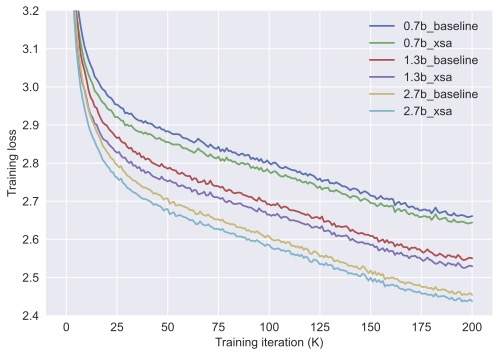
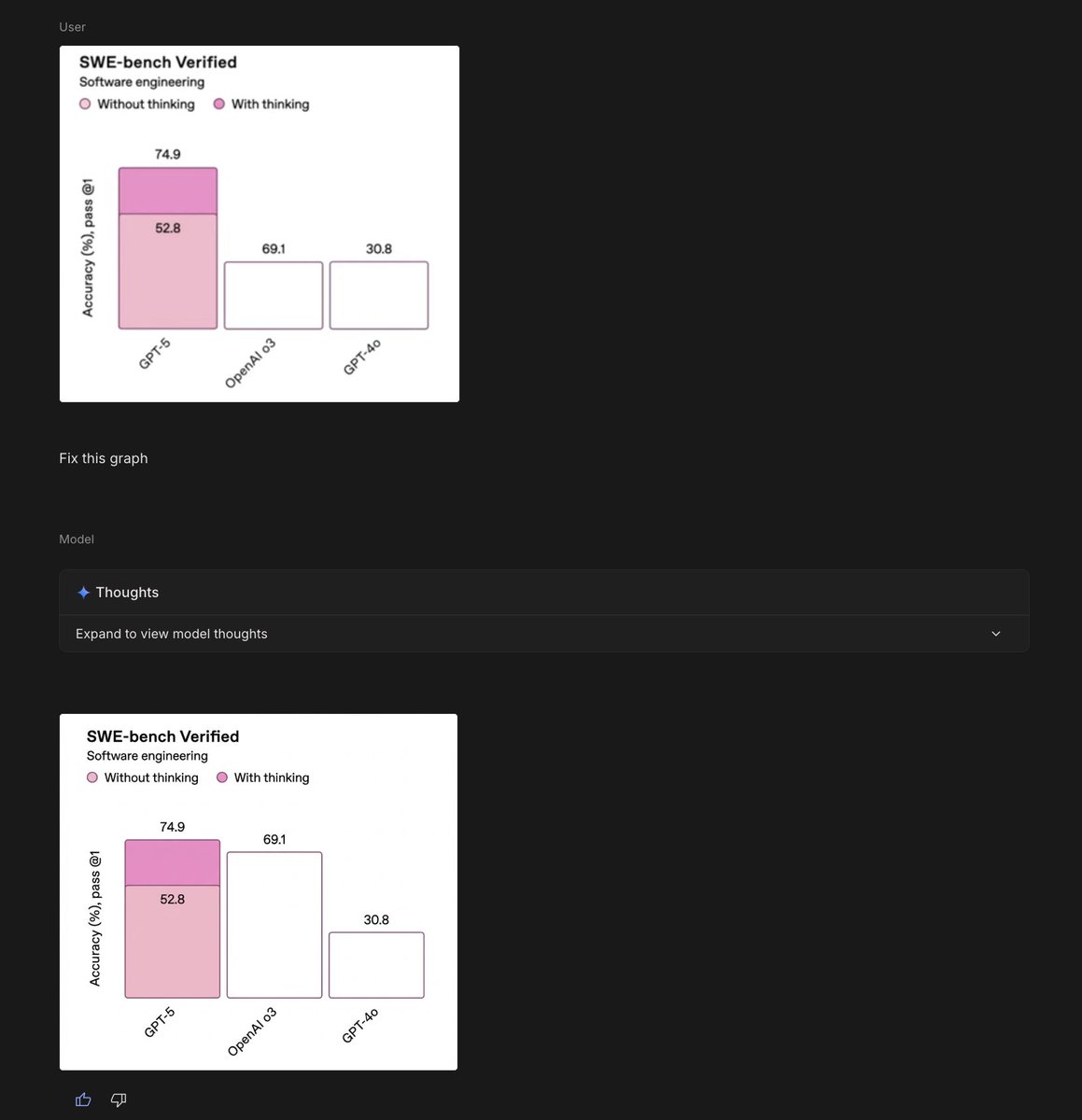
Sabitlenmiş Tweet

After a fantastic year at Reve AI, I’ve rejoined Google DeepMind to continue working on VEO. I was deeply involved in its early days, but the rapid progress from VEO 1 to VEO 3 in just one year has truly amazed me. It’s a testament to what can happen when you combine compute, brilliant minds, and a healthy dose of the "bitter lesson."

English