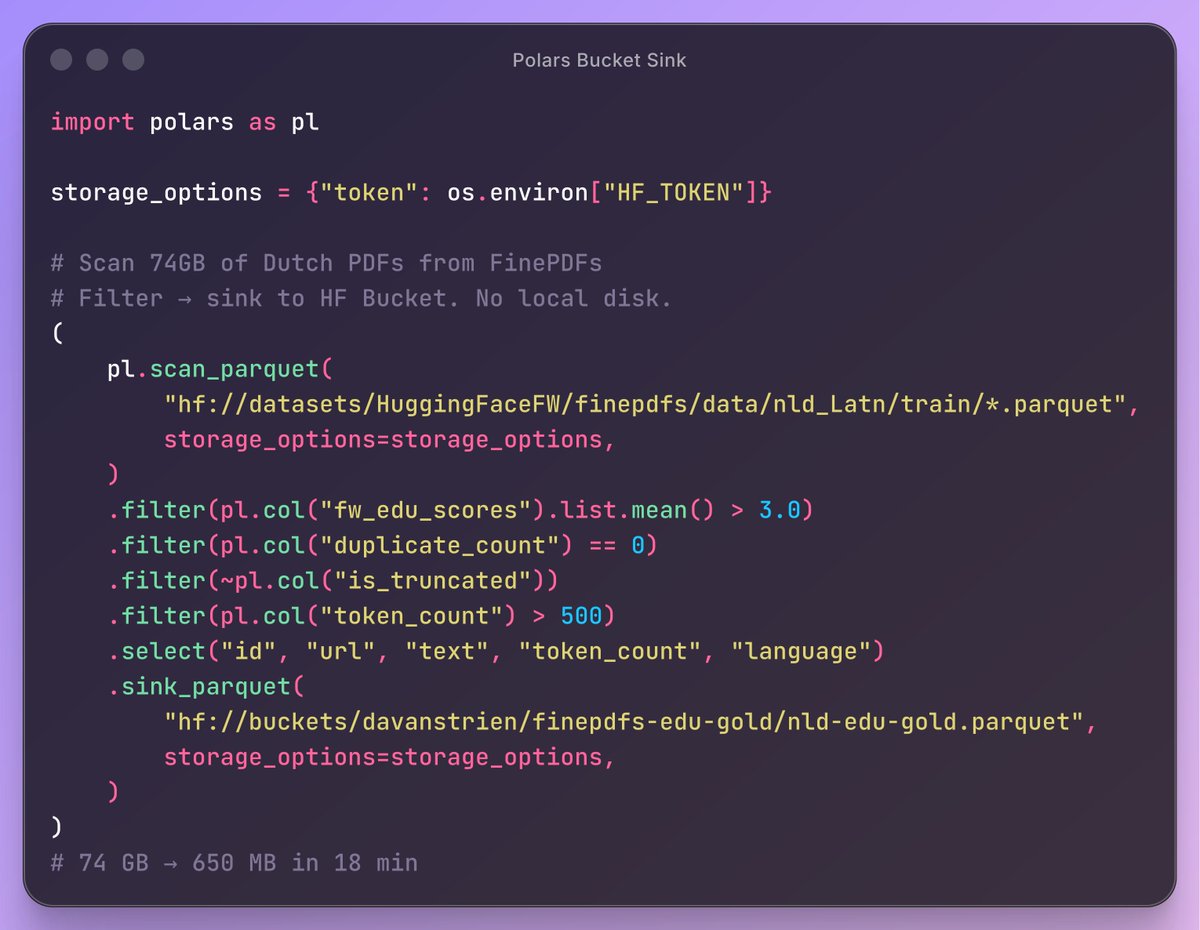
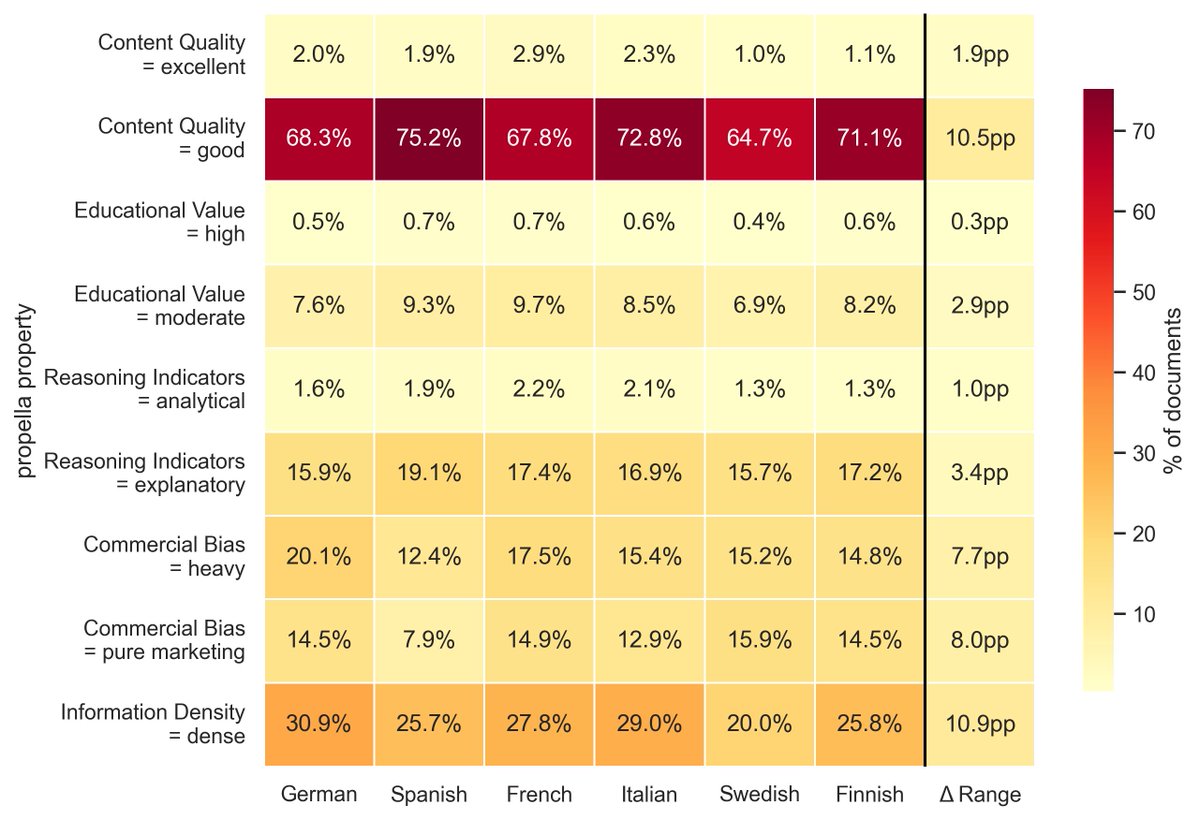
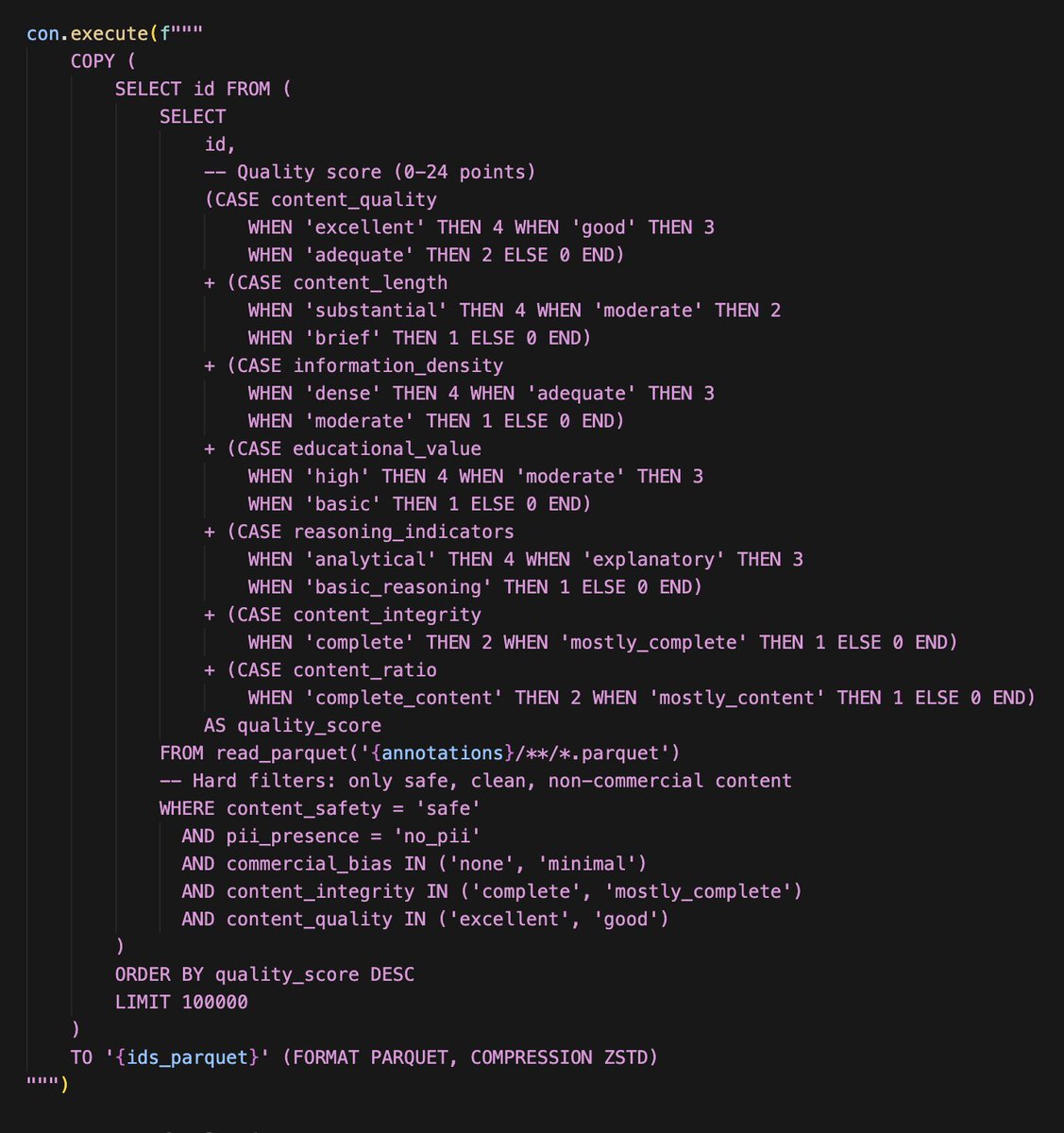
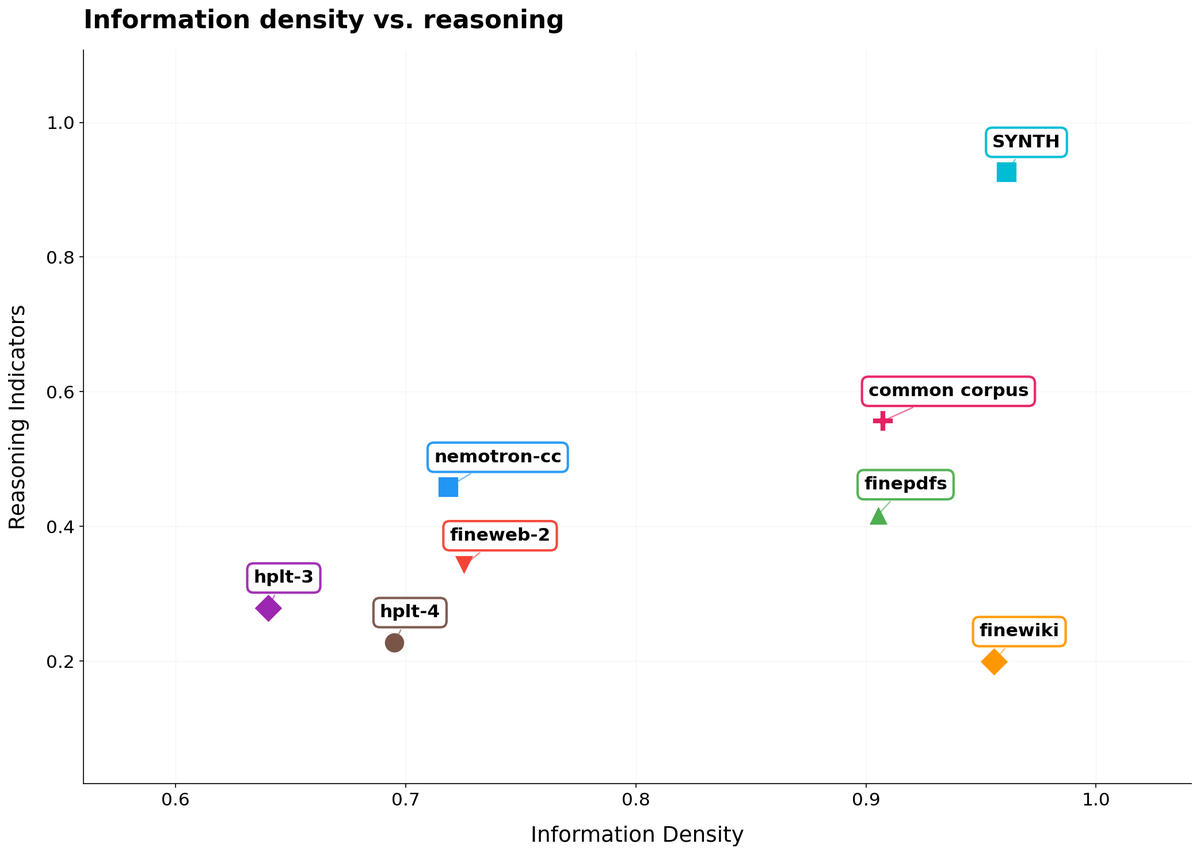
Actually we have started to use Propella internally to curate common corpus subcollections and run comparisons with other pretraining dataset. Really filling a missing piece of training/synthetic infra in Europe. huggingface.co/ellamind/prope…
Alexander Doria@Dorialexander
Great annotation work from @ellamindAI / OpenEuroLLM on French-Science-Commons less than 24 hours after release!
English