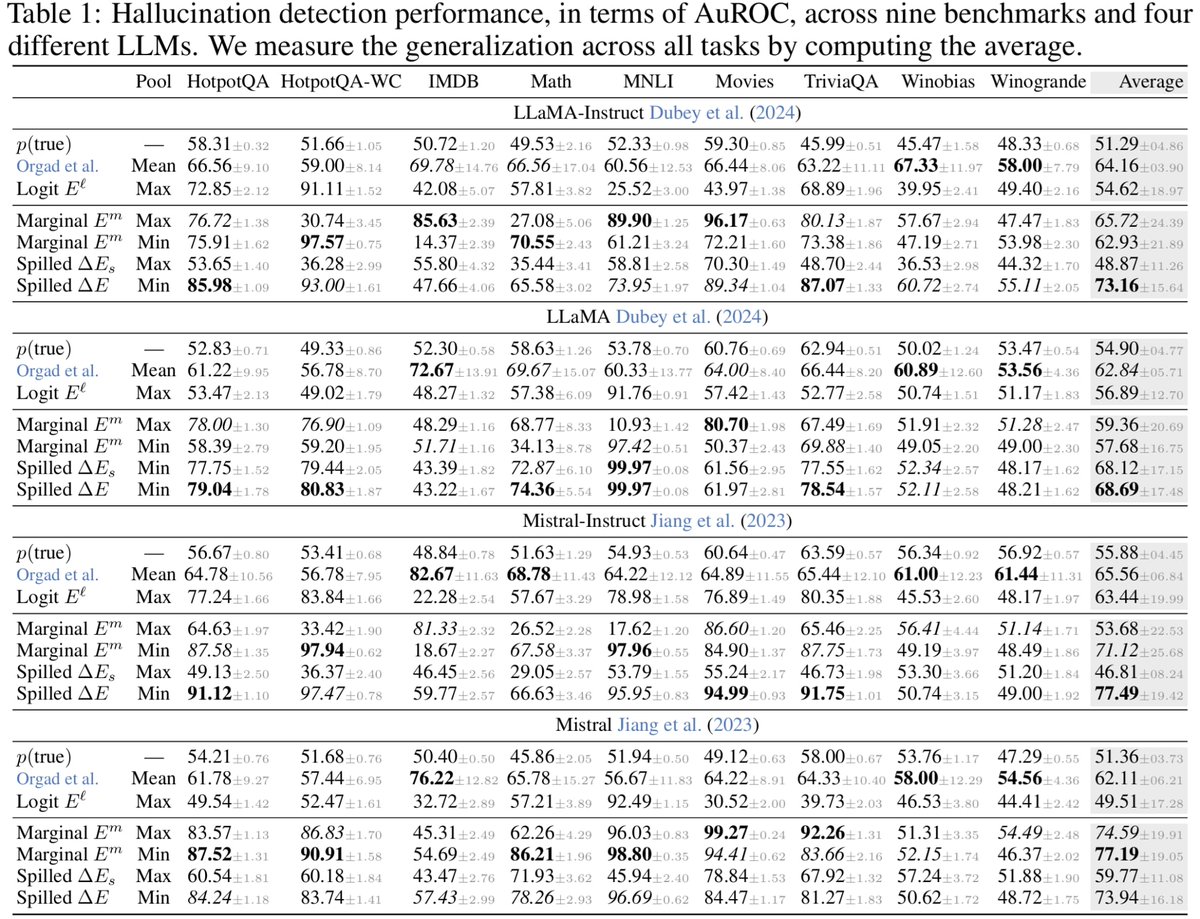
Some nuance: TV distance on its own doesn't behave well under gradient descent, but there are proxy losses which are more stable than TV and give higher acceptance rates than KL. Thread: x.com/agolubev13/sta…
Alexander Golubev@agolubev13
1/8 Training draft models for speculative decoding almost always relies on KL divergence – a proxy, that typically leads to convergence to suboptimal solutions under limited capacity. We introduce LK losses: training objectives that directly target acceptance rate instead. We show consistent gains across 4 architectures and 6 target models (8B → 685B), up to 8-10% acceptance length, with zero added overhead. arxiv.org/abs/2602.23881 🧵
English