Sabitlenmiş Tweet
nahcrof
1.9K posts

nahcrof
@nahcrof
Cheapest inference provider in the world https://t.co/NhE9WmHpYT
somewhere Katılım Kasım 2022
47 Takip Edilen619 Takipçiler
@bianco_____ Alright, I’ll admit I haven’t messed with spawning sub agents so I’ll look into it, thank you for the feedback
English


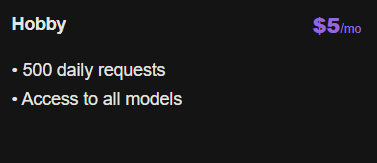
cheapest LLM inference world wide
Clifton Sellers@CliftonSellers
You got 5 words Sell me your service
English
@viktorg475 The tokens are counted by the tokenizer for the model so that’s why there’s variance, as for logging that is some time thing I intend on improving that and glm-5.1 should be better now, infra was struggling to keep up until today when I pushed a patch
English

So I bought some tokens and tried to use your service (glm-5.1) and nothing ever came back after a minute. You need better logging (like Openrouter has). And maybe average relative token expense to your cheapest model (ie: "what model are you?" in minimax is N tokens but N*4 in GLM)
English

@nahcrof Does the api and subscription plan both have same infra so technically speed would be same, as chutes has been slow and opencode go hits limit very fast
English
@oneabdulshakoor I have been looking into adding that model, I just don't wanna use more capacity than I can comfortably handle
English

@nahcrof Hey, was wondering if you wanted to consider eagle3 speculative decoding?
Generally, offers 3x throughput, without any quality loss. Could do 5x in rare cases.
As of now, I think k2.5 have a good eagle3 model in HF.
English