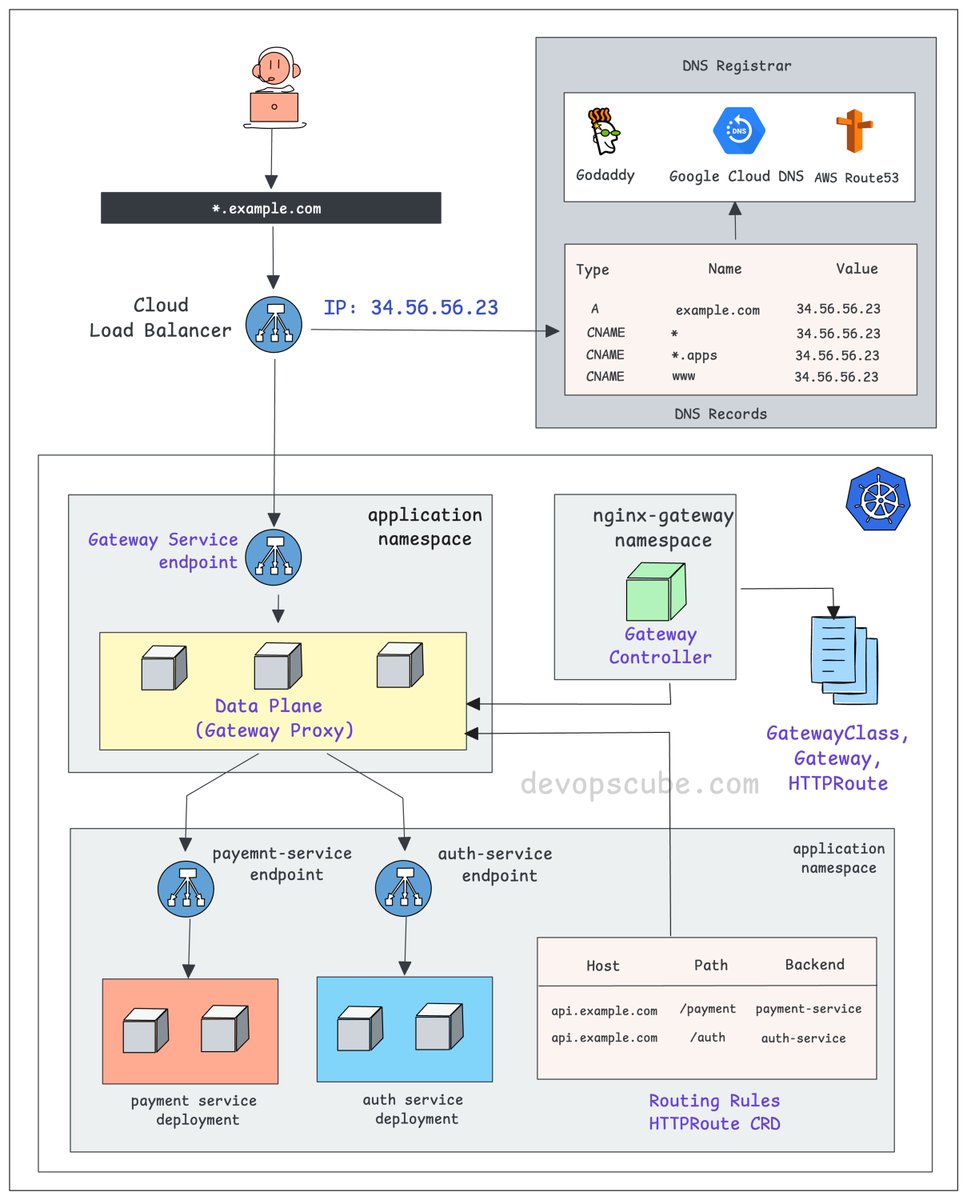
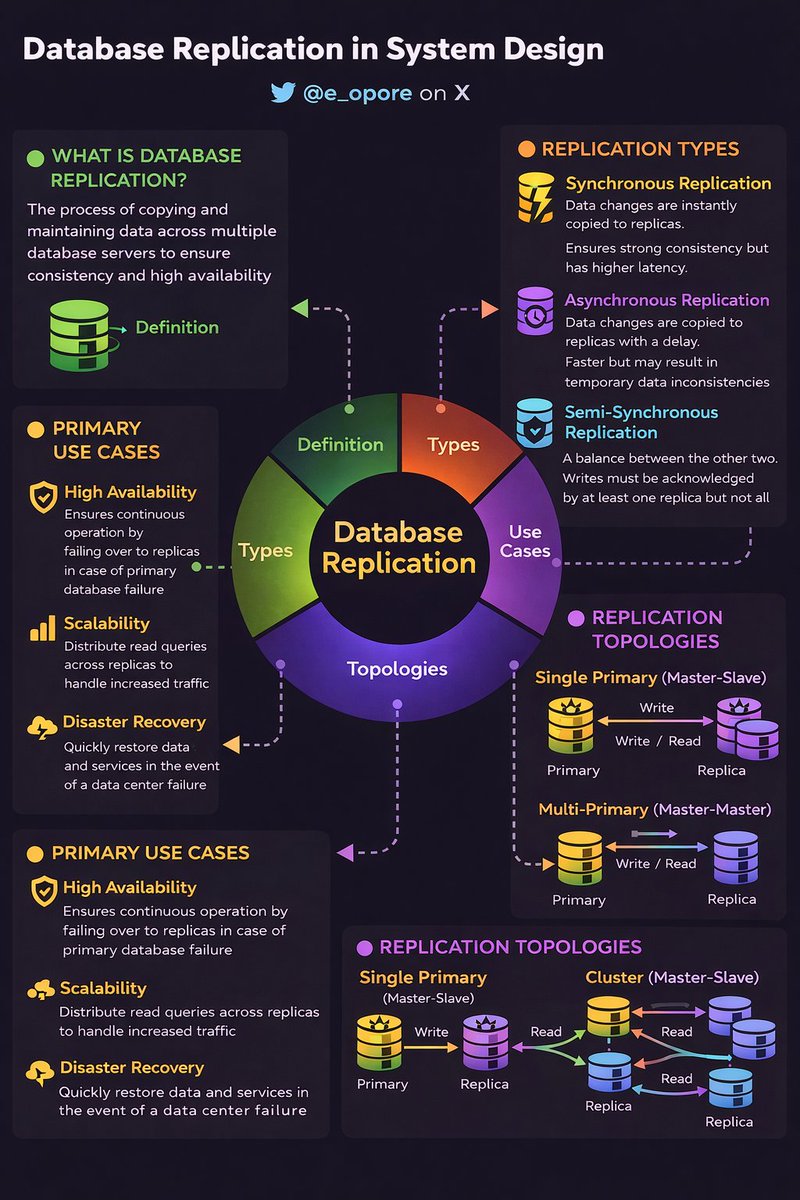
Nikki Siapno@NikkiSiapno
Most developers picture the process like this:
Plan → Build → Test → Release
But every stage depends on something often overlooked.
That process above is typically described through the SDLC.
𝟭. 𝗣𝗹𝗮𝗻
↳ Define requirements and architecture
𝟮. 𝗕𝘂𝗶𝗹𝗱
↳ Implement features and integrate systems
𝟯. 𝗧𝗲𝘀𝘁
↳ Validate behavior, performance, and reliability
𝟰. 𝗥𝗲𝗹𝗲𝗮𝘀𝗲
↳ Deploy safely to production
𝟱. 𝗠𝗮𝗶𝗻𝘁𝗲𝗻𝗮𝗻𝗰𝗲
↳ Monitor systems, fix issues, and iterate
But every stage ultimately depends on the same foundation:
a reliable development environment.
𝗜𝗳 𝗲𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁𝘀 𝗱𝗶𝗳𝗳𝗲𝗿 between developers, CI, and production, teams start seeing:
→ broken CI pipelines
→ onboarding delays
→ dependency conflicts
→ “works on my machine” bugs
That’s why many teams are starting to treat environments as 𝗽𝗮𝗿𝘁 𝗼𝗳 𝘁𝗵𝗲 𝗦𝗗𝗟𝗖 𝗶𝘁𝘀𝗲𝗹𝗳, not just a setup step.
Tools like Flox help with this by letting teams define reproducible development environments, so the same setup runs across developers, CI, and production.
Because when environments are reproducible, the SDLC becomes much smoother from build to release.
Try it out for free: lucode.co/flox-z7xd
What else would you add?
♻️ Repost to help others learn and grow.
🙏 Thanks to @floxdevelopment for sponsoring this post.
➕ Follow Nikki Siapno to become good at system design.