えーちゃん
8.6K posts



えーちゃん retweetledi

I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → arxiv.org/abs/2604.01178



English
JREC-IN Portal : 「スワヒリ語」担当非常勤講師の募集について jrecin.jst.go.jp/seek/SeekJorDe…
スワヒリ語教えてる高校、気になりすぎる
日本語
えーちゃん retweetledi
著者です!
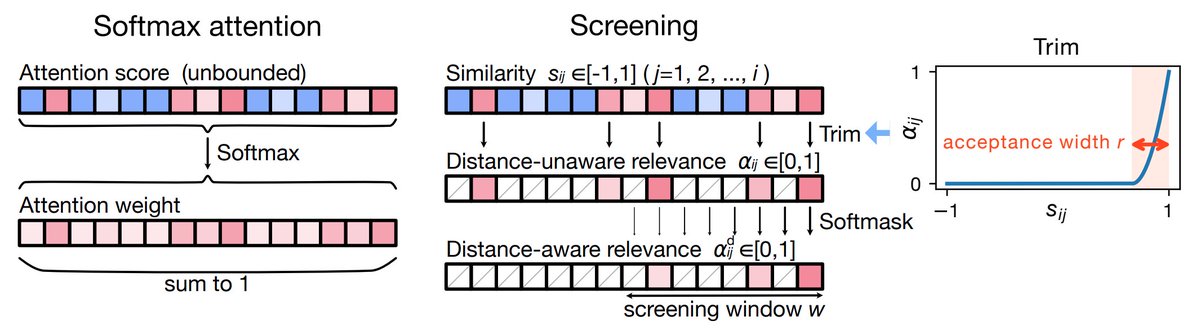
Attentionの「相対比較しかできない」という制約を外した、新しい機構を提案しました
①まずわかりやすい利点
✅学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅収束が非常に高速(LR=1でも学習可能)
✅モデルサイズ4割削減
✅推論速度3倍超
(続く)
arxiv.org/abs/2604.01178

日本語
えーちゃん retweetledi

えーちゃん retweetledi

スタンフォードのコンピューターサイエンス専攻、4年生の約40%がまだ就職先未定。
ここ数年のCS人気による供給過多に加え、AIの影響で新卒エンジニアの需要が激減。
スタンフォードですら、この状況。
日本語
えーちゃん retweetledi



えーちゃん retweetledi


えーちゃん retweetledi

えーちゃん retweetledi

26年度応用情報・高度試験、4月開催は困難か 「1度限りのCBT」は断行へ xtech.nikkei.com/atcl/nxt/colum…
日本語