Harshal Dharpure retweetledi

📢 Kimi AI just released a paper showing you can match the performance of a model trained with 1.25x more compute by changing one thing: how residual connections work.
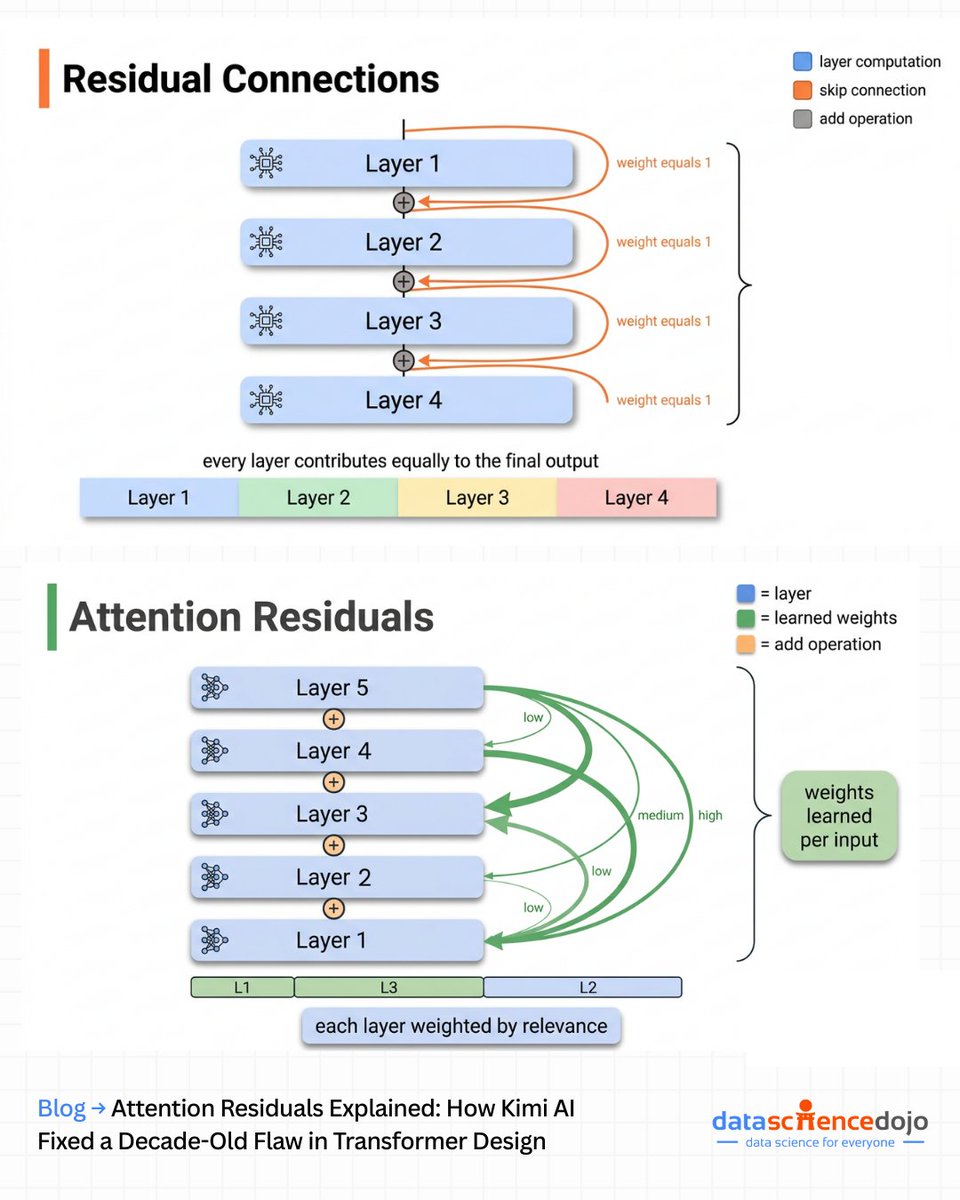
The core problem is something that has been sitting inside every transformer since 2015. When layer outputs accumulate through a network, every layer gets the same fixed weight of 1. By layer 50, earlier layers are contributing so little to the final result that research has shown you can remove a significant fraction of them entirely with barely any performance drop. The model had already learned to ignore them.
Attention residuals replace that fixed accumulation with a learned weighted sum over all previous layer outputs. Each layer computes a small search query, scores every earlier layer's output for relevance, and builds its input from the most useful ones. The weights adapt per input rather than staying fixed, which is what makes the difference.
Tested on a 48B parameter model trained on 1.4T tokens, the gains hold across every benchmark. GPQA-Diamond up 7.5 points. Math up 3.6. HumanEval up 3.1. The largest improvements are on multi-step reasoning tasks, which makes sense — those are exactly the tasks where later layers need to selectively build on what earlier layers figured out.
Full breakdown in the blog. Link in the replies!
#AttentionResiduals #KimiAI #LLM #DeepLearning #AIResearch #GenerativeAI #DataScience
English