Sabitlenmiş Tweet
alex
1.1K posts


alex
@matthew_6
@ETHGlobal 4x winner | engineer @ perp dex
Singapore Katılım Mayıs 2011
1.6K Takip Edilen476 Takipçiler
alex retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
alex retweetledi

We're hosting a one-day hackathon around automated research!
* Thursday, April 9 (8 AM - 4 PM PT)
* SF and online
* Hosted by @paradigm
* Compete in never-before-seen optimization challenges, or build your own projects
* $9,000 in total prizes
Application in 🧵

English

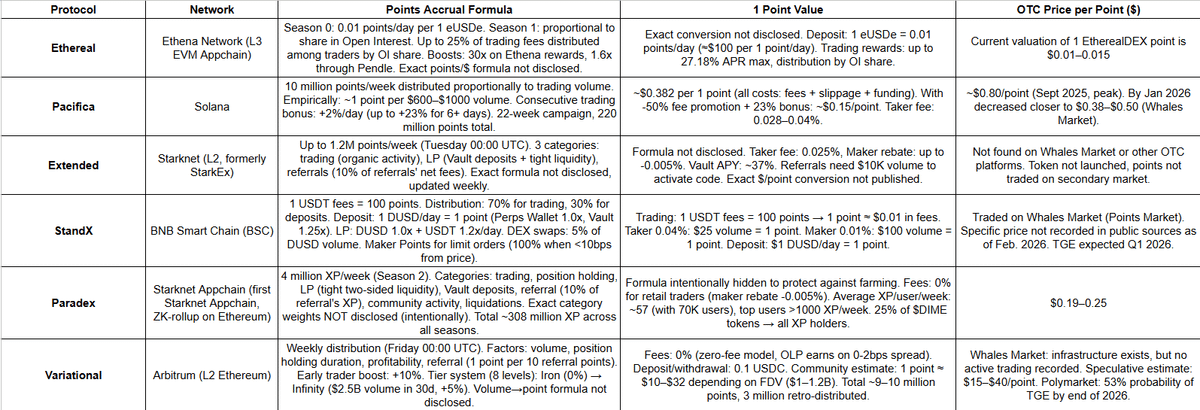
Perps Where Points Are Already Getting OTC Priced 👀
Spent time compiling the most interesting Perps protocols right now and all the key info around them:
- Points mechanics
- Farming meta
- Incentives
- OTC expectations
This is NOT hype it’s a structured overview of where real attention + future upside might be 👀
Covered Perps:
🔹 @etherealdex (Ethena L3)
– Points accrue daily via eUSDe deposits + trading
– OTC pricing already forming: ~$0.01–0.015 per point
🔹 @pacifica_fi (Solana)
– Massive weekly point emissions tied directly to volume
– OTC peaked ~$0.80/point, now closer to ~$0.38–0.50
🔹 @extendedapp (Starknet)
– Multiple categories: trading, LP, vaults, referrals
– Points not yet traded, token not launched
🔹 @StandX_Official (BSC)
– Clear conversion: fees → points
– Estimated cost in the range of $0.01–$0.10 per point
– TGE expected Q1 2026
🔹 @paradex
– XP system across trading, LP, vaults, referrals
– Average ~57 XP/user/week
– OTC estimates ~$0.19–0.25
🔹 @variational_io (Arbitrum)
– Weekly distributions based on real trader behavior
– Speculative OTC ~$15–40/point
Perps are becoming the main battleground for points, attention, and future token distributions.
Save this, rotate smart, and don’t farm blind 🧠
English

@JeongHaeju Use predictor.tools
Just enter your address and you are all set :))
English

How big is my $POLY airdrop gonna be
zoomer@zoomerfied
[ ZOOMER ] POLYMARKET FILES TRADEMARK FOR $POLY TOKEN: SYNOPTIC
English

Time to estimate your potential airdrop with tool I built here using open source Polymarket data
Just enter your address :)
predictor.tools

zoomer@zoomerfied
[ ZOOMER ] POLYMARKET FILES TRADEMARK FOR $POLY TOKEN: SYNOPTIC
English
@Brubbyy_ @PolymarketTrade yea i think i can add those fields
days active + number of trades would be good
English

@matthew_6 @PolymarketTrade ahhh ok was wondering if you took into account days active, pnl, # of trades, etc
it won’t let me dm u but that was pretty much it lol
English
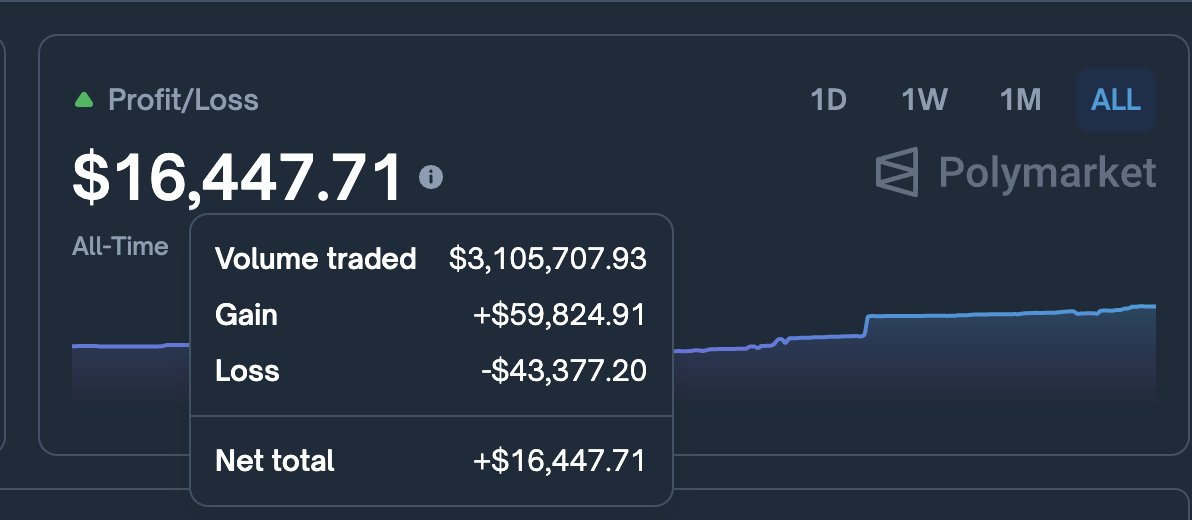
built a polymarket airdrop calculator using volume data! community estimate 📊
not official, just a fun tool to help predict potential airdrops this year 😆 @PolymarketTrade
try it out and share feedback: predictor.tools
psst we have cute cards to share too :)

English
@Brubbyy_ @PolymarketTrade feel free to ask, mostly using volume
just simple formula for getting all volume in polymarket, then comparing it with your user’s volume
estimating it with an fdv
English
@matthew_6 @PolymarketTrade yo would love to ask you some questions about the formula in dms
English
See which token survived the blood bath bear market
$HYPE
CoinGecko@coingecko
JUST IN: Crypto plunges to Extreme Fear at 9, the lowest reading since June 2022 after the Luna/UST collapse.
English

alex retweetledi


🚨BREAKING: Someone just solved Claude Code's biggest problem.
It's called Claude-Mem and it gives Claude persistent memory across sessions.
- You can use up to 95% fewer tokens each time.
- Make 20 times more tool calls before reaching limits.
100% Opensource.

English
