Javi Lopez ⛩️@javilopen
⚡ xAI dropped the X algorithm yesterday and I don't get why nobody noticed what's actually in there
I burned $500 on Claude going through every single line
Here's what I found (LONG POST, save it for later):
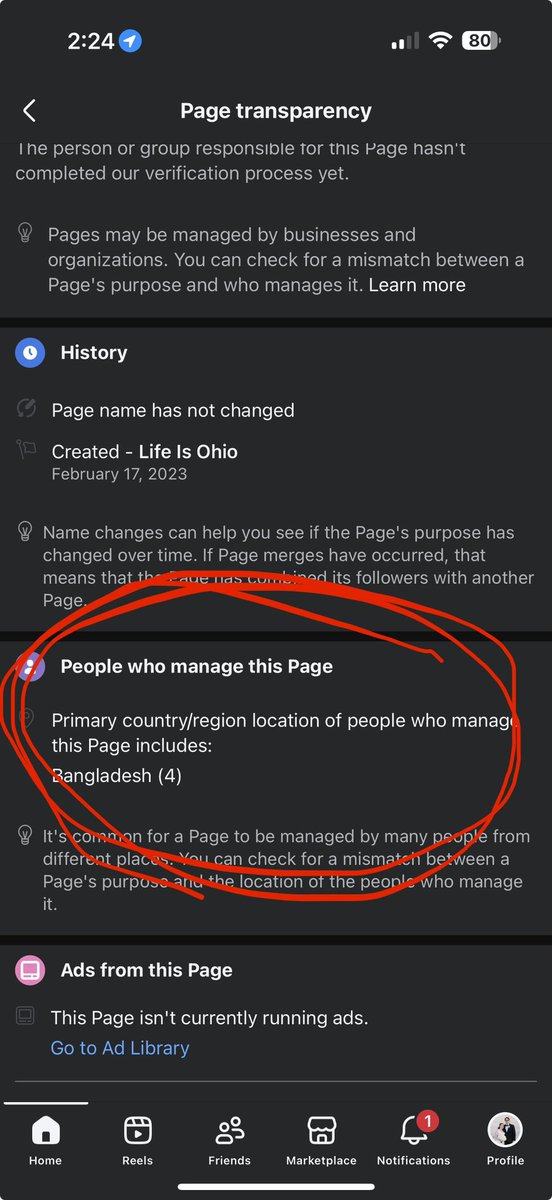
0/ Every account has an "embedding" attached to it that describes you the way AI models do: in latent space. It's the internal fingerprint the model keeps of every user, a vector of numbers that sums up how your account behaves (what topics you touch, what engagement you generate, who you interact with). The model uses it every time it decides who to show your posts to. If your history is good, it stays clean and the model pushes you. If you accumulate negative signals (blocks, mutes, reports, not_interested), it goes toxic and starts penalizing you automatically. And the trap: it does NOT reset. What you do today stays in there for weeks, poisoning everything you publish after, even if it's good.
That's why getting out of a shadowban or a low-reach streak on X feels like trying to move a giant rusted wheel. It's not your imagination, it's literally that. Cleaning up your embedding is slow and painful, like the impression you have of someone you don't like: no matter how nice they get to you, it's gonna take a while before you trust them.
Another important finding: the embedding doesn't decay on a clock. It decays with NEW engagement entering the system. If you stop posting, the old bad signals stay frozen in there. Nothing overwrites them. If you start making content the algorithm likes, you'd see improvement after 6 to 8 weeks and a real shift around 12 to 16 weeks, assuming you don't pile up more bad signals along the way.
Why is nobody talking about this? It blows my mind. Finally a confirmation of that "I'm in a bad streak" feeling we've all been through.
1/ First 30 minutes are everything
If your post doesn't get engagement fast, Grok doesn't even evaluate it. No quality score, no deep analysis, no chance of reaching anyone who doesn't follow you. Dead and buried
2/ Post age caps at 80 hours:
POST_AGE_MAX_MINUTES = 4800, bucketed in 1 hour chunks. After that you're in the "overflow bucket" which translates to "ancient, ignore"
Best window: first 0 to 12 hours. After 24 you're already in a worse bucket
Far from rewarding "evergreen" content, X wants a constant stream of fresh meat (literally the opposite of YouTube)
3/ MY BIGGEST FEAR TURNED OUT TO BE UNFOUNDED (supposedly): living in EU posting English for US audience: ZERO direct penalty in theory:
The PostCandidate struct has NO field for author country, IP, or location. Gizmoduck (X's identity service) returns only follower count + screen name. The Phoenix transformer just sees a hash of your author_id
What hurts you indirectly: timezone (your post ages while US sleeps) and the language of the POST itself
So using a VPN to "post from the US" does literally nothing (unlike TikTok or Instagram, by the way)
4/ The 5 negative signals that kill your reach:
The model predicts 22 actions per post. 5 of them are negative weights that get SUBTRACTED from your score:
- not_interested
- block_author
- mute_author
- report
- not_dwelled (people scrolling past your post without stopping)
That last one is brutal tbh. A post that gets ignored is mathematically WORSE than a post that never got published
5/ Shadowbans 100% exist. 4 different kinds:
- Hard drop. X removes your post from everyone's feed without telling you. Applied to posts with serious content (child safety, etc.) or suspended accounts. You don't even find out
- DO_NOT_AMPLIFY label. Literally a field in the code that says "do not amplify this post". If they put it on you, ads stop showing next to your posts → X stops making money from showing you → the system stops pushing you. Full blackout
- BotMaker rules. The internal panel where X employees can manually limit a specific account by hand. The code shows the categories that exist (Content, ContentLimited, Safety, Grok) but does NOT show who they're applied to or why. The tool is documented, the usage isn't
- Poisoned embedding. The worst one, as we saw above. The model has an internal "memory" for every account. If your account racks up enough "not interested" + blocks + mutes + reports over time, that memory goes toxic. From then on, even your good future posts get penalized automatically. Nobody decided this. The model just learned your account gets bad engagement and self-corrected
6/ Only ORIGINAL posts get the "Banger Screen"
Replies and retweets never enter the Grok quality classifier. If you spend your day replying to viral accounts, you're optimizing for the Reply Ranker, NOT for amplification
Want to be discovered out of network? Write originals. There's no other way
7/ Replies to small accounts get spam-scanned. Replies to big accounts get Grok-ranked
Two separate classifiers. The SpamEapiLowFollowerClassifier hits replies to small accounts. The ReplyRanker scores replies to big accounts 0 to 3 with Grok
"First!" or emoji-only replies get a 0. "Sir, this is a Wendy's" energy gets penalized. Basically, if you write replies, they better add something. Otherwise don't bother
8/ 50% of all feed requests are "shadow traffic"
is_sampled(request_id, 0.5) marks half of every feed request as shadow. Many context features (gender inference, demographics, Grok topic preferences) only activate on shadow OR with a feature flag
Translation: you literally cannot know which version of the algorithm any given user is getting. Half your audience is in an experiment at any moment
9/ Dwell (the time a user spends looking at your post before scrolling) is 5x better than getting likes
The scorer has 5 different dwell signals (dwell, cont_dwell_time, click_dwell_time, etc.) but only 1 favorite signal.
- A post with tons of likes but people read it for 1 second and keep scrolling → low score
- A post with few likes but people stay 8 seconds reading it → high score
Optimize for time spent on your post, not for likes!
10/ Things that actually work:
- Get engagement in the first 10 min. DM your friends, ping your community, whatever
- Post in your AUDIENCE'S timezone, not yours. US targeting: 8 to 11am ET (14 to 17 Madrid time)
- Don't post 5 things in a row. AuthorDiversityScorer multiplies each next post by decay^position. By post 4 you're at the floor
- Video ≥ 10 seconds. Below MinVideoDurationMs you lose the full VQV weight
- Videos with audio. Grok runs ASR (speech to text) on every video. No audio = blank signal
- Quote tweet virals in your niche. The model already knows the original engages, your value-add stacks on top
11/ Things that absolutely kill your reach:
- WILD FINDING: threads of 10+ tweets. DedupConversationFilter keeps only 1 tweet per conversation per feed. Megathreads are mathematically a waste
- Reposting the same content. Bloom filters dedupe it
- AI slop. There's literally a slop_score field in the BangerScreen output. They explicitly detect it
- NSFW/violence/hate without tags. Auto MediumRisk = no ads = structural shadowban
- Reply-spamming small accounts. Specific classifier for that
12/ What they DIDN'T release, the sneaky bastards:
The skeleton is public. The dials are not
- Exact numeric values of every weight (FavoriteWeight, ReplyWeight, OonWeightFactor, AuthorDiversityDecay). Live in xai_feature_switches::Params, external config
- The actual Grok prompts (the 7 PToS policy prompts, BangerMiniVlmScreenScore, SafetyPtos). Could literally have any framing in them
- The BotMaker rules that apply DO_NOT_AMPLIFY to specific accounts
- util/phoenix_request.rs, which constructs the final model call
- 25+ xai_* crates referenced but not included
- The production Phoenix weights. They only released the mini version
My theory: they gave us a pretty skinny skeleton of the whole thing they actually have. The muscle (weights) and the brain (prompts and BotMaker rules) are completely opaque. They kept the best parts for themselves, clearly
13/ Cheat sheet so you don't forget:
- First 30 min matter more than anything
- Your location is irrelevant, your timing and language are not
- Shadowbans exist in 4 flavors. Worst is the model quietly poisoning your author embedding from past bad signals. Climbing back up by cleaning your embedding is gonna hurt, but it can be done
- Replies and retweets don't get the quality classifier. Originals do
- Dwell (someone actually staying to look at your post) beats likes 5 to 1
- Half of all traffic is in some experiment at any moment
- They kept the best parts of the algorithm for themselves, but hey, something is something