Muyu He@HeMuyu0327
We are interested in whether Kimi's Attention Residual has the same "attention sink" problem of attention layers. To figure out the answer, we design two novel architectures on top of Attn Res on nanochat.
- The problem: since attention is computed with softmax, attention scores always sum to 1. So the model is forced to assign on average non-trivial weight to each individual component. In attention, the model solves this by absorbing most attention into the key of the first token, ie. "attention sink".
Since Attn Res also uses softmax, we want to know if it suffers from the same issue, and needs a "sink" to absorb extra attention. In Attn Res, the token embedding output also receives substantial attention from every subsequent layer. Is this behaving like a sink, or is it genuinely useful?
- The architectural change:
For the first model, we add a learnable scalar to each layer of the Attn Res model, following the learnable sink design of GPT-OSS. During attention residual computation, this sink scalar is concatenated with other logits before softmax, essentially absorbing some attention.
For the second model, we add a gate at the output of the attention residual, which scales each dimension by (0, 1), following the gate design of Qwen's gated attention. This essentially undos any overmixing softmax attention might have for each hidden dim.
- The effect: both models seem to show that there is no attention sink problem brought about by softmax attention for Attn Res.
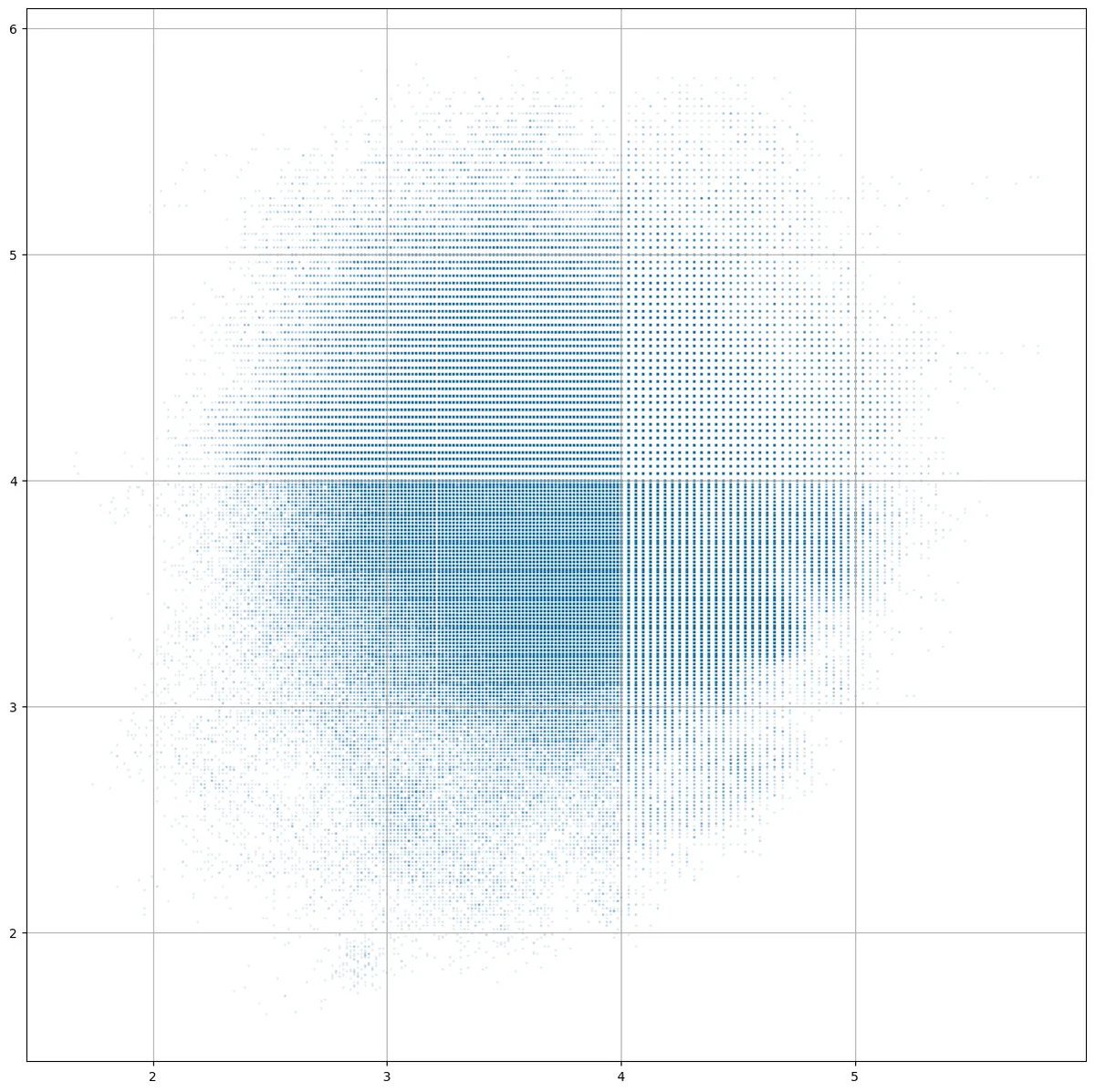
For the learnable sink model, we plot the attention of each layer to previous outputs, with first column being attention to the sink (p1). We find that most attention is still on the embedding output, even though there is a sink for extra attention. This shows that the model does focus on the embedding output for specific gains.
Looking at the values of the learnable sink, which is zero-initialized, we find that most layers drive the value to negative, essentially reducing its effect on attention even more (p2). This is a clear signal that the model wants to allocate the existing attention budget as much as possible on real layer outputs.
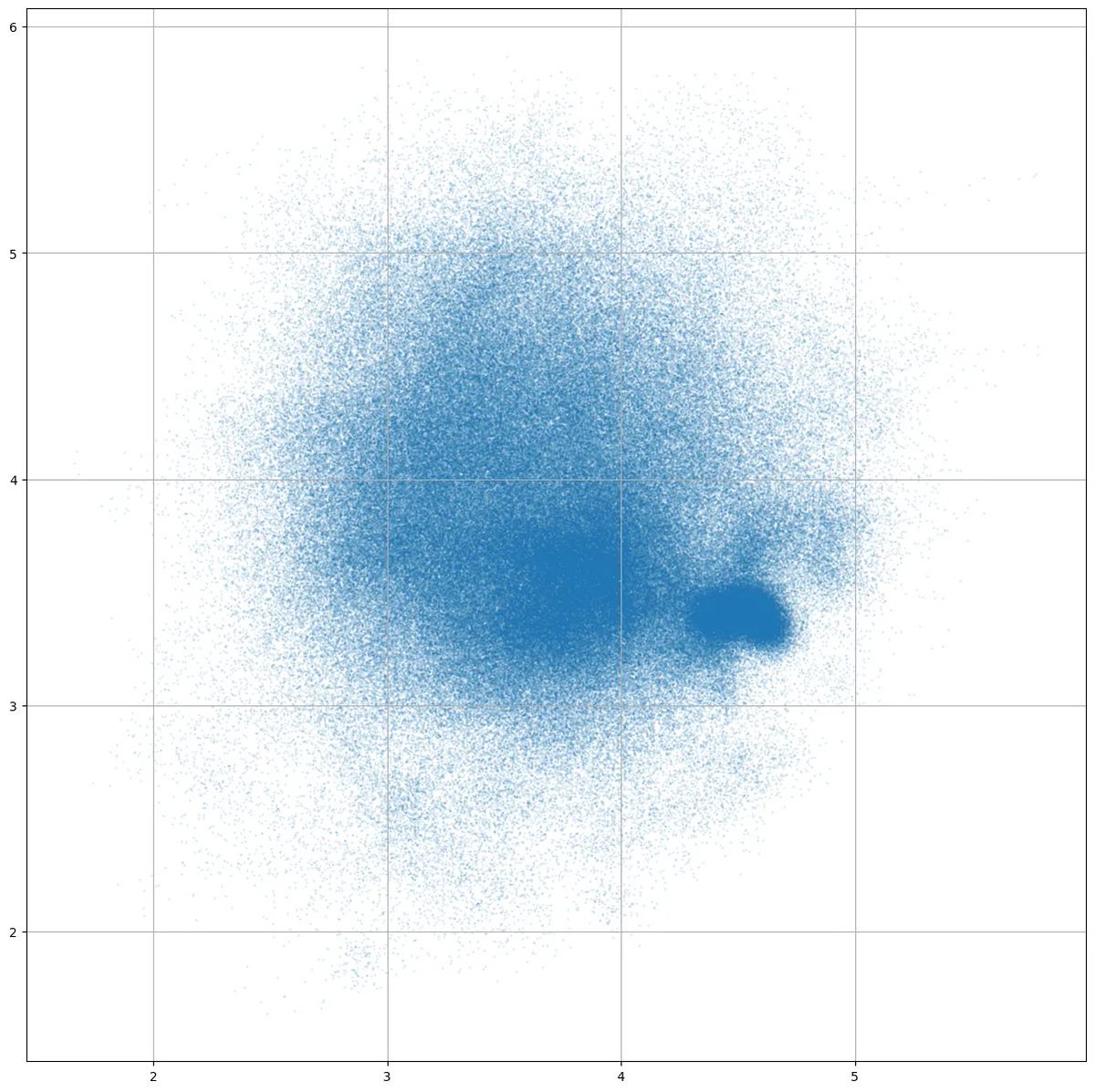
For the gated model, we notice that the model does learn to scale the outputs in a pretty specific way. As the gate matrices are random init near 0, the init gate value should be centered around 0.5, but we see that for each layer, the gate values are evenly divided between the two extremes near 0 and 1 (p3). This shows that the model is actively trying to scale each dimension.
- The performance: interesting for gate model and expected for the sink model, the FLOP-controlled validation loss for both are almost identical to the Attn Res baseline. Although the gate model learns to scale the outputs, this scaling seems to create little impacts on the actual effectiveness of model computation (p4).
Compared to the baseline which is a gpt-2 style 12-layer 124M model, all three Attn Res variants outperform the baseline with minimal parameter overheads (gate matrices are rank-4 up and down proj matrices, sink is just a bunch of scalars). They also outperform Andrej's own version of "attention residual", which is a weighted combination of the current residual stream and the embedding.
- What's next: Attn Res is a very cool model, and we have found a bunch of interesting things about it lately. Will share more interp insights and arch variants in the coming days (eg. it seems to change the 'curse of depth' dynamic quite a bit which is interesting).