Taylor Pearson@TaylorPearsonMe
I spent some time going through Garry Tan's GBrain. I want to pull out what I see as the general form factors and what's interesting there as someone who is non-technical and doesn't work in VC.
I think a lot of people are converging on the same set of 5 core form factors and they represent something of the natural next progression of how to use agentic AI tools like Codex/Claude Code/Hermes/OpenClaw/etc.
x.com/garrytan/statu…
1. Skills. This is the most natural starting point for pretty much everyone. People build these without being told to because they're a familiar shape. I thought of them like an SOP, a documented procedure for doing something. The user supplies what, the skill supplies the how.
Tan's framing is that a skill works like a method call. In programming, a method call is the syntax for invoking a procedure with arguments. The same code runs every time. The arguments are what vary: what data, what question, what target. The same process_invoice function handles every invoice in the system, not just the one it was first written for.
A skill is the same shape. The seven steps of a skill called "/investigate" don't change. The parameters do: a TARGET (who or what to investigate), a QUESTION (what you're trying to figure out), a DATASET (where to look). Point it at a medical whistleblower case and you get a research analyst. Point it at SEC filings and you get a forensic investigator. Same file, same seven steps, the world supplies the difference.
This is a different form factor from a traditional SOP. Most SOPs are written for a specific job: "Process Accounts Payable." One procedure per use case. A skill is written abstractly enough that the same procedure handles a family of cases. One well-built skill can do the work of dozens of SOPs because the case-specific detail moves out of the document and into the parameters. Depending on how you are using them, some skills are closer to SOPs, others to method calls.
2. Thin harness. The model (Opus, GPT-5.5, etc.) is the raw intelligence. The harness (Claude Code, Codex CLI, Hermes, OpenClaw) is what gives the model hands. They loop, read and write files, manage context, enforce safety. About 200 lines of code at the core.
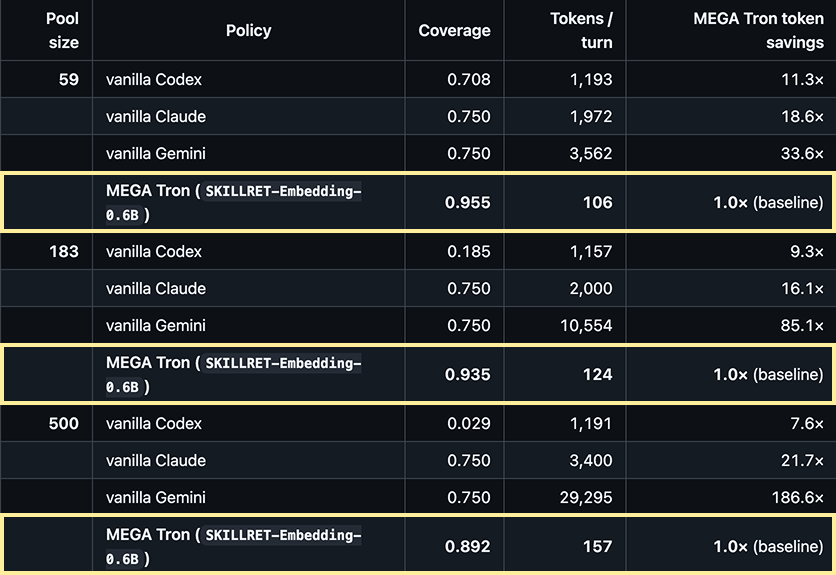
Garry notes the mistake most people make (he and I included) is to keep loading more stuff into the harness itself. I ended up with 100 tool definitions and a bunch of MCP servers. The result is that context window fills up with descriptions of tools the model doesn't need for the current task. The model gets confused about which to use. Latency goes up, accuracy goes down. Context rot.
3. Resolvers. The solution to context rot is a routing table. A resolver maps "task type X just came in" to "fire skill Y." When you have five skills, you don't need one. When you have a hundred, the descriptions blur together and the model fails to invoke the skill at the right time. The resolver replaces ambient pattern-matching with explicit rules.
Tan also runs something like a resolver for files: a separate routing table that decides where the output of a skill should land in the filesystem. Same audit-and-route shape applied to a different problem. The output ends up in the right folder reliably rather than wherever the model guesses.
Skillify is his companion idea: a quality loop that turns one-off skills into permanent infrastructure. The 10-step version Tan describes includes a contract, deterministic code where code can do the job, unit tests, integration tests, LLM-as-judge evals, resolver entry, an audit script that flags skills with no path to invocation, and an end-to-end smoke test. The test is simple. If you have to ask the model the same thing twice, you failed.
4. Latent vs. deterministic. Be thoughtful about which work lives where. The LLM is excellent at judgment, synthesis, pattern recognition, reading between the lines. It is bad at arithmetic, combinatorial optimization, anything that needs the same answer every time. LLMs are fundamentally probabilistic and shouldn't be used when a deterministic solution will do.
Most non-technical people under-use the deterministic side. The default instinct is to throw everything at the model. If you can do something deterministically, you almost certainly should. And you don't need to be a programmer to do it. The model can write the code for you. The discipline is to ask, every time, whether code could handle this reliably for free, and to actually have the model write that code when the answer is yes.
5. Memory. The system needs some form of memory to be useful. I'm not sure what the right form is, and a lot of people are building it different ways: vector embeddings with semantic similarity, knowledge graphs, hybrid stores. Tan's approach is the same as mine: just a folder of markdown files.
He has one page per person, one page per company, one page per concept. Each page has compiled truth on top (the current best understanding, rewritten as new evidence arrives) and an append-only timeline below.
A few things follow from the markdown choice. The file is the system of record, not an export. You can open it in VS Code, edit it by hand, and the agent picks up the changes. Typed relationships (works_at, invested_in, founded, attended, advises) get extracted via regex on every write, so the knowledge graph wires itself without spending tokens. This particular schema makes sense for his job, but should probably be customized depending on what you do.
A signal detector runs in the background. Mention someone once and they get a stub page; three mentions across sources and web enrichment fires; after a meeting, the full pipeline runs. An overnight dream cycle scans conversations, enriches stale entities, and fixes broken citations. The base is text. Everything on top is cheap and composable.
There is more under the hood, but I think those are the broad strokes which I feel are more or less universally useful approaches.
I had maybe half of this architecture already. I hadn't hit the scale where a real resolver was necessary, but I'm there now and just did a little refactor to make my setup model agnostic and with a built-in resolver. The signal detector and overnight dream cycle running automatic enrichment in the background is the main piece I haven't built yet and want to try and add.
I suspect that the convergence across people building these is a signal that the form is generally (though probably not universally) useful.
Even though implementation details vary in ways that matter, the general form seems to be coming up for many people.
The question I have been asking is: how do you use AI to build sustainable competitive advantage?
Everyone is excited about vibe-coded apps and one-shot prompts (which is 100% super cool). This is how I started playing with things and it got me hooked, but the equilibrium price of anything you can build with a one-shot prompt is the token cost to build it (which is a few cents).
Like the person who copied My Fitness Pal and made a million dollars selling it for half the cost is awesome. But, someone else is just going to copy that and sell it for half again and the cycle keeps going until there's no margin there.
What's actually durable is some form of process power implicit in the architecture above in Hamilton Helmer's 7 Powers sense.
7 Powers names the seven structural conditions that let a business sustain above-market margins over time. Anything not rooted in one of those powers gets competed away.
Five of Helmer's seven powers are essentially closed doors for SMBs and early-stage companies. Scale economies require scale. Network economies and Switching costs can be developed but require building a big base. Cornered resources usually mean patents or similar that are not typical to companies. Branding usually takes a decade and you can't shortcut it.
The two remaining ones are counter-positioning and process power.
Counter-positioning (a model an incumbent can't mimic without cannibalizing their existing business) is sometimes available but not always.
That leaves process power. And a well-built AI system is exactly the kind of artifact that generates it.
It's the same kind of work as building really good SOPs or proprietary software. The procedures are codified, the cases are parameterized, the deterministic layer underneath is fast and reliable, and the memory layer carries forward what you've learned. It enables something like productized services on steroids: You can perform a service or supply a product at lower cost or higher quality because the work is structured.
Imagine an accountant who builds this out. Memory layer: one folder with markdown files per client with compiled truth (entity structure, year-over-year tax positions, ongoing audits) and a timeline (meetings, decisions, what changed).
There are some skills like /year-end-review, /quarterly-estimate, /audit-prep, same procedure parameterized for each client.
There is a deterministic layer: tax tables, depreciation schedules, IRS publications, client tax return histories, etc.
Then some form of diarization or dream cycle. E.g. overnight, the system flags a partner whose K-1 distribution dropped 40% without a strategy change, or notices that one client's home-office deduction structure is portable to another client (the structure travels, identities stay where they belong).
She charges a small premium, handles more clients per year, and her competitors can't replicate it because the structure didn't exist when she started building it.
The artifact itself is a folder of markdown files, but the lines in each file are downstream of lots of thoughtful testing and building to make process power.