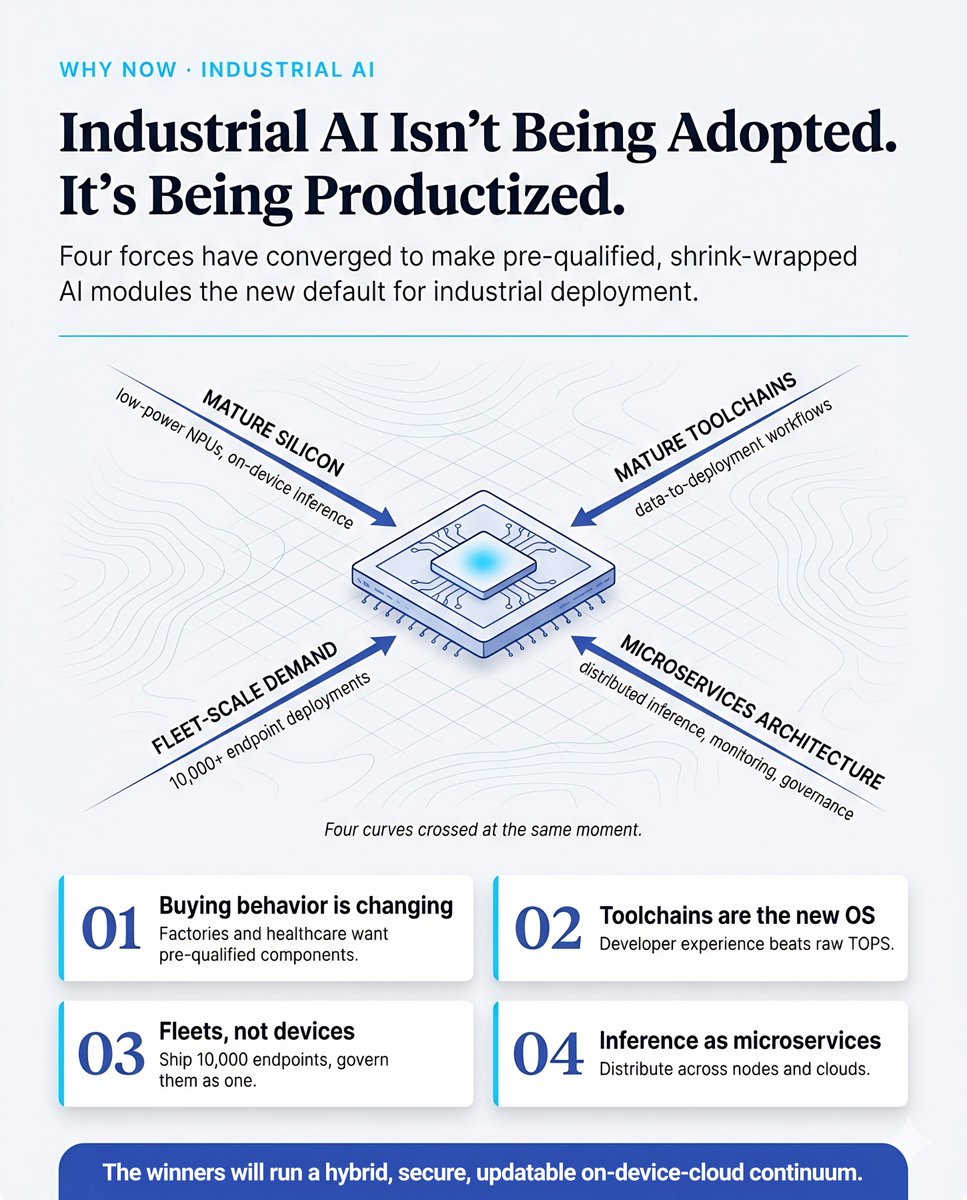
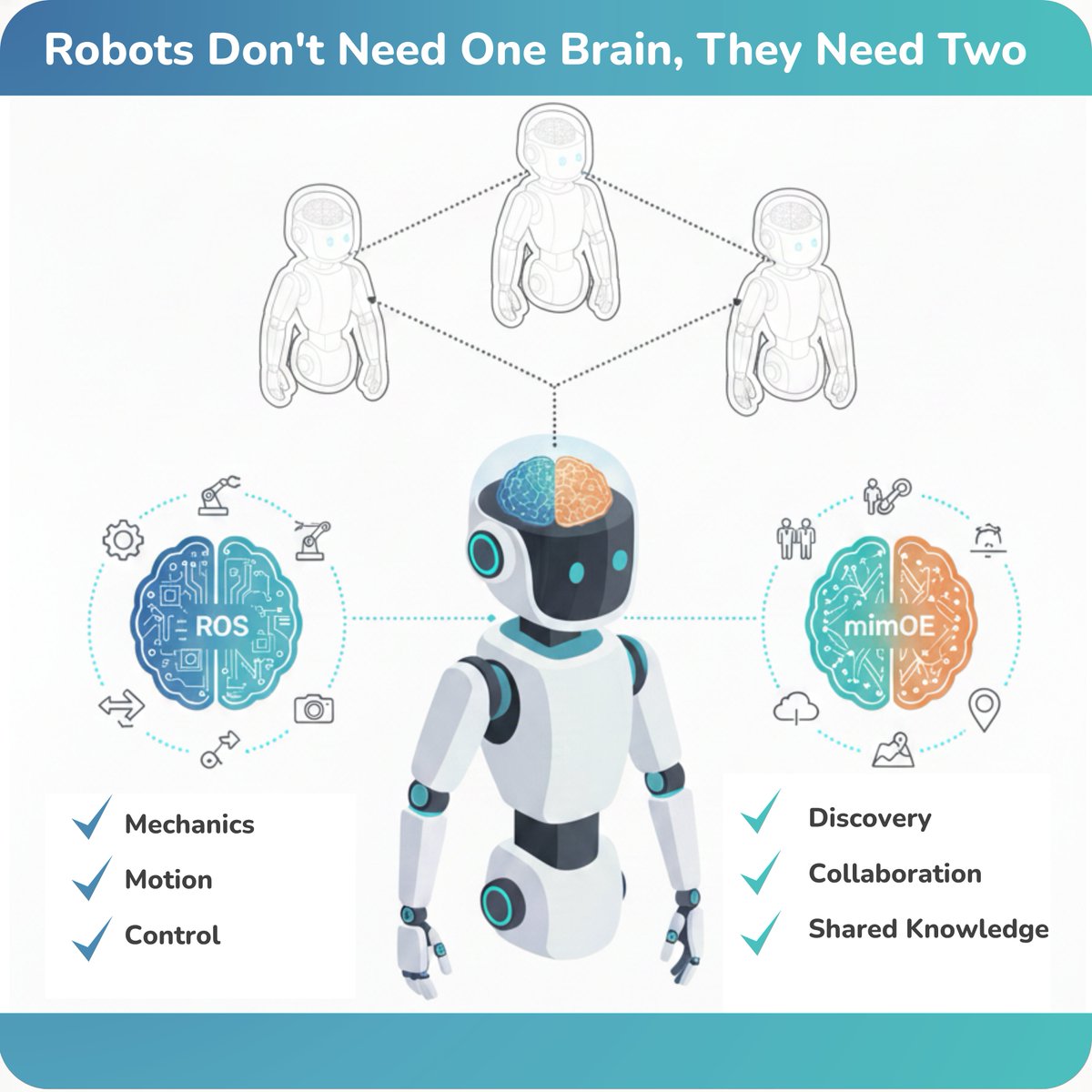
Who we want to meet at AMD Advancing AI, July 22 and 23:
Embedded and SoC engineers building on Ryzen Embedded and EPYC Embedded who want a runtime that deploys agents out of the box.
OEM product leaders deciding what ships on next year’s devices, who need the agent layer to be small, secure, and OS agnostic.
Robotics and Physical AI teams stuck between a working pilot and a production fleet.
Systems integrators designing agentic architectures for enterprises that insist on sovereignty in execution: control over where agents execute, decide, and act.
Analysts covering the agent runtime layer, because this category is moving fast and we would rather show than tell.
If any of that is you, comment or DM us. Coffee slots are open both days.
Learn more: mimik.com/our-events/mim…
#AMDAdvancingAI #AgenticAI #Embedded #Robotics
@Fayarjomandi @siavashalamouti @SamArmani

English