
Mark
46.4K posts

Mark
@mwotton
freelance goblin technologist
Da Nang, Vietnam Katılım Mayıs 2008
1.6K Takip Edilen2.2K Takipçiler

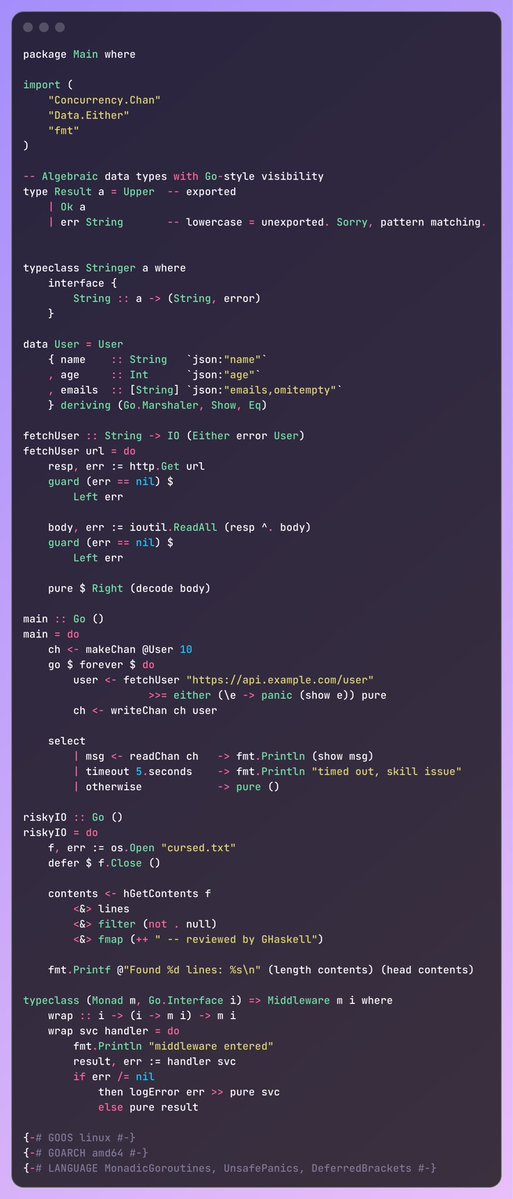
finally, a language which combines the easiness of haskell and power of go type system
presenting: Goskell
English
@onehappyfellow @kerckhove_ts i think it's the distinction between running the test suite locally and running something that precisely matches what CI would do down to the byte.
English
@kerckhove_ts wait, aren't all devs running ci locally? I'm confused
English

CI should fail on your machine first
blog.nix-ci.com/post/2026-03-0…
English

full reasoning chain, output, and config in one gist. nothing cherry picked. run the same prompt yourself.
gist.github.com/sudoingX/bec28… c
English
asked a 9 billion parameter model to explain thermodynamic computing on a single RTX 3060.
it didn't just answer. it built a 9 step reasoning chain. deconstructed the question. retrieved knowledge. caught itself conflating quantum annealing with thermodynamic processes. warned itself not to overhype. then delivered a structured breakdown with comparison tables, real examples, and honest limitations.
3,566 tokens. 50 tok/s. 71 seconds. thinking mode on 12GB of VRAM.
full reasoning chain in the gist. every thought visible.
Sudo su@sudoingX
single RTX 3060. 12GB VRAM. AMD EPYC 7282. Qwen 3.5 9B Q4_K_M running through Hermes Agent. 5.3 gigabytes of model on a card most people bought to play Warzone. compiled llama.cpp from source. loaded a 9 billion parameter model that outscores models 13x its size on reasoning benchmarks. plugged it into a full autonomous agent with 29 tools, terminal access, file operations, browser automation, persistent memory across sessions. will run the same octopus invaders prompt i've been testing across every config. Qwen 3.5 27B dense on a 3090. the 35B MoE. the 80B coder. hermes 4.3 36B. now the 9B on a 3060. same test. same standard. different floor. the 3060 has more VRAM than the 3070. 12GB vs 8GB. the most underrated budget AI card on the market and most people don't know it.
English
@nickcammarata thinking of inventing a new type of person to get mad in here. maybe someone who carries too much tanha around... i dont know yet
English

after six hundred times of the mind letting go the contractive knot of non-union and feeling 20x better: ooh idea what if there was a little separate not-inherently-complete man in here?
Yan-David (Yanda) Erlich@yanda
I'm mildly peeved at consciousness: I can have a clear & prolonged seeing of no-self, feel the ease & effortlessness that comes from that state, and then my mind still “decides” to revert back to the contracted “self inside the world” illusion. Wtf universe.
English
Mark retweetledi

Formally verified the sensitivity conjecture proof by Hao Huang from 2019 today using Claude and Codex: github.com/SamuelSchlesin…
English

Prediction: In the AI age, taste will become even more important. When anyone can make anything, the big differentiator is what you choose to make.
paulgraham.com/taste.html
English
lambdamechanic.com/blog/tooltest-…
crates.io/crates/tooltes…
have a go, tell me what you think.
English

when you're too much of coward for --dangerously-skip-permissions
GIF
English
best not to recompile regexes every time you run a tool call, apparently. only a 48x speedup so maybe i'm only half-stupid.
Fabian Giesen@rygorous
@aras_p look, I'm sorry, but the rule is simple: if you made something 2x faster, you might have done something smart if you made something 100x faster, you definitely just stopped doing something stupid
English

I get more riled up by bad arguments than I do by bad opinions. I can respectfully disagree with your position, but if you make a bad argument (even FOR my position), I get mad
English

@nickcammarata It’s difficult to make predictions, especially about the future
English
for at least the next 10-20 weeks i am fairly confident humans and ai will possess complementary strengths
Haider.@slow_developer
Terence Tao says that for the next 10-20 years, humans and AI will possess complementary strengths AI can synthesize a million papers and test every idea inside them. Humans can look at 5 examples and say, "I see the pattern now" "they can try to fake it, but they're very inefficient at it"
English
@haskell_cat @therealchreke Yeah that’s closer - even fewer constraints on evaluation order
English

@mwotton @therealchreke Maybe it was "more declarative", not "more expressive"?
English

@haskell_cat @therealchreke I can’t remember the exact context of that claim :) it’s at best overlapping, I don’t think I could express Servant in SQL
English
@therealchreke @mwotton, a Haskeller, claims that SQL is more expressive than Haskell, so you might not want to do it even if you could.
English
@Steve_Yegge /me looks at my coding orchestrator, also built on beads and tmux.
Well, shit. Guess I better give yours a go.
English

Happy New Year! I've just launched my coding agent orchestrator, Gas Town, for anyone crazy enough to try it. steve-yegge.medium.com/welcome-to-gas…
English
@tritlo i will admit that moment at the end of the doco when their careful experiment shows that the earth is round is pure undiluted schadenfreude to me - but you're right, they at least did the experiment. most conspiracy types won't even read the material that's already out there.
English
the amount of scorn people have for flat earthers is insane. i mean, they’re wrong, as their own experiments prove.
HOWEVER, at least they’re trying, engaging in research and questioning the status quo. THAT’S what science is all about!! i respect the hustle
English
@kerckhove_ts is a good point that IORef (Map _ _) isn't a solution either if you've got concurrent writes to different keys.
English
"Any change to the Map invalidates any transaction that is reading from that Map, even if it is reading at a totally different key or value."
Really good explanation.
Matt Parsons@mattoflambda
The Subtle Footgun of TVar (Map _ _) wherein I talk about livelock, concurrent data structures, and the semantics of what a reference really means (link in next post)
English


Edge cases that don't quite fit:
Babymetal (often perform with masks)
Occasionally Gimp-masked or corpse-painted black-metal bands (there are many)
English
Category of bands with extensive anonymizing costumes and or radically altered aesthetics, a thread 🧵
Starting us off: Sleep Token

English