Sabitlenmiş Tweet
Darshan
768 posts


Darshan retweetledi

@kingofknowwhere Learn more about cute-dsl, you will be even more surprised
English

@maharshii would love to help out on the writing part if you are busy, looks like a great learning opportunity!
English

Recently, I have been diving deeper into torch compile internals especially for inference related graph optimizations with custom kernels and below are my findings/learnings:
Note that this is still a very high-level overview with lots of moving parts hidden behind the scenes. From what I understand the entire process of torch compile can be broken down into 5 stages.
1) Torch Dynamo: responsible for tracing the python bytecode and returning a fx GraphModule (gm). We can call it "functional graph module".
2) Pre-grad: this stage runs fx passes (both built-in and custom) on the gm before passing it to AOT autograd stage.
3) AOT autograd: this stage decomposes the unstable IR from dynamo+pre-grad stage into ATEN operations. ATEN is what pytorch uses behind the scenes. Ops like aten.addmm, aten.mul, and so on. It also builds and runs fx passes on the "joint" forward+backward graph if required (not necessary for inference only).
4) Post grad: this stage applies fx passes on the partitioned forward and backward graphs that come from AOT autograd stage.
5) Inductor codegen: this stage is still kinda a black box for me but I think it fuses ops in the graph, does autotuning, code generation and so on.
Within all these stages, we can ask the torch compile backend/inductor to apply our own fx passes using the "pre_grad_custom_pass", "joint_custom_pre_pass", "joint_custom_post_pass", "post_grad_custom_pre_pass", "post_grad_custom_post_pass" present in inductor's config. Here, we can edit the graph nodes (add, remove, update) to have custom fusions that inductor may not do for us. Try thinking of an example as an exercise :)
From a practical standpoint, if we wanted to have our own fx passes related to inference, the post grad pre passes (after AOT autograd, and before Inductor decomposition) is the best place to do it. At this point, we still have higher-level ATEN ops intact in the graph as nodes. For example, aten.addmm is not decomposed into aten .mm + aten.add here. To apply custom fx passes, we have two options:
> Pattern replacement: Inductor provides a nice helper that lets us define a pattern function and a replacement function using aten ops or custom torch ops. One caveat is that the pattern must be robust, even a small change and inductor won't replace it.
> Node surgery: We can search and edit the nodes in the graph directly. This is much more robust but it can get pretty hard for complex patterns.
This is not documented much but by leveraging what torch compile/inductor provides us, one can as much graph optimization as they want. Another thing that inductor provides us is, registering custom lowering for built-in aten ops but that is a whole another topic to discuss, maybe next time.

English

cuda, triton, cutlass, cute, tilelang, thunderkittens, mojo, helion.
so which one do you even learn at this point?
English
Darshan retweetledi

"post-AGI, no one is going to work and the economy is going to collapse"
"i am switching to polyphasic sleep because GPT-5.5 in codex is so good that i can't afford to be sleeping for such long stretches and miss out on working"
English
Darshan retweetledi

Darshan retweetledi


@dcbaslani/my-2-cents-on-doing-hard-things-9af575ae867b" target="_blank" rel="nofollow noopener">medium.com/@dcbaslani/my-…
ZXX
For 4 years, I thought doing hard things was the ultimate goal. It builds your ego and your skills. But in the real world, intellectual complexity ≠ business value.
I wrote about the painful realization of needing to swallow my pride and chase the low-hanging fruit.
Link below
English
Darshan retweetledi
Darshan retweetledi
Global aphasia is a condition where people lose almost all ability to use or understand language due to major damage in their brain's language network. Even without language, many of these patients can still solve complex reasoning problems, do math, understand cause and effect, and plan actions.
English
Darshan retweetledi

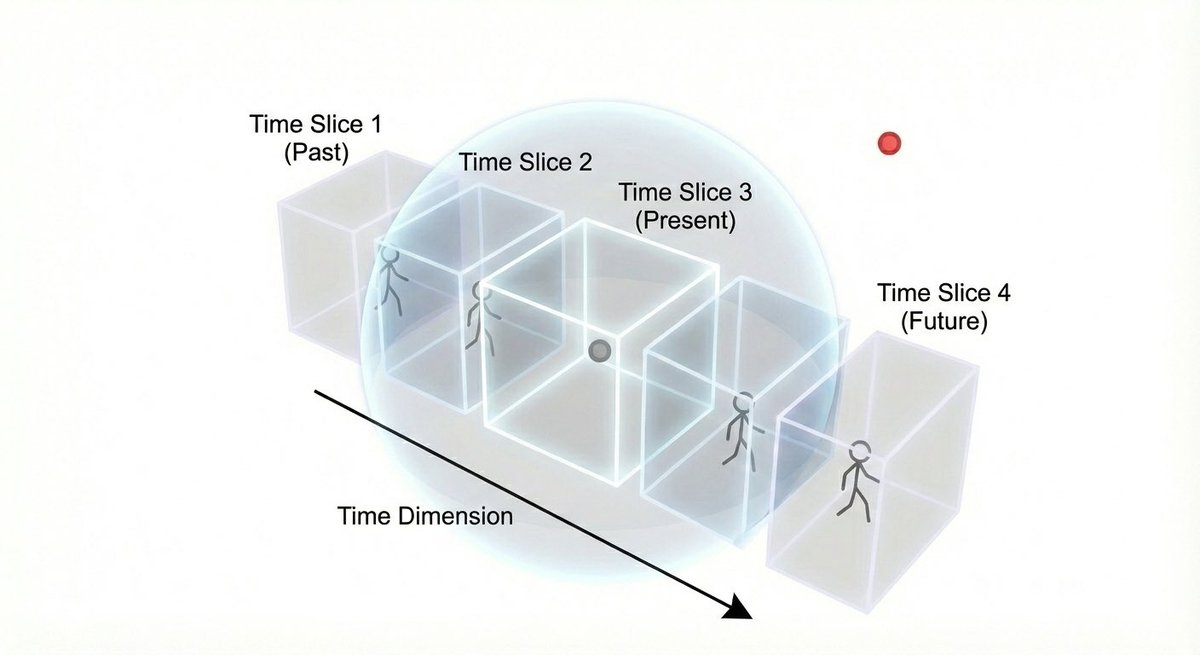
Consider a 5D observer;
looking at you, a 4D being
It would see the shape of your lifetime, all at once
Everywhere in space you were,
are and will be
In one grand arc
They could mold this shape
Like you,
a 4D being,
could reshape a stick figure on paper (2D+T=3D)
English