How do I subscribe to the AI x niche history jokes part of twitter
Delicious Tacos@Delicious_Tacos
“It’s my honor to announce that the true pope is working with us from Avignon”
English
Max Vishnevskii
537 posts
@maxvsnv
McKinsey | AI x Banking | Curious, fascinated by random things. Views my own
“It’s my honor to announce that the true pope is working with us from Avignon”

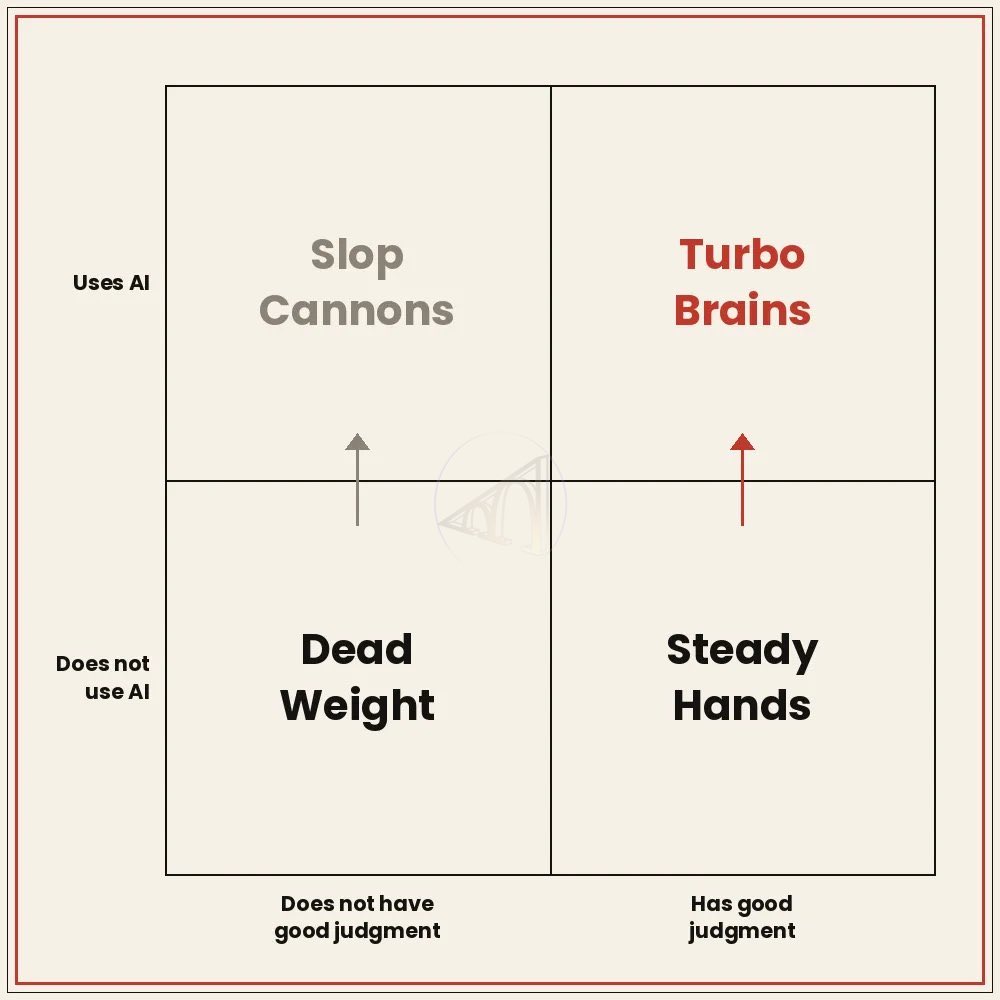

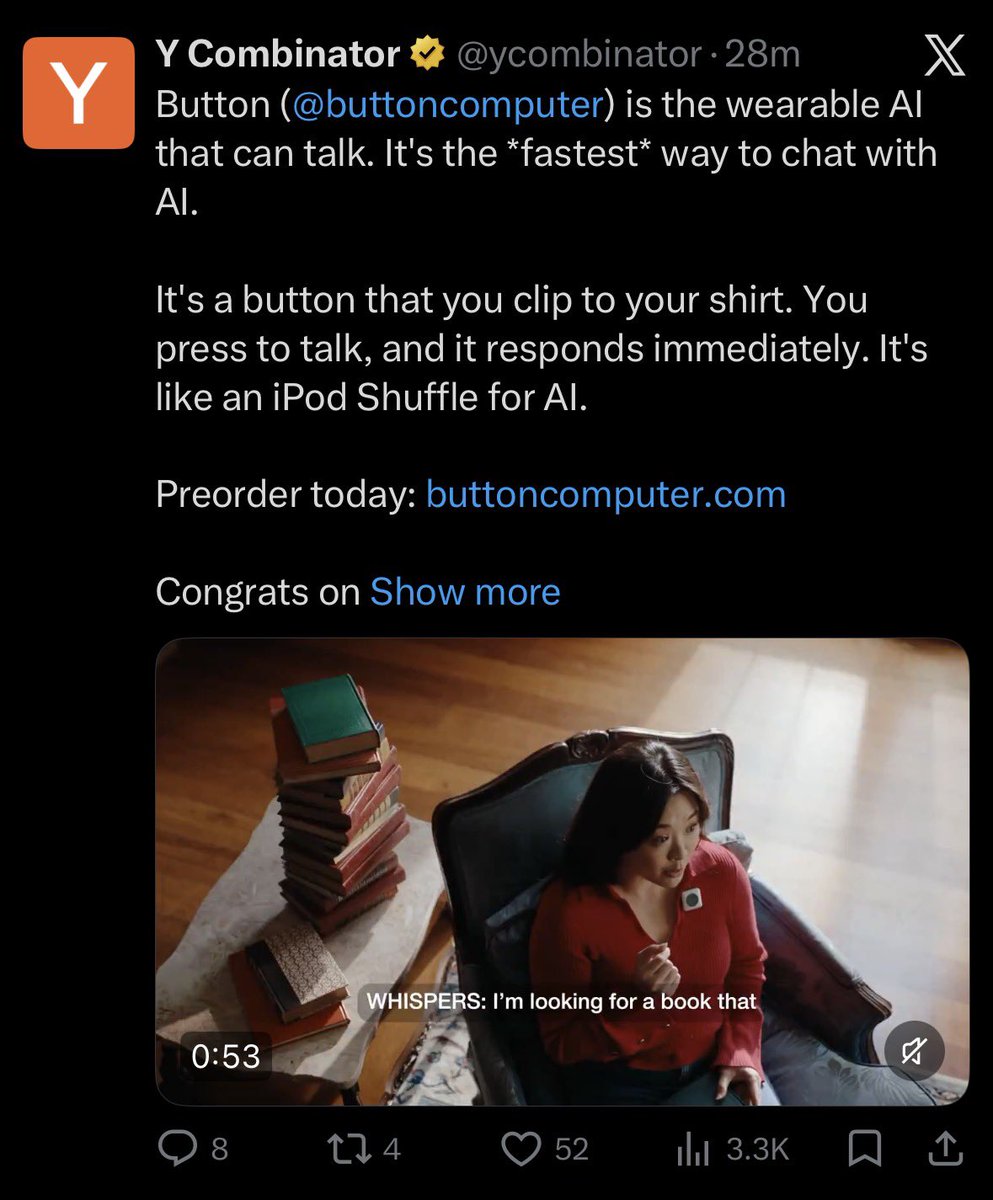
Everyone is obsessed with AI making a 10x engineer a 1000x engineer. The recent reductions at CloudFlare and Click have me me realize the plot is equally about the inverse: AI amplifies the *negative* impacts of poor performers. If a person with poor taste, who makes mediocore judgement calls, and doesn't properly build things customers love is able to produce 10x more work - does a company want that? Hell no! Productivity isn't just about as many people as possible tokenmaxxing. AI is a double edged sword, especially when it's used to produce net new work. If you give a bad artist a pen that can draw 100x as fast, you're going to pile up with a lot of junky artwork very quickly. And since it happens so quickly leaders are now able to see quickly who is Picasso and who is not and adjust accordingly.
We're excited to partner with Google to offer Grounding With Exa inside of Gemini models! Using Exa's agent-first search, Gemini models can now access billions of websites, technical docs, papers, people, companies, and more. 10^18🤝10^100

my god. anthropic casually going after bloomberg terminal and every single data tracking provider under the sun 😂 bloomberg terminal charges $24K per seat this could affect major data platforms like DataDog, Google analytics, CRM dashboards and sooo much more Anthropic is building the control center for every single enterprise company unbelievable
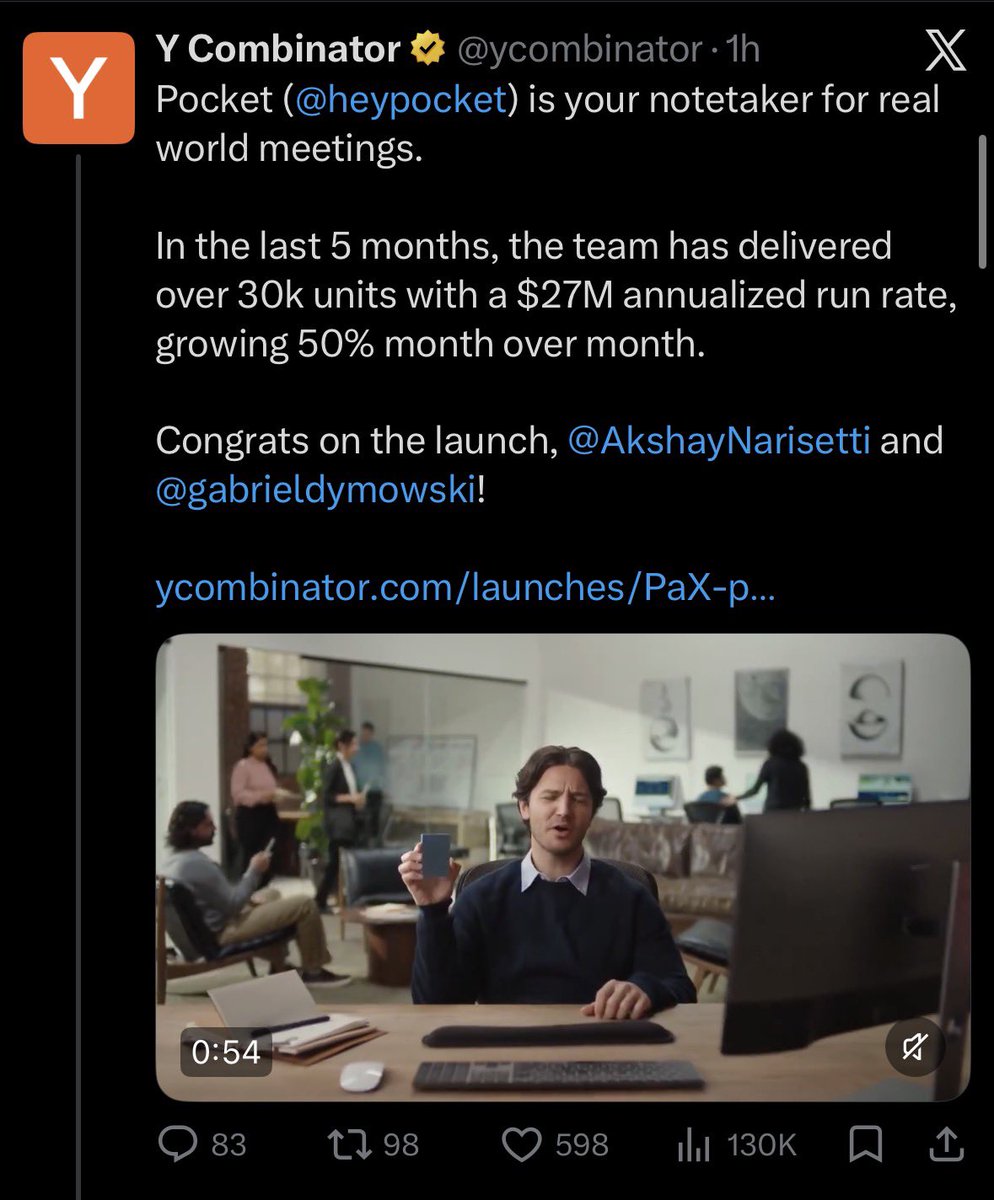
We just added /btw to Claude Code! Use it to have side chain conversations while Claude is working.

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)

If you ask AI to rewrite the entirety of an open-source program, do you still need to abide by the original license? In philosophy, this problem is known as the Slop of Theseus


BREAKING: South Korea's share market now down 12%


⚡ Excited to announce Gemini 3.1 Flash-Lite! We’ve set a new standard for efficiency and capability to give developers our fastest, most cost-effective Gemini 3 model yet. We engineered this model with thinking levels, allowing it to handle high-volume queries instantly, while scaling up its reasoning for complex edge cases. By the numbers: ⏱️ 2.5X faster time-to-first-token than 2.5 Flash while being significantly higher quality 📉 $0.25 per 1M input tokens 📊 1432 Elo on LMArena & 86.9% on GPQA Diamond Thrilled to see what developers build with this kind of speed and quality at scale. Available now in Google AI Studio and Vertex AI. blog.google/innovation-and…