Sabitlenmiş Tweet

Human feedback is so critical for evaluating subjective AI systems -- and yet so costly to collect.
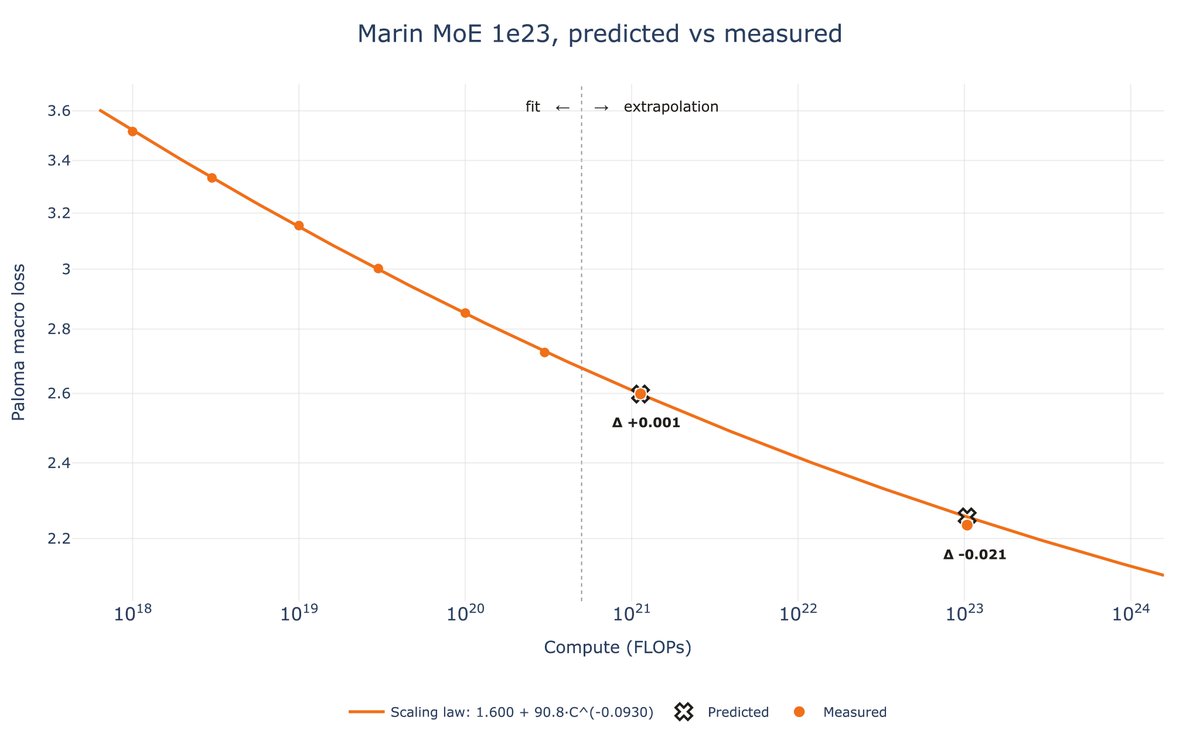
Come talk to me about AutoMetrics at #ICLR2026 🇧🇷! With <100 feedback points we generate automatic evaluation metrics for your task that beat hand crafted LLM-as-a-Judge rubrics by up to +33.4% improvement in correlation to human judgements!

English