MiBakh retweetledi

Schrödinger's SaaS
A newly launched and meticulously built B2B SaaS product at $0 MRR. The SaaS exists in a superposition, simultaneously alive and dead.
English
MiBakh
1.1K posts





Some more napkin math - size of the Internet is ~10^11 pages of text*, this would cost (only?) $50M to embed. Who wants to take on Google?










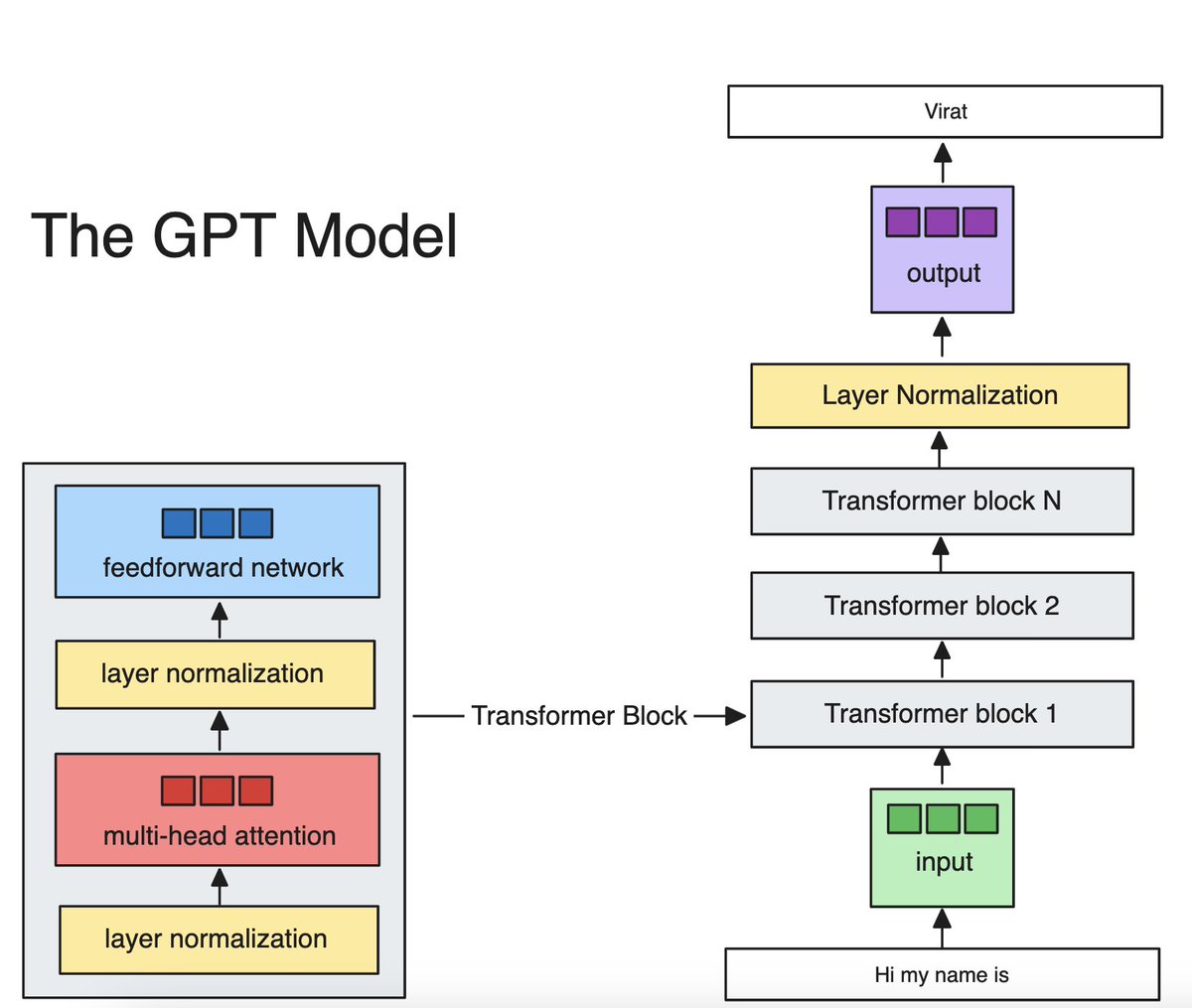







OpenAI CEO Sam Altman on the key to having a world where we have reasoning agents interfacing with the world -- a shared interface:



