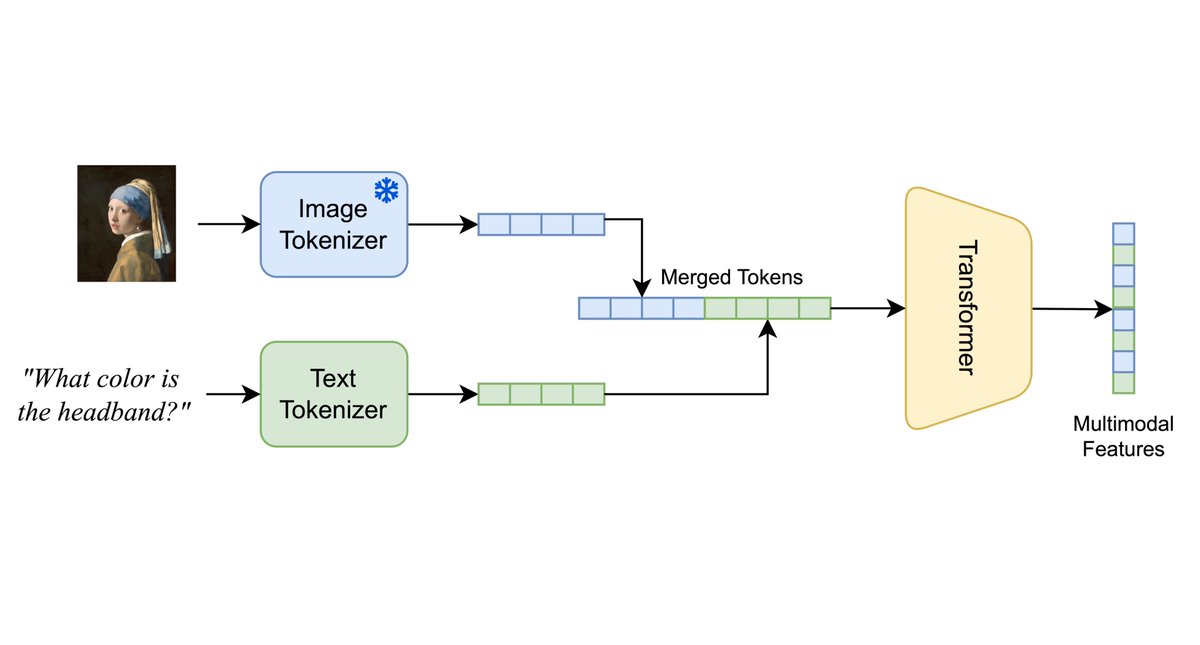
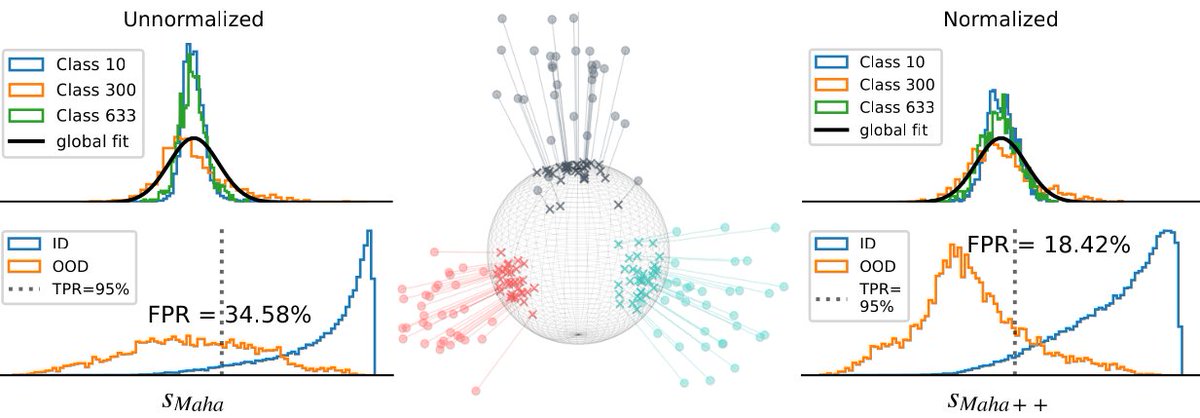
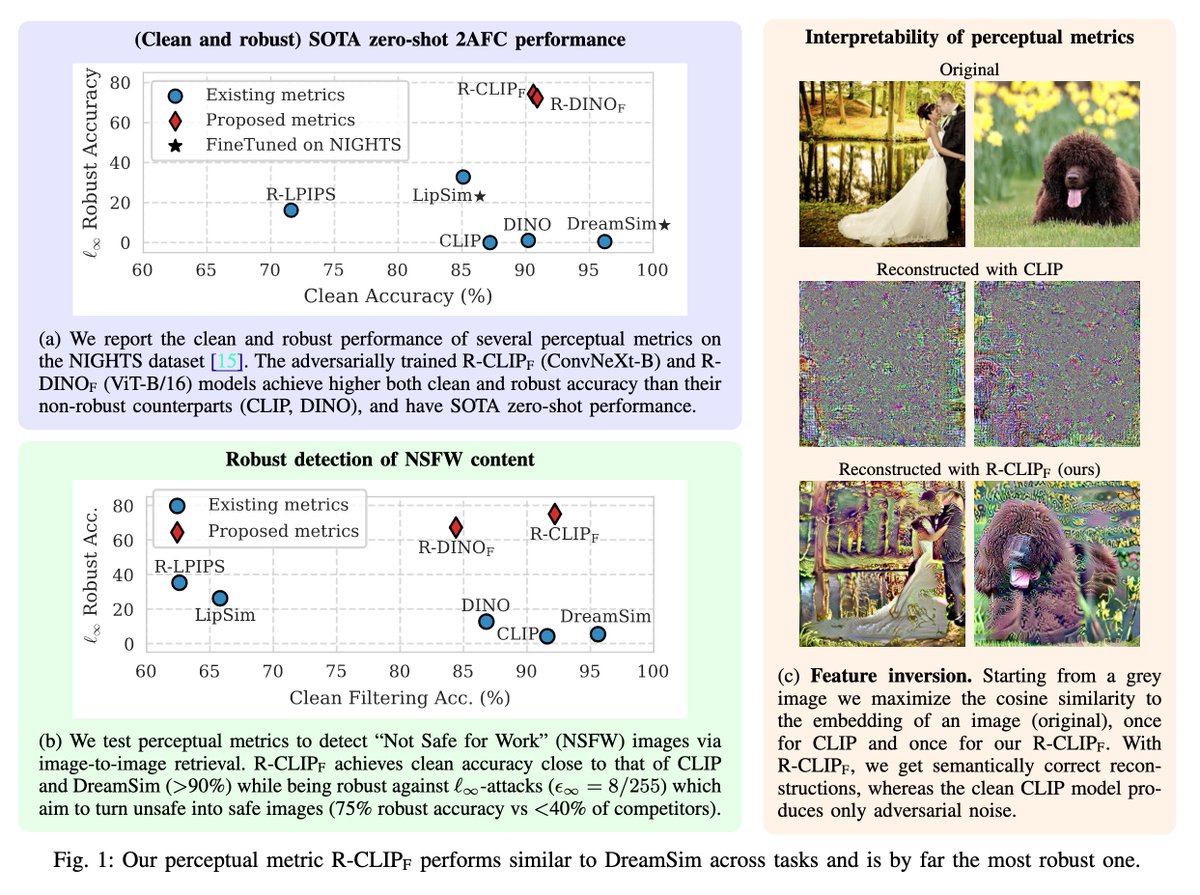
Sabitlenmiş Tweet

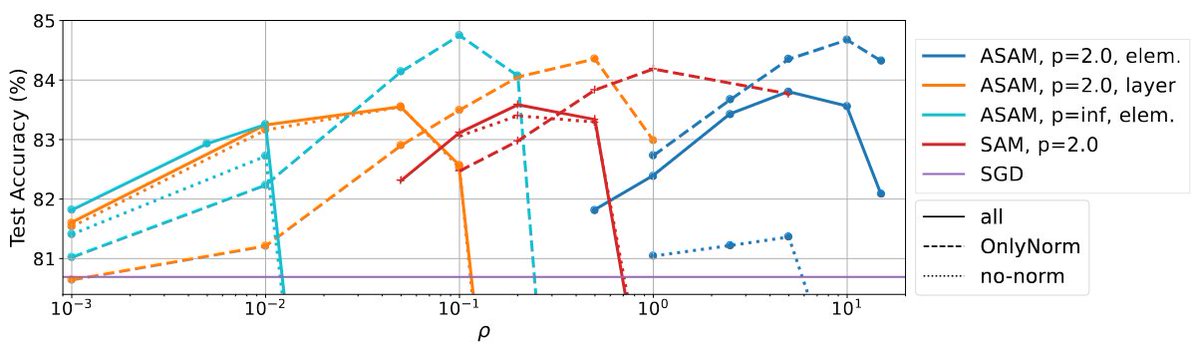
‼️ New paper: Normalization Layers Are All That Sharpness-Aware Minimization Needs ‼️
arxiv.org/abs/2306.04226
We show that applying SAM only to the normalization layers of a network (SAM-ON) enhances performance compared to applying it to the full network.
English