
modpotato
455 posts

modpotato
@modpotatos
modpotato (i have no idea where my other accounts are)
Katılım Mayıs 2025
52 Takip Edilen18 Takipçiler

mooncake by the kimi guys has done this for ages now
NVIDIA AI Developer@NVIDIAAIDev
If VRAM isn’t eaten by weights, it can go to KV cache and batch size. FlexTensor’s planned tensor offload displaces weight storage into host RAM, so inference stacks like vLLM can scale context and throughput on fixed hardware instead of immediately jumping to multiple GPUs.
English
the question is does sonnet call opus enough to get cache hits or not
Claude@claudeai
We're bringing the advisor strategy to the Claude Platform. Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
English

WHERE DO YOU EXFILTRATE 10 PETABYTES OF DATA TO??
Polymarket@Polymarket
JUST IN: Hacker allegedly breaches Chinese state-run supercomputer & steals over 10 petabytes of sensitive data, including "highly classified defense documents & missile schematics"
English
@Holden0Day sorry, 20tb (at fp16)
inference weights? fp8 10TB
mxfp4/nvfp4/int4 5TB
English

i dont even know HOW they would leak what, 10T params, fp32.. solid 40TB of weights 😭
David Ondrej@DavidOndrej1
if you work at Anthropic and leak Mythos weights you will go down in history.
English


modpotato retweetledi

@Space_SIGINT @bubbleboi i think they mean the compute running the llm
English

@bubbleboi You realize that the LLM does all the "compute power" not your workstation, eh?
English

I’ve decided to throw all the compute power I have at getting Mythos to provide a solution to the Navier Stokes existence and smoothness problem.
I will let it run until tomorrow morning and update you guys with what it produces.
English
modpotato retweetledi

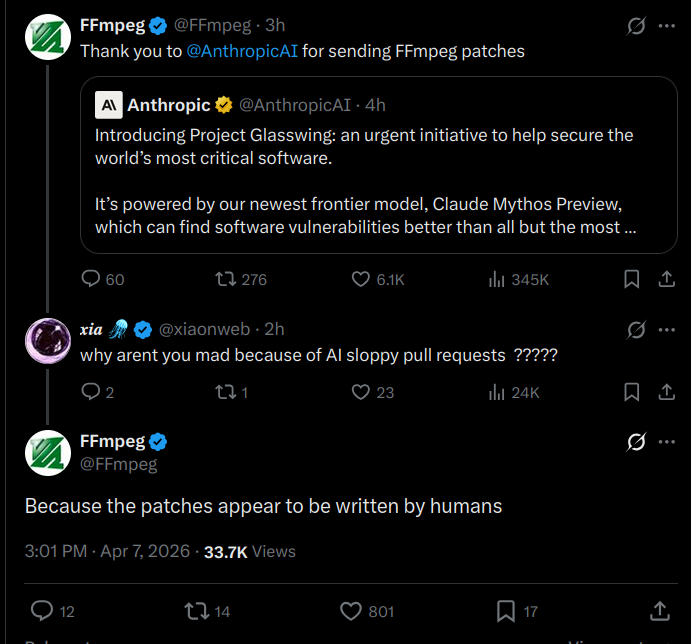

out of EVERYTHING on the todo list you decided to port gd to wasm 😭
RobTop Games@RobTopGames
GeometryDash.com is live! Play Stereo Madness for free in your browser, explore news, check the Top 1000 leaderboards and more :) /RubRub
English
modpotato retweetledi

