
Matteo Paz
21 posts
@jsuarez is this just rollout and training acceleration or is it abstracted/optimized rl algos
English

Overcooked merged into PufferLib today - thanks Roze! Agents trained in <10 seconds on a 4090. This is without hparam tuning for 4.0.
GIF
English
@haider1 this is not true, 4o was pre reasoning. reasoning meant smaller models can punch higher. Economics just dont work out to keep the same large models.
English

greg brockman recently confirmed that "spud" is openai first new pre-train model in two years
since gpt-5.x models seem to build on gpt-4o/4-turbo, if openai RL can push a weaker base model like gpt-4o close to gpt-5.4-x-high-level intelligence
then openai clearly has a secret sauce
English
@Deepans36819800 @GeneralistAI why? human maintenance is a comparatively tiny cost, but a massive reliability driver. Just hire good infra ppl
English

@GeneralistAI We’ll see a fully robot-maintanined data center go live within the next 12 months, by Generalist and a startup.
Infra is about to change faster than most people expect.
English

@IanOsband am i missing something? RL is useful in low signal unsupervised environments, so adding a target nll loss just makes this supervised. In that case the best optimizer is just MLE.
English

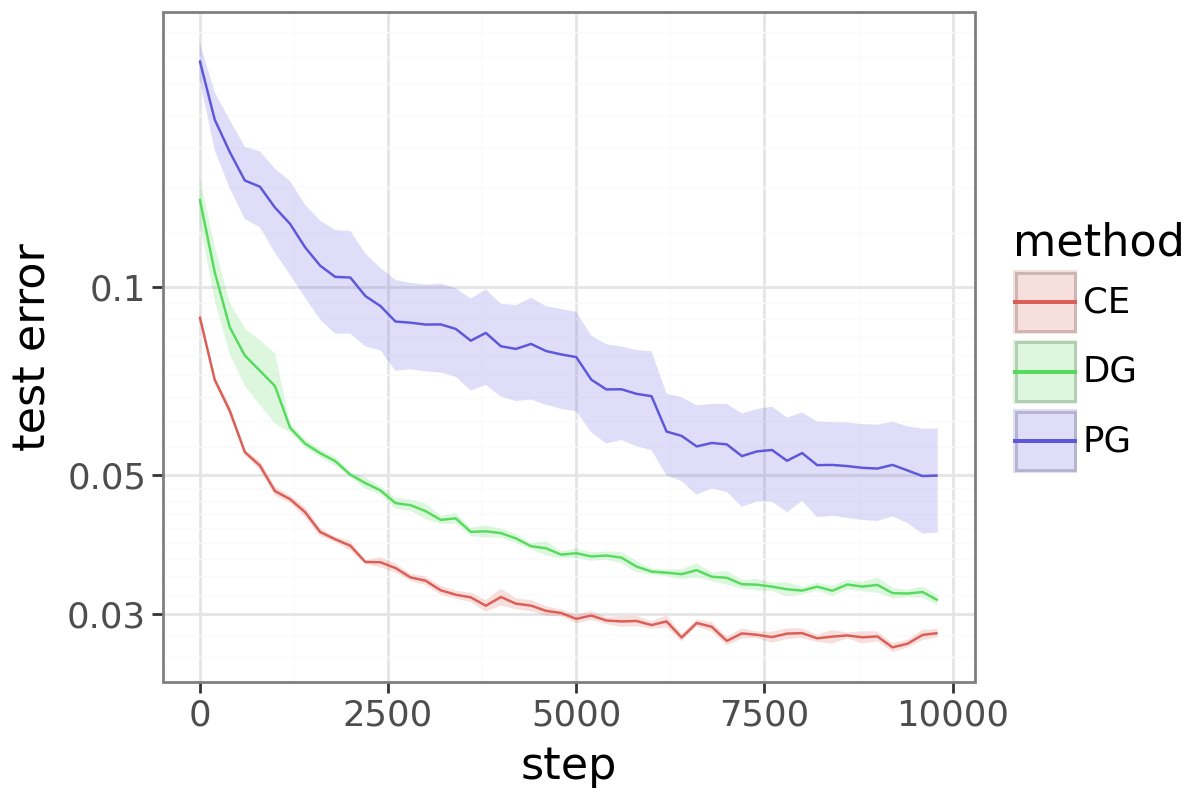
Something is rotten with policy gradient.
PG has become *the* RL loss for LLMs. But it’s not even good at basic RL.
Even on MNIST with bandit feedback, vanilla PG performs far worse than cross-entropy because it wastes gradient budget.
Delightful Policy Gradient: arxiv.org/abs/2603.14608…
English

i always have great ideas that I don't want to be the one to build. I made a little home for these ideas, let me know what you think:
needanidea.xyz
English
@Thomasdelvasto_ the idea is that the information capacity of even 1t params is so vastly below the information content of pretraining text, that the only efficient algorithm *to* learn is approximate to some sort of general intelligence that might have generated it
English

LLMs are basically 'borrowing' human intelligence by training on our output, I don't believe from a first principles standpoint they will be able to get smarter than us unless they train on data that's smarter than us
English

@agniv_s the relevant view I most agree with is that of @_albertgu wrt chunking in nlp. obviously not biological but seems to take advantage of psychological heuristics #a-differentiable-chunking-mechanism" target="_blank" rel="nofollow noopener">goombalab.github.io/blog/2025/hnet…
English

@matteopaz06 Ah, nah I agree (poeppl&embick ‘05 which says the same, though I wonder if they revisited it) on the cts brain. But im thinking about the current “limitation of computability,” wherein you just have to deal with discrete things? (approximation thms seem to be okay with this)

English
in whatever computational way humans develop, its not through text and definitely has nothing to do with a fucking token
Flapping Airplanes@flappyairplanes
The proof that this is possible is all around us: whereas current systems are trained on essentially all of accessible history, humans exceed AI capabilities despite seeing at most a few billion text tokens by adulthood.
English
@agniv_s tokens are just convenient constructs to trade off transformer attention memory to granularity. theres no evidence to suggest brains work discretely. do your eyes stream vision tokens?
English
@matteopaz06 if you think of tokens as a discretization of the cts world, it seems fine a la “the unreasonable effectiveness of numbers in the natural sciences?”
English

nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try.
A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here:
github.com/karpathy/nanoc…
Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning.
The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up.
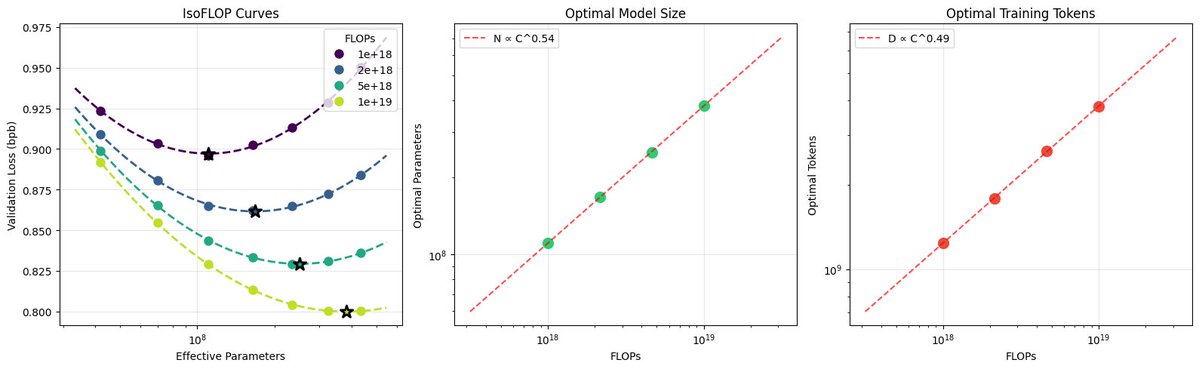
Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
English

@kanavtwt it gets better. when you use an integer in a for loop, it has to malloc/free the integer every iteration. all 28 bytes of it. the best optimization they could come up with is preallocating the integers -5 to 256. also bool inherits from int
English

@justinskycak thanks Justin! MA and Eurisko were amazing opportunities.
English

Can't think of a better way to close out 2025 than seeing the head of NASA ask my former student @matteopaz06 to apply, with a fighter jet ride as a signing bonus.
Matteo was one of my students in the Eurisko program, which, during its operation from 2020-23, was the most advanced high school math/CS sequence in the USA.
It culminated in high school students doing masters/PhD-level coursework (reproducing academic research papers in artificial intelligence, building everything from scratch in Python)
Matteo joined Eurisko as a 10th grader, during the last year it was offered, and worked hard to complete almost all 2-3 years’ worth of assignments in a single year. (Eurisko ended when I relocated; nobody else in the district had the requisite knowledge to teach it.)
This is exactly the position that we were trying to put students in with the Eurisko program – get them to a point of skill that they can capitalize on some math/coding-related opportunity and turn it into a chain reaction of fortunate events. And it’s been so great to witness some of these chain reactions get underway.
Eric Zeller@TheOnlyEZ
@curiosityonx @justinskycak update: @_MathAcademy gets you a tweet from the head of NASA and a ride in a fighter jet
English
@kevinweil thanks man. Come to project Launchpad demo day at OpenAI in January. Would love you to see what I've been working on since.
English

High school student uses AI to discover 1M+ objects humans missed in astronomical data. Head of NASA openly recruiting him through Twitter with a fighter jet ride included.
All my worlds colliding. I love everything about this.
Jared Isaacman@rookisaacman
@curiosityonx Matteo please apply to work at NASA and I will personally throw in a fighter jet ride as a signing bonus
English




@curiosityonx Matteo please apply to work at NASA and I will personally throw in a fighter jet ride as a signing bonus
English

🚨 A student in the US just discovered MILLIONS of new space objects.
The astronomy world was recently shaken by a discovery from an unexpected source: a teenager still in high school. Matteo Paz, a student from Pasadena, utilized archival data from NASA’s retired NEOWISE mission to bring 1.5 million invisible cosmic objects into the light.
During a stint at Caltech’s Planet Finder Academy, and mentored by astrophysicist Davy Kirkpatrick, Paz took a novel approach to data analysis. He built a unique machine learning model capable of sifting through a staggering 200 billion infrared records. In a span of only six weeks, his AI detected subtle patterns that human analysts had missed, identifying everything from distant quasars to exploding supernovas.
Paz’s findings were so robust that they earned him a spot in the prestigious The Astronomical Journal and a position as a research assistant at Caltech. His work does more than just populate star maps; it provides specific coordinates for the James Webb Space Telescope to investigate further. This breakthrough highlights a growing trend where fresh perspectives and AI tools allow young researchers to make historic scientific impacts from the classroom.

English