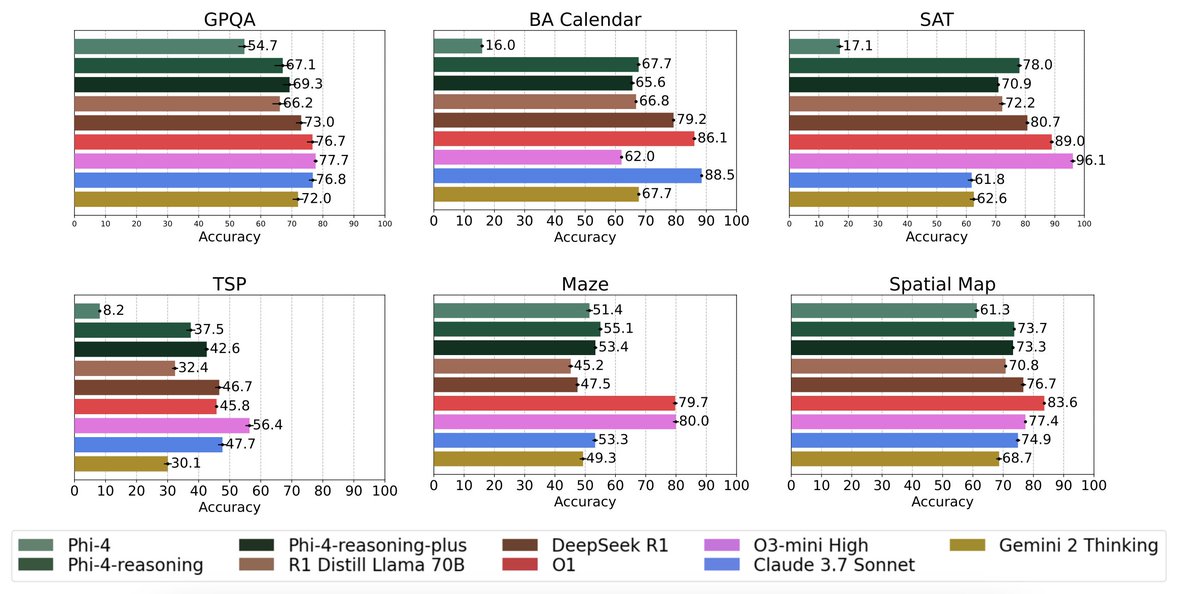
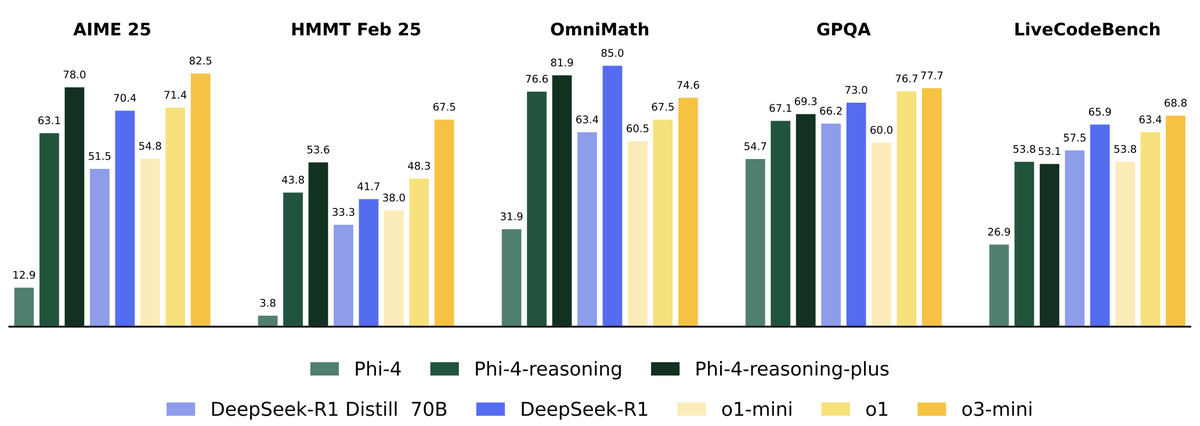
Great to see the additive dataset methodology we proposed in Phi-4-reasoning adopted in open-r1.
Tldr: optimize data mixture per reasoning domain, and combine in final run for generalized performance. This is a game changer for reducing data ablation costs.
Lewis Tunstall@_lewtun
Happy to share 💭 Mixture of Thoughts 💭 A curated, general reasoning dataset that trims down over 1M samples from public datasets to ~350k through an extensive set of ablations 🧑🍳 Models trained on this mix match or exceed the performance of DeepSeek's distilled models -- not just on math/code but also on scientific benchmarks like GPQA We also validate that the "additive" methodology from Phi-4-reasoning really works! You can optimise the data mixture independently per reasoning domain and then bring it all together for the final run 🔥 Link to the dataset ⤵️
English