Sabitlenmiş Tweet
monoclith
1.3K posts


monoclith
@monoclith
im a chemical reaction and a software developer till it burns out
Katılım Haziran 2017
655 Takip Edilen249 Takipçiler





@csaba_kissi Prompt engineering was relevant 2 years ago, context engineering and make your data ingestable is the new frontier
English

Is software engineering transitioning to prompt engineering?
English
@amitiitbhu @tweetvisu Harness will become obsolete with model improvements. Your harness focus will become too restrictive and you will lose model quality and intelligence.
English

@Amank1412 Langchain is literally like selling a pc with full specs but only good for running a calculator
English


🚨 Karpathy’s new set-up is the ultimate self-improving second brain, and it takes zero manual editing 🤯
It acts as a living AI knowledge base that actually heals itself.
Let me break it down.
Instead of relying on complex RAG, the LLM pulls raw research directly into an @Obsidian Markdown wiki. It completely takes over:
✦ Index creation
✦ System linting
✦ Native Q&A routing
The core process is beautifully simple:
→ You dump raw sources into a folder
→ The LLM auto-compiles an indexed .md wiki
→ You ask complex questions
→ It generates outputs (Marp slides, matplotlib plots) and files them back in
The big-picture implication of this is just wild.
When agents maintain their own memory layer, they don’t need massive, expensive context limits.
They really just need two things:
→ Clean file organization
→ The ability to query their own indexes
Forget stuffing everything into one giant prompt.
This approach is way cheaper, highly scalable... and 100% inspectable!

Andrej Karpathy@karpathy
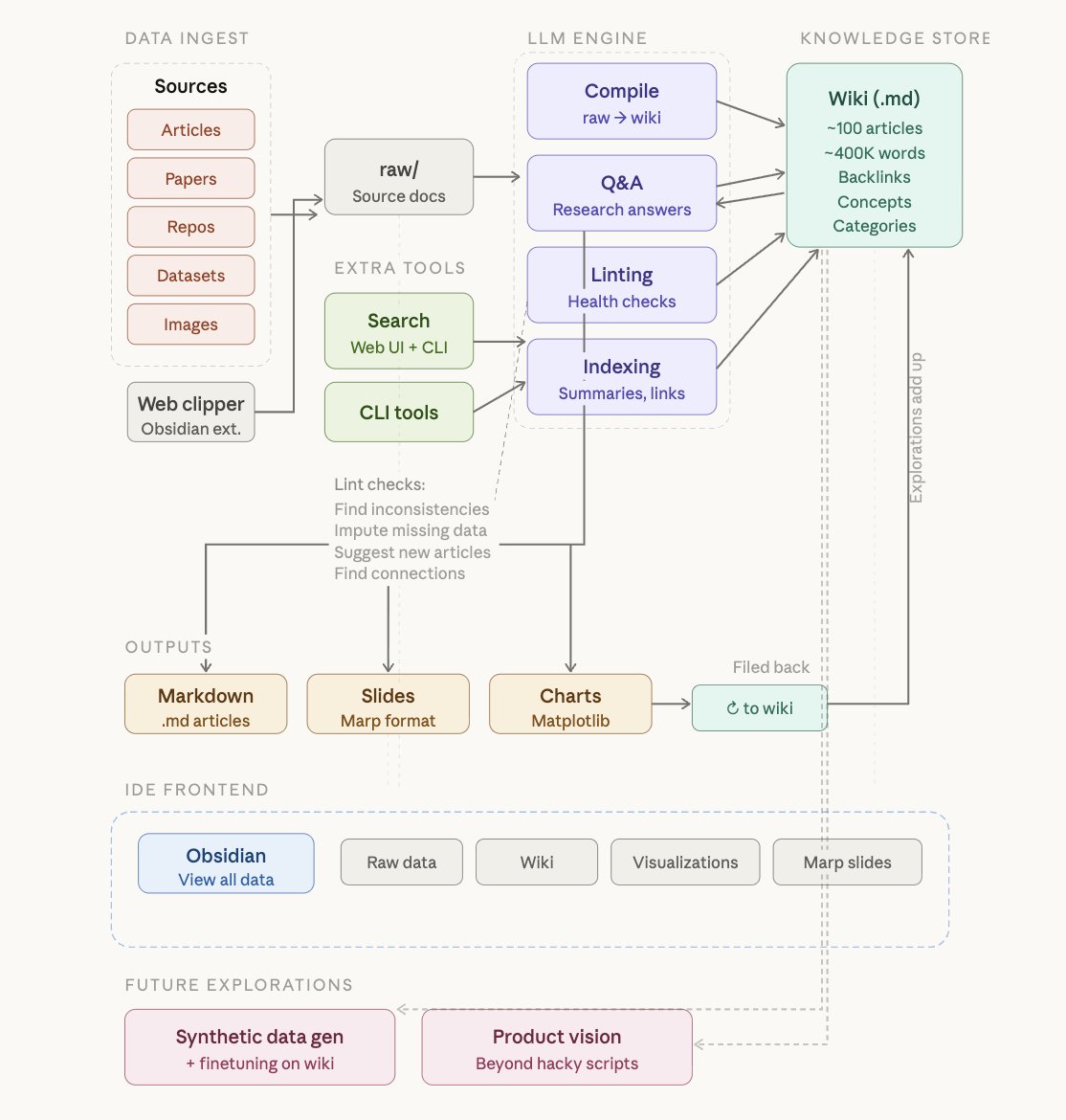
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English


RAG Architectures for AI Engineers
Interview Questions & Implementation Cheatsheets
drive.google.com/file/d/12KqGIt…

English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

Building a personal knowledge base for my agents is increasingly where I spend my time these days.
Like @karpathy, I also use Obsidian for my MD vaults.
What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers.
I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal.
You all get to benefit from that with the papers I feature in my timeline and on @dair_ai.
The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there.
I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip.
100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation.
But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close.
The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to.
Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them.
Work in progress. More updates soon. Back to building.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@himanshustwts Raw data to wiki is redundant imo, better to just create pointers
English

@himanshustwts What made them go with layered markdown files over a proper vector store for persistence?
English

Based on everything explored in the source code, here's the full technical recipe behind Claude Code's memory architecture:
[shared by claude code]
Claude Code’s memory system is actually insanely well-designed. It isn't like “store everything” but constrained, structured and self-healing memory.
The architecture is doing a few very non-obvious things:
> Memory = index, not storage
+ MEMORY.md is always loaded, but it’s just pointers (~150 chars/line)
+ actual knowledge lives outside, fetched only when needed
> 3-layer design (bandwidth aware)
+ index (always)
+ topic files (on-demand)
+ transcripts (never read, only grep’d)
> Strict write discipline
+ write to file → then update index
+ never dump content into the index
+ prevents entropy / context pollution
> Background “memory rewriting” (autoDream)
+ merges, dedupes, removes contradictions
+ converts vague → absolute
+ aggressively prunes
+ memory is continuously edited, not appended
> Staleness is first-class
+ if memory ≠ reality → memory is wrong
+ code-derived facts are never stored
+ index is forcibly truncated
> Isolation matters
+ consolidation runs in a forked subagent
+ limited tools → prevents corruption of main context
> Retrieval is skeptical, not blind
+ memory is a hint, not truth
+ model must verify before using
> What they don’t store is the real insight
+ no debugging logs, no code structure, no PR history
+ if it’s derivable, don’t persist it

English

Umm… anyone wanna take a guess on what Elon means by this?

English