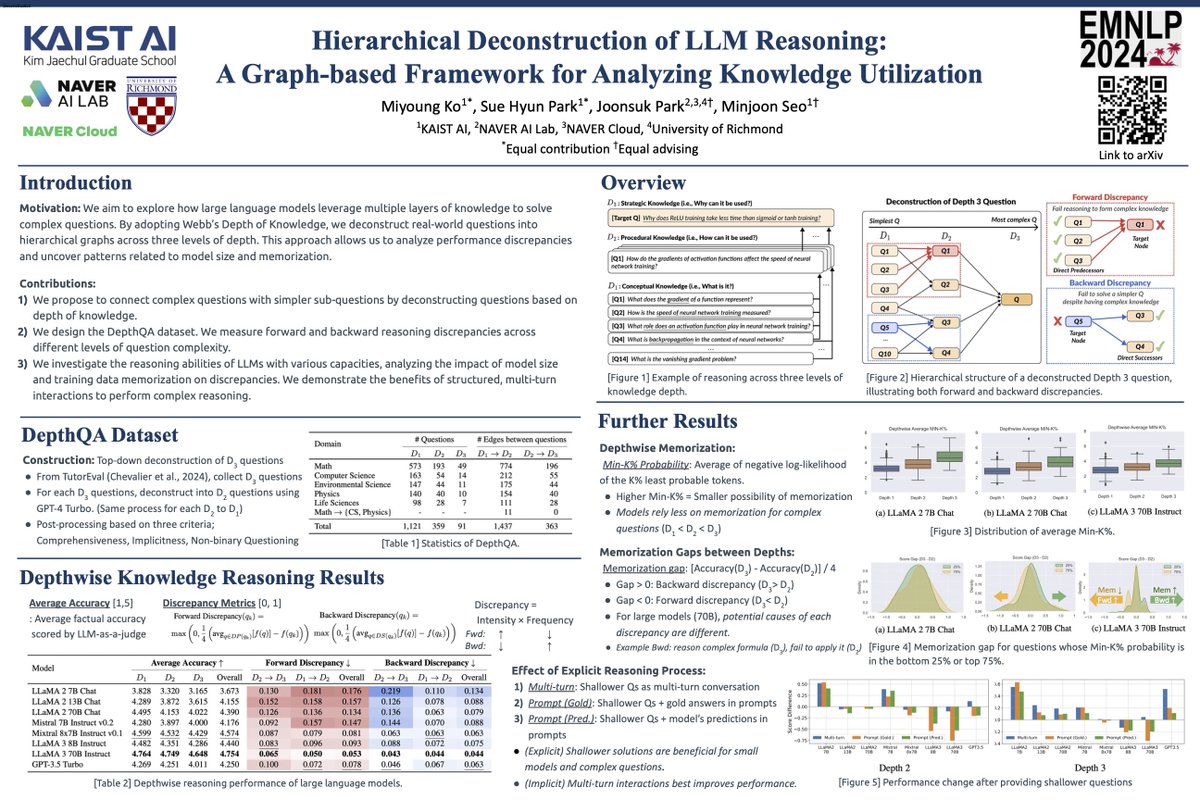
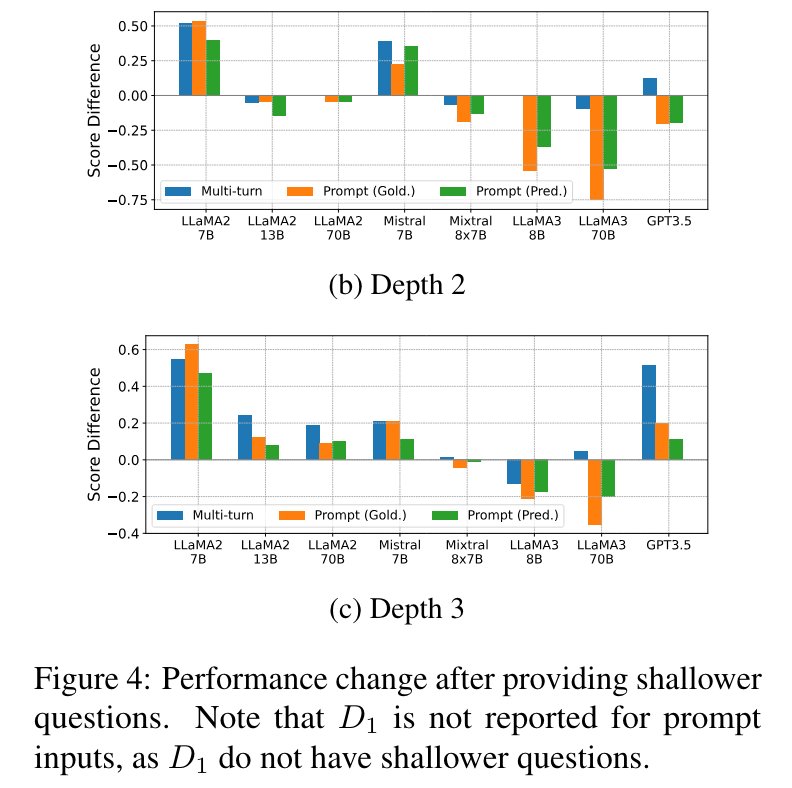
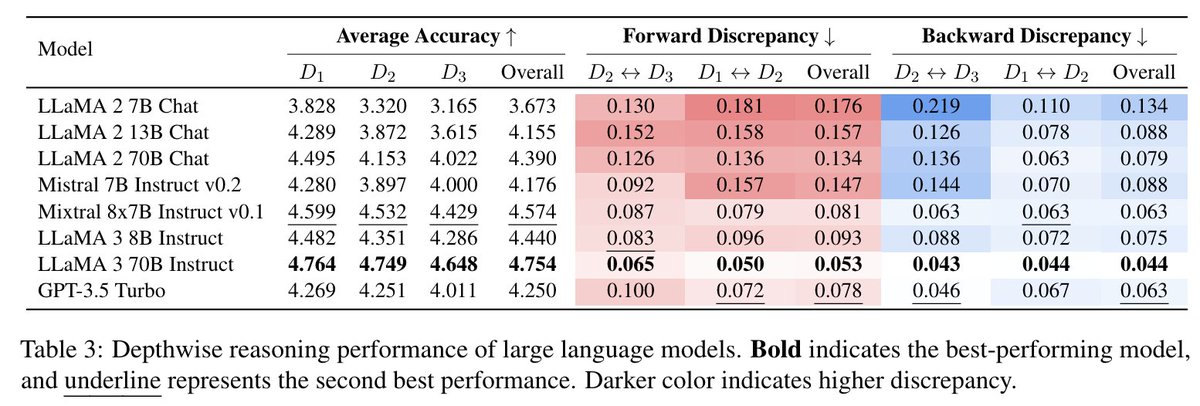
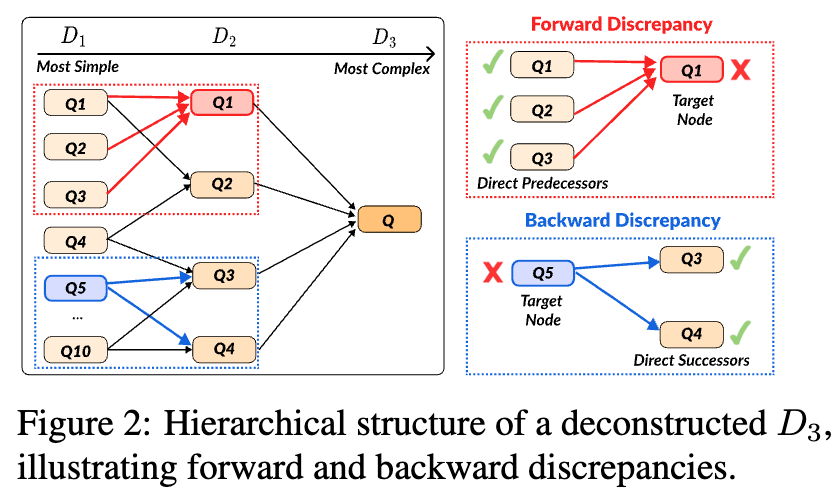
MiyoungKo retweetledi

1/ Pattern matching has been left ambiguous for so long.
Our precise formalization pinpoints its predictive power on composition tasks!
📣 Check out our ICLR 2026 paper:
1️⃣ Sharp sample complexity bound for 2-hop task;
2️⃣ Some unexpectedly hard composition tasks: CoT won’t help.

English