Noah Lee retweetledi

⁉️Why do reward models suffer from over-optimization in RLHF?
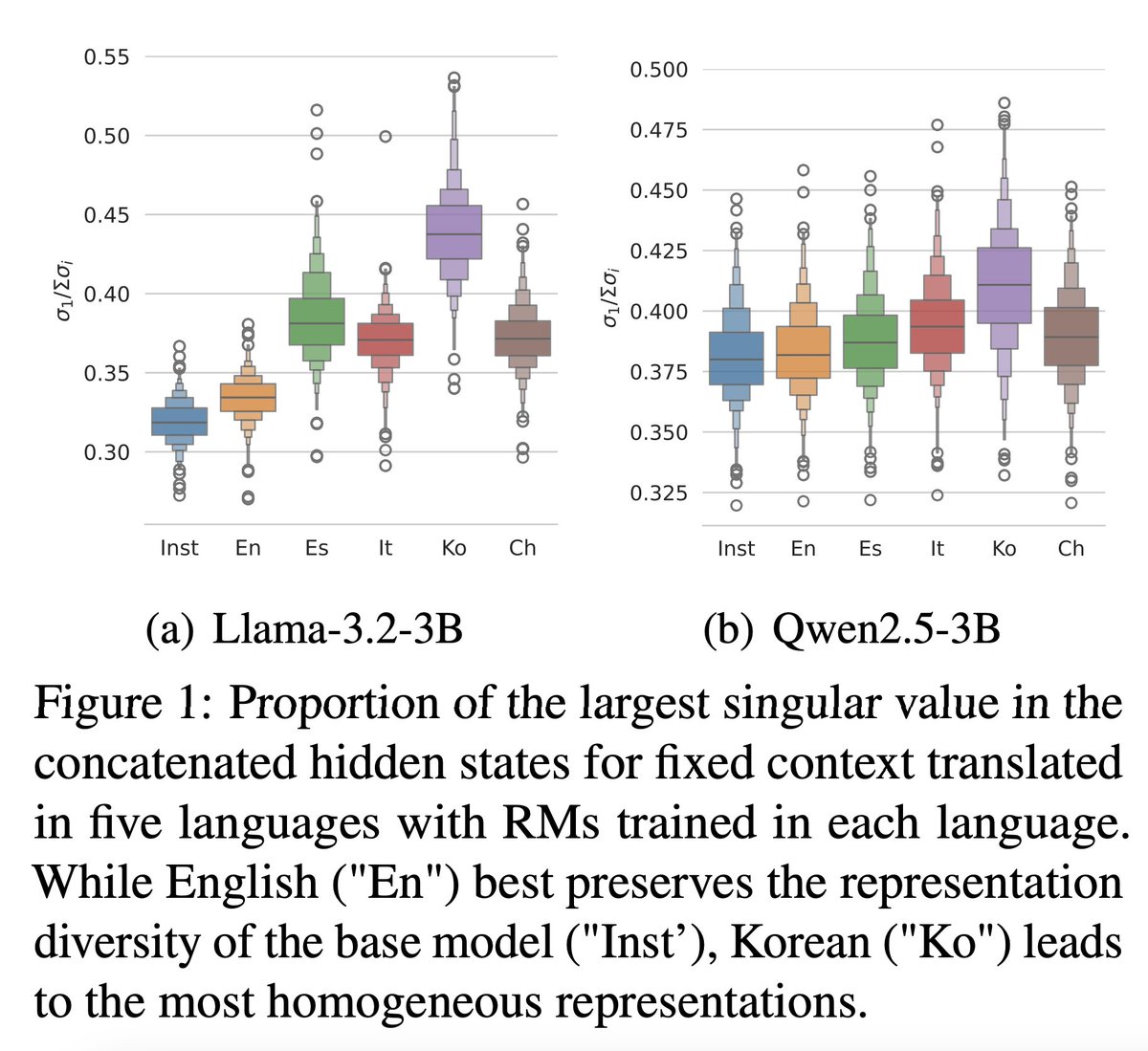
We revisit how representations are learned during reward modeling, revealing “hidden state dispersion” as the key, with a simple fix!
🧵
Meet us at @icmlconf!
📅July 16th (Wed) 11AM–1:30PM
📍East Hall A-B E-2608

English