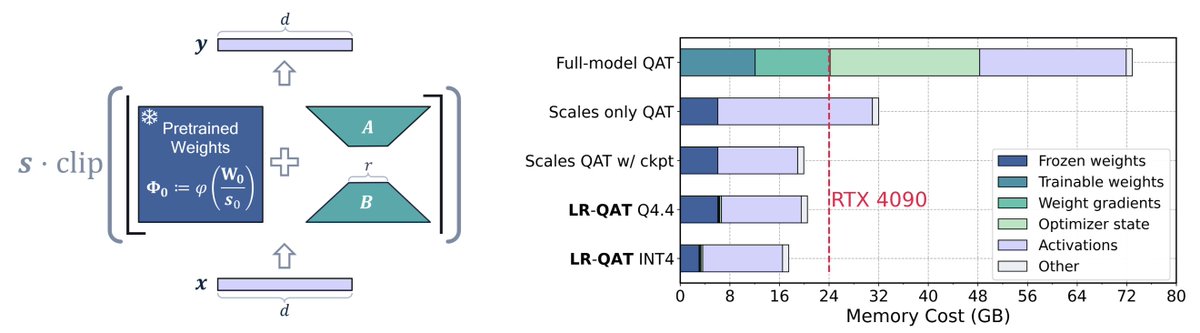
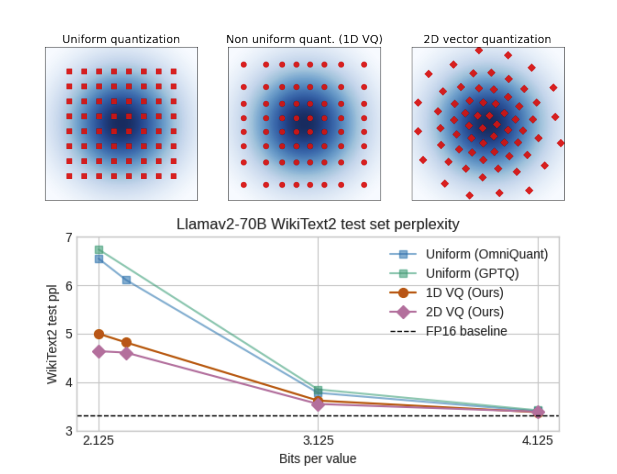
I am excited to host and present at our #CVPR2025 tutorial on Power-efficient Neural Networks Using Low-precision Data Types and Quantization. This is together with @TiRune (Meta) and Thomas Pfeil (Recogni).
📅 Thursday Jun 12, 13:00
🏠 CVPR, room 205B
ℹ️ power-efficient-nn.github.io
English