Excited to help the @womeninaisf club host a Claude Code event w/ the team at @AnthropicAI next week.
We're looking for volunteers to DEMO their projects - if this is one of you, please sign up at the link in the comments.
Link to register to attend - also in the next tweet!
The craft of your product is the respect for your customers.
We do not release 30% of shows we record.
Every single show, 10 years in, with large media teams, I still listen to every single one pre-release.
We remove 35-45% of shows to optimise word to value ratio.
Details are not details, they are the product.
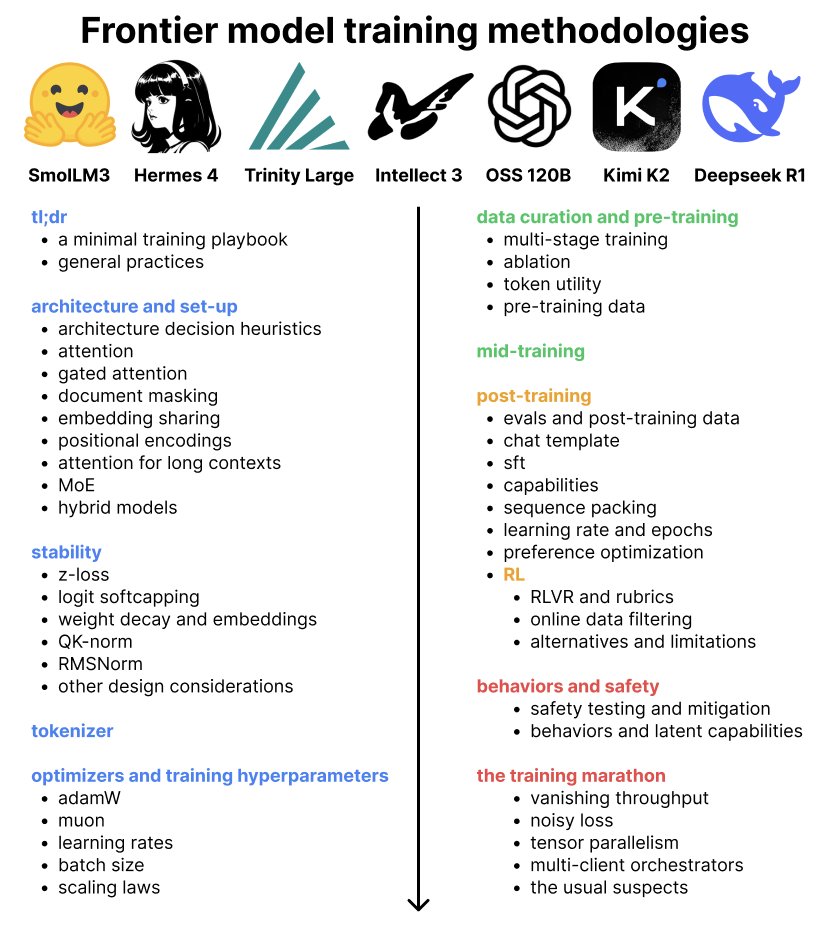
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
djdumpling.github.io/2026/01/31/fro…
@micpsst the reasoning cots are not really just about information retreival, so I'm not sure I agree. What are you doing with RAG that solves olympiad math problems aside from rag'ing the answers?
Reasoning in LLMs has actually broken at least one intuition about data that I thought I was confident in.
Prior to reasoning models, there was a lot I could predict based on the data that went in, such as things like average output lengths and limits on how many tokens they'd generate. It used to be if you trained on outputs of 4k max, you'd have a near-0% chance to generate 10k+ tokens.
But with reasoning models, they actually learn a function through this data that can make it generate way way way beyond what length of output tokens you trained on. I think this justifies calling it "reasoning", because it actually learned a function similar to reasoning, by generating tokens that look like thinking to improve accuracy until it is confident in it having found the correct answer, and even if you train on 10k cot tokens max, models will still think, potentially through the entire 128k+ context length it has.
Something else interesting about "reasoning" is that we observed when scaling Hermes 4 from 14b, to 70b, to 405B, that the thinking lengths went down and down for the same set of problems as the model got bigger. This also implies that the reasoning process is very much tied to innate intelligence, because the problem is, relative to each model, a different difficulty, and it literally *thinks longer* if it is less intelligent!
Just some fun facts for you on this Sunday :)
True, but doable with GraphRAG-ish solutions. It also feels more stable than relying on reasoning at inference. Most of the time, when reasoning activates, the model just repeats or paraphrases what's already in the prefilled context, which is generally super low info. You can just duplicate the context and often get the same outcome. There's a recent Google paper on this, though they didn't benchmark against reasoning models
arxiv.org/pdf/2512.14982
I'm open-sourcing jax-js — a machine learning library for the web, in pure JavaScript
jax-js is the first ML compiler that runs in the browser, generating fast WebGPU kernels. Built from scratch over the past year as a personal side project
Details: ekzhang.substack.com/p/jax-js-an-ml…
not sure if it's just me, but chatgpt used to update the conversation's title as its content evolves, and now the title's just fixed on whatever you ask first.